
Les données sont le carburant de tout projet data, elles conditionnent sa réussite ou son échec. De plus, l’extraction et le nettoyage des données représentent une part majeure du temps de travail pour les data scientists (environ 45 % selon une étude menée par Anaconda en 2020).
Pour ces raisons, il faut apporter une attention très particulière aux données que vous exploitez et donc également aux diverses sources de données utilisées.
Lister les sources de données dont vous disposez en amont d’un projet data peut vous aider à identifier les risques et les opportunités liés aux données.
Connaître les différentes sources de données à disposition
Les sources de données peuvent être classées selon différentes caractéristiques, pour pouvoir mieux les trier et les identifier.
Données internes vs externes
Une première caractéristique concerne la provenance des données : interne ou externe.
Les données internes sont celles que votre entreprise produit et possède (via le site web, les lignes de production, le service client, les données financières…).
C’est sûrement la première source à laquelle on pense spontanément et c’est aussi une source exclusive (vous seul y avez accès) qui peut donc vous donner un avantage significatif. Mais ce sont parfois des données confidentielles ou sensibles, qu’il faut alors utiliser avec précaution.
D’un autre côté, nous avons les données externes, divisées en deux sous-catégories :
- les données ouvertes et publiques (aussi appelées open-data), comme les données publiées par l’administration ;
- les données privées, mais accessibles (moyennant un paiement le plus souvent). C’est le cas de RAWG par exemple, proposant un accès freemium à une base de données relatives aux jeux vidéo.
Données structurées vs non structurées
Une deuxième caractéristique importante concerne les types de données : s’agit-il de données structurées ou non structurées ?
Les données structurées sont des données triées et organisées, ayant une structure fixe et identifiée. C’est le cas de la majorité des bases de données de type SQL, où chaque ligne correspond à une entité distincte (par exemple, des clients) et chaque colonne correspond à une propriété (par exemple, l’adresse postale ou la date de naissance). Ce sont des données « faciles » à exploiter, car nécessitant peu de traitement en amont.
Les données non structurées, par défaut, représentent tout le reste. C’est aussi la vaste majorité, puisque 80 % des données seront non structurées d’ici 2025 d’après une récente prévision.
Les données non structurées sont très diverses. Il peut s’agir d’images, de sons, de fichiers (des documents Word, par exemple), de texte libre (un tweet ou bien un rapport scientifique)…
Elles peuvent renfermer des informations précieuses, mais nécessitent beaucoup plus de travail. Souvent, ces données seront aussi plus bruitées. Donc les données structurées sont à privilégier, mais en tant que data scientist, vous avez rarement le luxe de choisir les sources de données auxquelles vous avez accès.
Données en direct ou en décalé
Enfin, une dernière caractéristique qui peut vous intéresser est la rapidité avec laquelle les données sont mises à jour.
En effet, il existe des sources de données qui sont mises à jour constamment, à l’image des cours boursiers, par exemple.
À l’inverse, certaines bases de données sont mises à jour de manière plus irrégulière, parfois quotidiennement, parfois à des intervalles de temps imprévisibles, ou parfois même jamais.
L’intégration des données, un défi technique et organisationnel
Une fois que vous avez identifié les sources de données à votre disposition, il faut réussir à les connecter entre elles pour créer un accès centralisé et uniformisé (et donc plus pratique pour vos équipes data).
La tendance actuelle est au data lake, qui présente l’avantage d’être très flexible et adapté à des données non structurées. Avec un tel système, vous pouvez intégrer des données dont vous n’avez pas anticipé la structure.
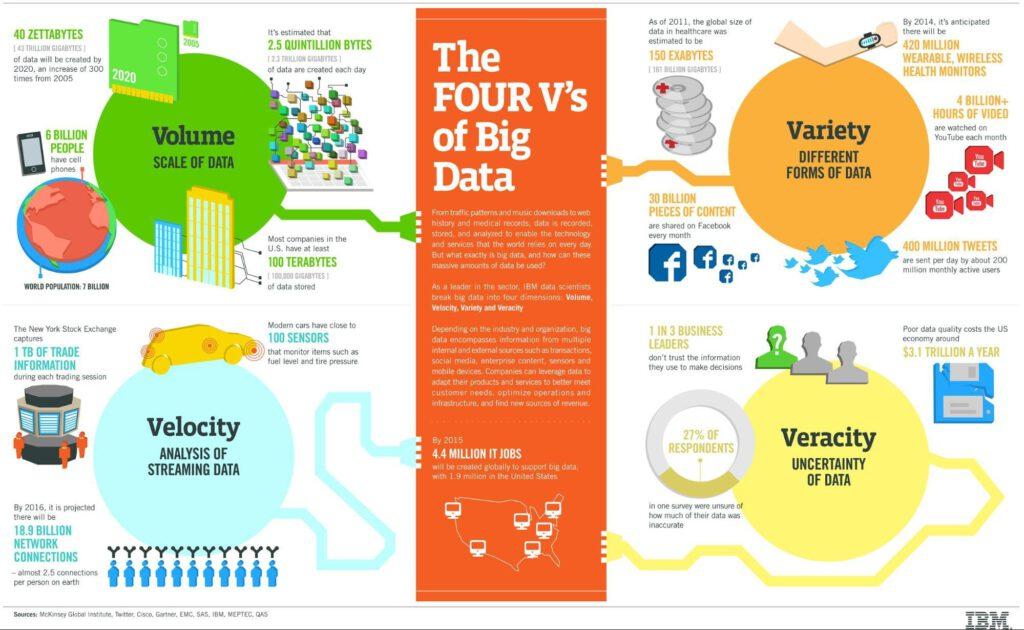
Le data lake est l’une des technologies clés du big data, qui caractérise des données dont le volume est trop grand pour être stocké sur un seul serveur et dont la structure peut être variable dans le temps, mais aussi d’une donnée à une autre.
Un point important pour réussir à intégrer les données est la mise en place de pipeline (notamment via l’approche « ETL »), ceci afin d’automatiser les étapes d’extraction, de nettoyage et de stockage vers le data lake. Il existe plusieurs outils dans ce domaine, comme Talend, spécialiste de l’intégration de données.
Pour conclure, il est important de noter que la mise en place d’un data lake n’est pas seulement un problème technique. En effet, cela soulève aussi des questions d’organisation et de process pour savoir quels sont les rôles et responsabilités de chacun (n’oublions pas que nous parlons de données potentiellement sensibles…).
Il est donc nécessaire de réfléchir en parallèle à ce qu’on appelle une « gouvernance des données », dont l’objectif est justement de formaliser la politique d’utilisation du data lake d’un point de vue opérationnel.





