
Les projets de machine learning se heurtent souvent à plusieurs obstacles : il existe une myriade d’outils différents pour couvrir chacune des étapes du projet, et il est difficile de suivre les paramètres de chaque expérimentation pour trouver ceux qui donnent les meilleurs résultats.
Pour résoudre ces problèmes, des plateformes telles que MLflow permettent d’enregistrer, organiser et réutiliser ces informations de manière efficace. Découvrez comment utiliser cet outil afin de monitorer l’ensemble de vos projets data.
Quelles sont les particularités de MLflow ?
MLflow est une plateforme open-source qui permet aux data scientists comme aux utilisateurs moins techniques de suivre les informations liées à l’entraînement et à la mise en production des modèles de machine learning. Tout en étant flexible et indépendante des librairies utilisées, elle s’intègre avec des frameworks reconnus en machine learning tels que Scikit-Learn, PyTorch ou encore TensorFlow. Dotée d’une API Python puissante et bien documentée, il est très facile d’ajouter MLflow à son projet sans avoir à repenser tout son code.
MLflow : Monitoring d'un projet ML
Quelques définitions pour plus de contexte:
- Un run est l’exécution individuelle d’un code (un code d’apprentissage par exemple). Chaque exécution va générer de nouveaux dossiers et fichiers, en fonction de ce que nous décidons d’enregistrer.
- Un experiment est le nom donné à un groupe de plusieurs exécutions.
MLflow peut être utilisé au sein de Saagie pour simplifier et clarifier la communication tout au long du cycle de vie d’un projet de machine learning. Afin d’avoir une démonstration complète, voyons l’usage qui peut en être fait dans le cadre d’un projet de détection de sentiments dans du texte.
1 – Entraînement et fine-tuning d’un modèle
Pour ce projet de détection de sentiments dans du texte, nous proposons de réutiliser un modèle de langage pré-entraîné et de l’affiner sur notre tâche de classification de sentiment. Pour ce faire, un script d’entraînement va télécharger depuis Hugging Face un modèle pré-entraîné, distilled-roberta-base, l’affiner pour notre tâche de détection de sentiments à l’aide d’un jeu de données annotés de sentiment, puis l’enregistrer sur un dépôt Hugging Face.
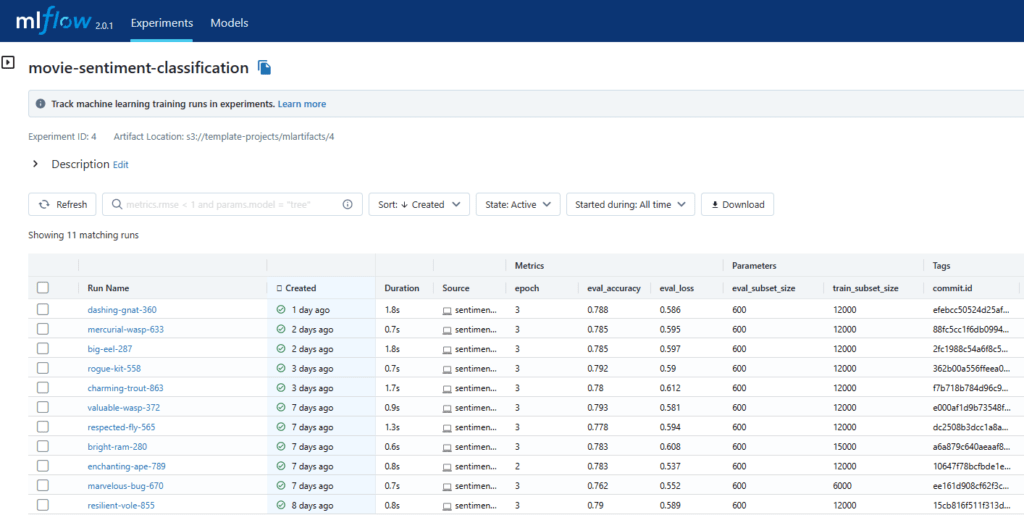
Nous regroupons les différentes exécutions de ce job au sein d’un même experiment. Lors de chaque run, nous demandons à MLflow d’enregistrer les hyper-paramètres choisis pour le fine-tuning, les métriques mesurant les performances du modèle, et des tags tels que l’identifiant du commit Hugging Face du modèle affiné.
Nous pouvons ensuite accéder à ces données de façon synthétique dans l’application MLflow installée sur Saagie.
2 - Déploiement du modèle
L’API Python de MLflow permet également de lui faire des requêtes. Nous utilisons cette fonctionnalité dans un script de déploiement pour récupérer le meilleur run au regard de la métrique qui nous intéresse. Nous pouvons ensuite retrouver le modèle correspondant sur Hugging Face grâce à son identifiant enregistré dans les tags du run, et le déployer sur Saagie.
mlflow.set_experiment('movie-sentiment-classification')
run = mlflow.search_runs(
run_view_type=ViewType.ACTIVE_ONLY,
max_results=1,
order_by=["metrics.eval_loss ASC"]
)
commit_id = run['tags.commit.id'].iloc[0]
Quelques lignes suffisent à trouver l’identifiant du meilleur modèle au regard de la fonction de perte.
3 - Monitoring d’un modèle en production
Afin de suivre les performances du modèle dans le temps, nous mettons en place un second experiment qui recueille les mesures de dérive (data drift) des données en production. MLflow permet d’enregistrer des artefacts liés aux runs, tels que des graphiques ou des matrices, afin d’illustrer les métriques sauvegardées.
Les utilisateurs, spécialistes ou non, peuvent ensuite utiliser les outils de visualisation intégrés de MLflow pour tracer des graphiques avec les données enregistrées, et identifier efficacement les éventuels problèmes que rencontre notre modèle en production.
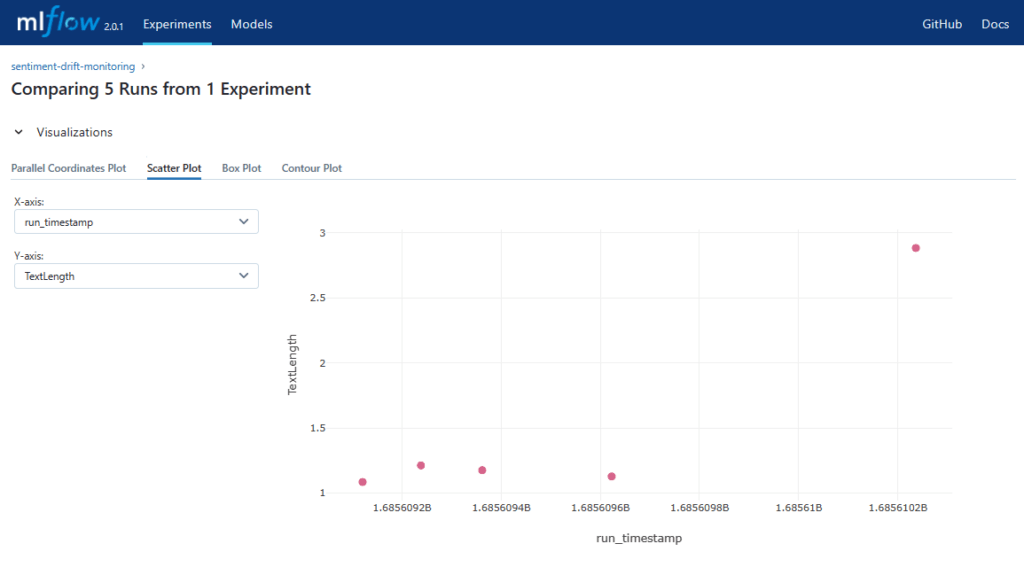
L’image ci-dessous présente par exemple la mesure de dérive de longueur des textes sur 5 jeux de données différents, en comparaison au jeu de données d’entraînement. Nous pouvons constater que la longueur des textes du dernier jeu de données est très différente de celle du jeu initial. Cela pourrait nécessiter de vérifier si le modèle actuellement déployé est encore pertinent et s’il ne faudrait pas réapprendre un modèle plus adapté.
Conclusion : une solution complète pour la gestion des projets de machine learning.
En résumé, MLflow facilite la communication et la collaboration tout au long du cycle de vie d’un projet de machine learning. En intégrant MLflow, Saagie offre aux utilisateurs un environnement complet pour gérer et surveiller leurs projets de machine learning. Il permet aux data scientists et aux utilisateurs non techniques de travailler plus efficacement et de prendre des décisions éclairées lors du développement et du déploiement de modèles de machine learning.





