
Applying methods from Agile software development to Data Science projects, is it only possible? This is a question we want to explore in this article. To set the scene, let’s consider the following cartoon as an example:
In this typical situation, the Data Scientist is excited and focused on improving the predictive power of his models while the business representative is struggling to understand the purpose of his work.
Most business people feel uncomfortable about Data Science.
- Is it the casual use of jargon by Data Scientists?
- Is it the library of technical math buzzwords that they use?
- Or is it that they have no clue on how to make money operationally with Data Science predictions!
Data science is a complex and probabilistic field. It is at the crossroad of business, science and IT. Together, they can play a pivotal role in solving real-world problems and deliver real value-added applications. And if we are not careful enough though, we can lose our bearing in a maze of algorithms, models, and new technologies.

The First Agile Methods
In 2001, agility emerged as a way to tackle complexity in software development. The same seems to be true for developing analytics applications. The main concepts in agile methods such as Iterate, Continuous Delivery, Fail Fast, Test & Learn and others help to bridge the gap between business people, data scientists and IT.
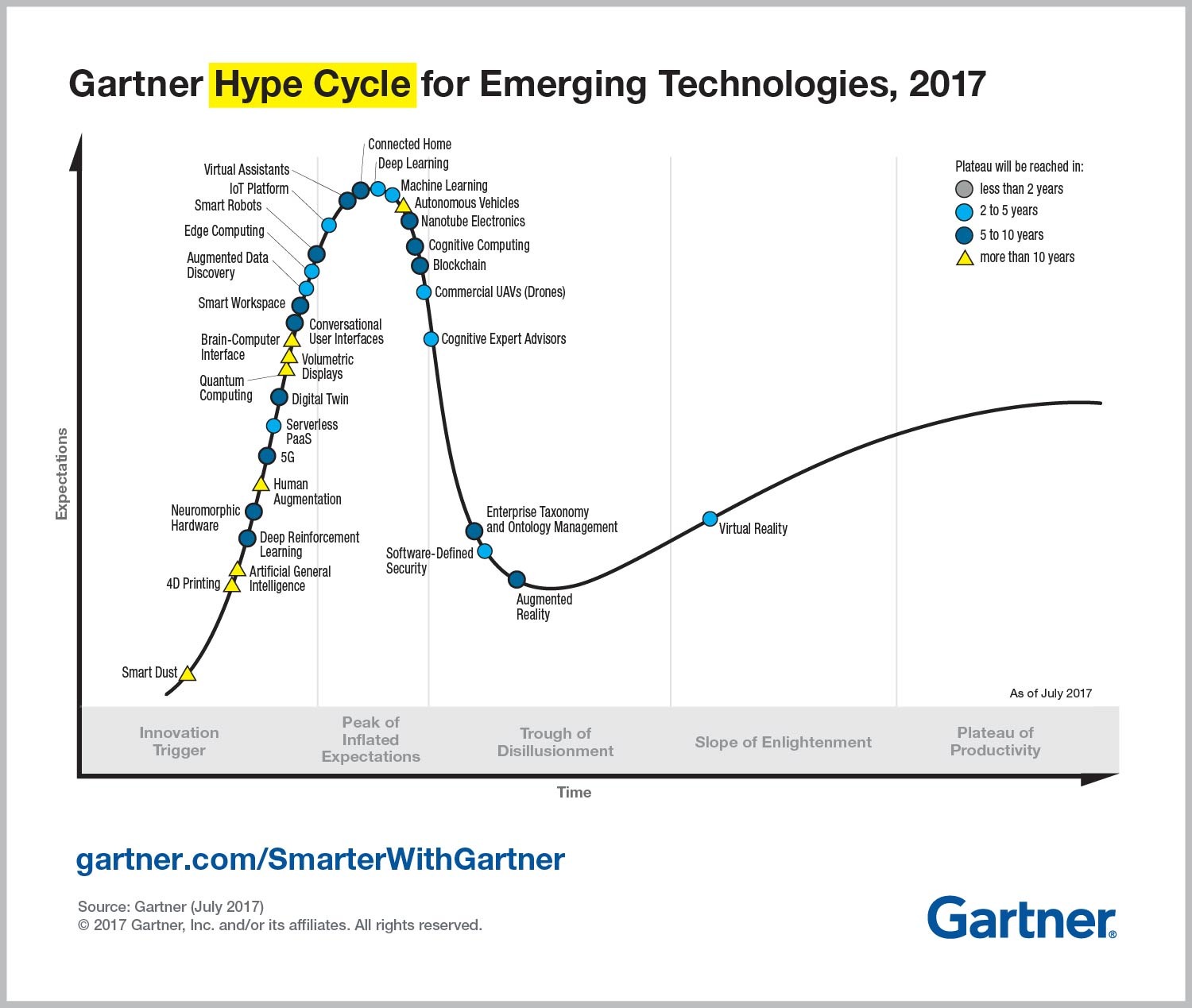
The Hype Cycle for Emerging Technologies
In 2017, Gartner published the hype cycle for emerging technology and positioned Deep Learning/Machine Learning at the peak, marked as 2–5 years away from the Plateau of Productivity. At that moment, it was necessary to find a way to go through Trough of disillusionment. That is where agile Data Science comes from. Today, agile Data Science is converging to a broader approach which is called DataOps.
DataOps is an agile methodology for developing and deploying data-intensive applications.
Data Maturity Assessment to Moving from a Data-Aware to a Data-Driven Organization
The level of data use and maturity in organizations varies from descriptive and diagnostic to predictive and prescriptive.
- Descriptive and diagnostic are back looking analytics. Typical examples are reports, dashboards, KPIs, Business Intelligence, root cause or event-driven analysis.
- Predictive and prescriptive are forward-looking analytics. You find statistical modeling, Machine Learning or Deep Learning models and more sophisticated AI models prescribing next best actions based on predictive models results.
What is really essential here is to acknowledge what is your starting point. A strong data foundation that is required to reach full data science maturity. Starting directly with advanced Analytics such as Machine Learning might be too ambitious, you need to build data foundations first:
- Build them fast if the scope is narrow,
- But build them strong so they will last.
You may create lots of value before reaching the Machine Learning level!
Now, let’s examine the transposition of some agile principles to Data Science.
Applying the Agile Manifesto Principles to Data Science
In software development, the Agile Manifesto provides keys to “uncover better ways of developing software (…).”; In short, the Agile Manifesto is based on four values and twelve principles. And there are countless ways of practicing it.
Agile Data Science focuses on how to think rather than on what to do.
Principle 1: “Customer’s satisfaction is our highest priority…”
The practice you might apply is to use business language and metrics to evaluate models. When talking with business people, do not use technical metrics but use business KPIs or data visualization. If you miss data to convert to €, start collecting it.
Principle 2: “Business people and developers must work together daily throughout the project.”
Here it might be interesting to try a hybrid organizational model with small cross-functional teams that we have described in this article.
Principle 3. “Simplicity –the art of maximizing the amount of work not done — is essential.”
The advice is to try first with simple data and model to validate the hypothesis and to get feedback quickly.
Principle 4: “… early and continuous delivery of valuable software.”
Iteration is essential in crafting analytics applications. Go fast to the pilot phase and divide your work into sprints that add values.
- Sprint is a set chunk of time to work on tasks, typically two weeks, with the goal of producing new results.
- At any given task, you must iterate to achieve insight, new feature, hypothesis validation or model result.
Principle 5: “At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behaviour accordingly.”
There is a myriad of practices around continuous improvement: retrospective meeting from Scrum or Stop-Start-Continue dashboard.
Principle 6: “The best and effective method of sending information (…) is face-to-face conversation.”
Communication is the key. Cadence iterations with communication ceremonials: 10 minutes team synchronization, planning, daily stand-up, demonstration, 1-2 hours meeting with stakeholders, retrospective. All these mentioned practices and many others work together to drive Agile data science and allow to achieve exploratory data analysis and transform it into analytics applications.
At Saagie, we consider agile Data Science as a key component of the DataOps approach to deliver success with Data & Analytics projects. We strongly support the DataOps adoption within organizations, and this is the reason why our product has been designed as a Plug and Play orchestrator for DataOps: users can build their data pipelines by combining pre-integrated open-source components and commercial technologies, and fully operate those pipelines with versioning, rollback and monitoring capabilities so they can embrace CI/CD practices.




