
Tous les champs relatifs à la science des données (data science en anglais), tels que le big data, l’intelligence artificielle, le machine learning…, sont très tendance actuellement dans notre économie.
Pour la majorité des gens, la récente popularité de toutes ces techniques témoigne probablement de la jeunesse de ce domaine. Pourtant, il n’en est rien : les premières recherches en intelligence artificielle remontent plus ou moins à l’apparition des ordinateurs au milieu du XXe siècle !
Voici un article/podcast intéressant qui revient sur la genèse de l’intelligence artificielle.
La réalité est qu’à l’époque, les verrous techniques étaient trop importants et depuis lors, les avancées dans ce domaine ont alterné entre des cycles de développement et de stagnation (appelés « hivers de l’IA »). Puis, au tournant des années 2010 a démarré un nouveau cycle de développement très soutenu et qui semble loin d’être fini.
Retour dans cet article sur les raisons de ce fort et durable engouement pour la data science durant la dernière décennie.
Des avancées techniques essentielles pour la data science
L’engouement récent pour la data science s’explique tout d’abord par des avancées techniques significatives dans plusieurs domaines.
L’explosion des volumes de données disponibles, notamment grâce à internet
Comme son nom l’indique, le carburant de la science des données, ce sont les données. Ces dernières sont essentielles et sont la priorité numéro 1 dans n’importe quel projet datas.
Les masses de données disponibles ont tout simplement explosé durant la dernière décennie et continuent de croître très fortement !
Cela s’explique par la digitalisation de l’ensemble de notre économie et la démocratisation d’internet. En effet, le nombre d’utilisateurs d’internet a fortement progressé et chaque nouvel utilisateur est une nouvelle source de données pour les géants du secteur.
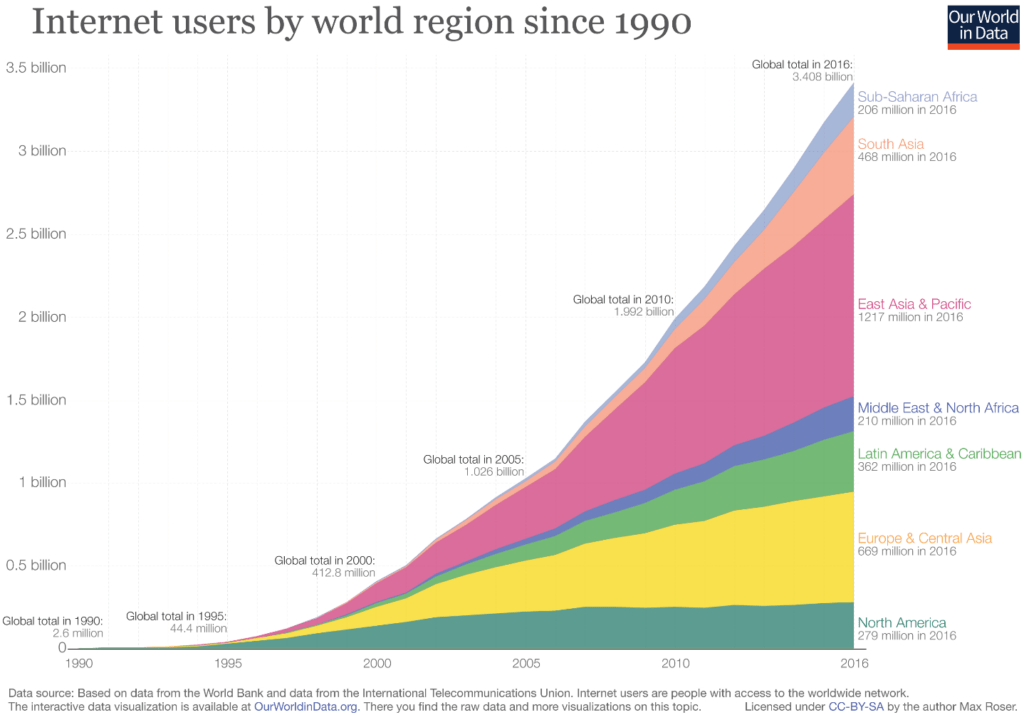
Un autre fait marquant de la décennie concerne le réveil des consciences vis-à-vis de la confidentialité et l’évolution de la législation en conséquence, avec l’apparition du RGPD, rentré en vigueur en 2018.
Suite à cela, certains sites adoptent aujourd’hui un modèle économique nouveau : payer une petite somme pour pouvoir accéder au contenu sans partager vos données personnelles.
La chute des coûts de calcul et de stockage concomitante au développement du cloud
Une autre avancée technique qui a permis le développement de la data science est la chute des coûts de stockage et de calculs informatiques.
Cette chute des coûts s’explique par deux phénomènes distincts :
- tout d’abord, les progrès techniques purs réalisés sur les puces, notamment les processeurs graphiques (GPU) ;
- mais aussi le développement du cloud, permettant de forte économie d’échelle, une optimisation des ressources disponibles et offrant la flexibilité d’une facturation « pay as you go » à leurs clients.
Des algorithmes de data science toujours plus performants
Enfin, une avancée technique durant ces dix dernières années qui concerne directement la data science est l’apparition d’algorithmes toujours plus performants.
Parmi eux, nous pouvons citer notamment :
- le développement du deep learning et l’apparition des réseaux convolutifs (CNN) très performants pour l’analyse d’images. Par exemple, des chercheurs ont développé un algorithme battant des docteurs pour le diagnostic de cancers du poumon à partir de résultats de radiologie ;
- AlphaGo, qui bat en 2017 le champion du monde de jeu de go, Ke Jie ;
- également en 2017 apparaît une nouvelle architecture de réseau de neurones appelée « Transformers ». Les performances de cette architecture sur des tâches NLP (Natural Language Processing = analyse du langage) ouvrent des horizons nouveaux, tel que des algorithmes capables de résumer un texte.
Un impact sur de nombreux secteurs de l’industrie
Concrètement, comment cela s’est-il traduit ?
Bien sûr, c’est souvent dans des entreprises du secteur IT que ces innovations digitales ont vu le jour. On les retrouve par exemple dans le traducteur automatique de Google, dans le moteur de recommandations de Netflix, ou chez Amazon pour créer des fiches clients détaillées automatiquement. Mais de nombreux autres secteurs se sont lancés aussi dans cette course !
Dans l’industrie, on parle beaucoup de « maintenance prédictive » par exemple, qui s’appuie sur des techniques de data science et permet d’anticiper une panne avant qu’elle se produise. Ainsi, la SNCF estime avoir réduit de 20 % ses coûts de maintenance sur les rames grâce à cette technique.
L’IA trouve de plus en plus d’applications, dans le milieu médical par exemple, notamment pour la réalisation de diagnostics, comme cité plus haut, ou encore dans l’agriculture, où l’analyse d’images prises par satellite ou par drone permet une utilisation très précise, et donc plus optimisée, de produits chimiques.
Une nouvelle décennie commence et des projets innovants dans le domaine de la data s’annoncent déjà prometteurs ! Vous l’aurez compris, il est difficile aujourd’hui de trouver un secteur de l’économie dans lequel l’IA n’a pas déjà fait quelques émules.
Ces avancées ont permis la création de nouvelles technologies, méthodes de travail & d’organisations ainsi que de postes de travail : le DataOps notamment !





