
Il est devenu impossible de parler de Data sans mentionner l’open source. Il vous suffit de jeter un œil aux différentes plateformes data science qui proposent des solutions Big Data.
Pour cause, les meilleurs outils tels que Cassandra, Hadoop, Apache Spark, Talend offrent désormais des services open source de grande qualité en ce qui concerne la construction de projets Data Science et sont donc rapidement devenus les choix les plus adoptés par les entreprises. Découvrez donc ce qu’est l’open source et la raison de son avènement dans le domaine du big data.
Définition du concept d’open source
Commençons par les bases avec un rappel de la définition de l’open source. L’open source a démarré dans les années 1990 et a depuis connu énormément d’évolutions. Wikipédia le décrit ainsi :
« open source, ou code source ouvert, s’applique aux logiciels dont la licence respecte des critères précisément établis par l’Open Source Initiative, c’est-à-dire les possibilités de libre redistribution, d’accès au code source et de création de travaux dérivés. »
Mais l’essence même d’un outil open source va bien plus loin qu’un simple accès au code source d’un logiciel.
Open source vs outil propriétaire
Contrairement aux outils propriétaires, l’open source est un modèle dans sa conception même. Il s’agit de personnes qui ont collaboré pour un objectif, celui de construire un outil qui pourra servir à tous. Cela montre la capacité des gens à coopérer dans un but commun, pour lequel ils ne tirent pas forcément de bénéfices personnels.
Pour y voir plus clair et faire son choix entre un outil open source et un modèle d’outil propriétaire, intéressons-nous à leurs principales différences :
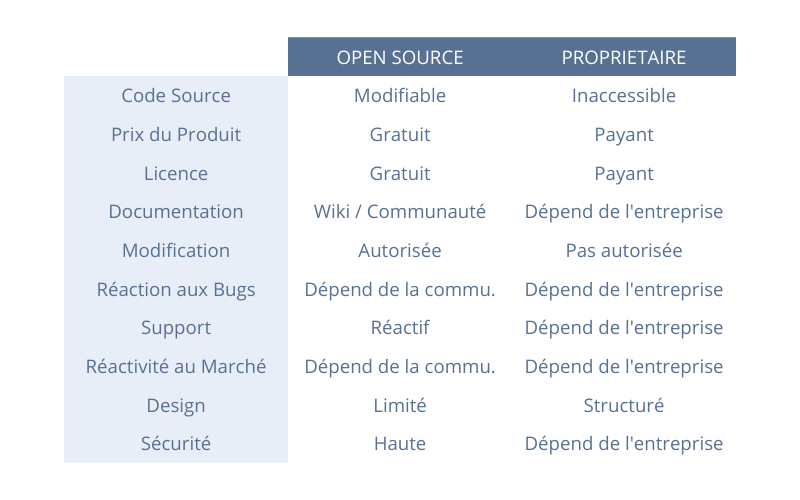
Les grands principes de l’open source et sa culture
Retournons donc à l’utilisation de l’open source en nous penchant sur ses grands principes.
- La collaboration : dans le contexte de l’open ou de l’inner source, elle ne connaît pas de frontières. La gestion des données est faite par les développeurs du monde entier qui partagent leur data sur le web, à une audience large et non seulement avec leur manager ou leur équipe. Tout le monde est le bienvenu et les décisions sont basées sur le mérite et non imposées.
- La communication : elle est écrite et ouverte à tous. Le but est que chacun puisse accéder aux ressources et informations sur les projets open source et y contribuer, sans contrainte de formation préalable.
- Le gage de qualité : cela consiste à mettre en place des processus visant à assurer un niveau de qualité. Le code et les données sont disponibles pour tous et par conséquent, optimisés, testés et vérifiés par des centaines si ce n’est des milliers d’utilisateurs.
Ce qu’on appelle « inner source » n’a de différent que le fait qu’il ne s’applique qu’au sein même de l’entreprise. La notion d’ouverture n’est pas perdue, mais ne s’étend ici qu’à l’ensemble des équipes, ce qui permet à la société de profiter de la créativité et des idées de ses salariés sans pour autant compromettre l’aspect privé de son activité.
La technologie open source
Il n’y a pas que chez Saagie que nous croyons en l’open source. De nombreux spécialistes comme le créateur de Kafka Jay Kreps, désormais chez Confluent, ou Mike Tuchen, ancien CEO de Talend, voient le futur du Big Data dans les outils open source.
L’open source est presque devenu le choix par défaut dans certains domaines comme le « Big Data stores », la Data Science avancée ou encore les langages et frameworks liés au Machine Learning.
Les logiciels et outils open source ont toujours été en compétition avec les logiciels dits propriétaires, qui ont le désavantage du « lock in », c’est-à-dire la difficulté de changer d’outil lorsque vous le souhaitez.
Le livre blanc d’Ovum souligne ce risque et conclut que la pratique la plus adaptée pour les entreprises serait une version hybride avec le bon équilibre entre les fonctionnalités d’un outil open source et d’un outil propriétaire. De nombreuses entreprises se disent d’ailleurs prêtes à se tourner vers l’open source, à condition d’avoir une plateforme à la hauteur.
Pourquoi l’open source a-t-il le vent en poupe ?
L’open source est plus qu’une tendance, c’est désormais indéniable, et ne touche plus uniquement le développement de logiciels. Cela ouvre les perspectives d’une société portée l’open data, sur la collaboration et la transparence des informations, un sujet au cœur des problématiques de nos sociétés actuelles.
Le critère des prix
La première raison de choisir l’open source – et la plus évidente – est son coût, puisqu’il est nul. L’open source est, par essence, gratuit. Il n’y a pas de coûts de licence, d’abonnement, ni de copyright lié au code source. L’entreprise peut donc réduire de façon significative ses dépenses, mais aussi le temps passé pour sortir un produit.
Moins vous dépensez en temps et coûts sur votre produit, plus vous faites économiser à vos clients.
Plus vous économisez en temps et en coûts, moins le prix de votre produit sera élevé.
Toutefois, même si l’open source peut sembler complètement gratuit, il implique tout de même des coûts liés à l’intégration aux outils, au support et aux différentes mises à jour. Ces quelques contraintes sont souvent gérées par l’IT ou via des souscriptions annuelles mises en place par les fournisseurs de ces technologies eux-mêmes. Selon la maturité de vos projets open source, des coûts de gestion de la sécurité ou de mise à l’échelle peuvent s’ajouter.
Malgré ces quelques contraintes, son coût reste donc le premier avantage de l’open source. Au-delà de cet enjeu, d’autres raisons pourront cependant vous amener à vous tourner vers l’open source.
L’accès à une large communauté
Il y a derrière chaque technologie open source une communauté d’utilisateurs unie autour d’un objectif, celui d’arriver à la solution la plus performante, fonctionnelle, fiable et sécurisée version après version.
Les développeurs de ces communautés sont passionnés par ce qu’ils font et sont motivés par la reconnaissance que les autres membres montrent envers leur travail. Les solutions big data qui en résultent – même s’ils passent moins de temps à les développer – sont donc souvent de meilleure qualité.
Par exemple, la librairie Python scikit-learn est gratuite et utilisée partout dans le monde pour répondre à des problématiques de Machine Learning, d’analyse des données et de Big Data. Elle offre un large choix d’algorithmes pré-packagés qui font le bonheur de nombreux projets de Data Science avec de grands ensembles de données. Lancée en 2007 comme un projet de stage d’été de Google par David Cournapeau, la librairie telle qu’on la connaît aujourd’hui est le fruit de nombreuses heures de travail de la communauté pour permettre aux utilisateurs une bonne gestion et analyse de leurs données.
La liberté
L’une des différences de l’open source, c’est aussi qu’on peut décider de changer de technologies quand bon nous semble.
Un autre avantage est le fait de pouvoir « construire » directement sur le travail des autres puisqu’on a accès à l’architecture de la solution en question. On peut donc réutiliser du code et économiser du temps de recherche, des compétences et donc à nouveau, en coûts.
La réactivité de la plateforme
Grâce à la taille des différentes communautés présentes sur le web, il est facile de trouver une solution à son problème puisque de nombreux outils, plugins ou morceaux de codes y sont disponibles. Il n’y a plus à attendre l’annonce d’une release pour ajouter ou avoir accès à de nouvelles fonctionnalités.
De plus, il n’est pas rare de vouloir ou d’avoir besoin de nouvelles fonctionnalités et de se rendre compte qu’elles existent déjà.
Cependant, certains se plaignent encore du fait qu’il n’y a pas de numéro à appeler en cas de problème ou pour poser une question. Même si les technologies open source profitent d’un accès important à de la documentation, des wikis, des forums ainsi que de communautés actives autour du big data et de la science des données, il est toujours possible d’opter pour le support payant. Ce type de support peut s’avérer plus personnalisé et pourra donc répondre plus rapidement en cas de besoins précis.
Il est maintenant temps de jeter un œil aux langages de programmation open source Python et R, qui sont très utilisés en Data Science, Big Data, analyse et traitement de données et s’intéresser à leurs différences majeures.
Quel langage de programmation choisir lorsqu’on se lance dans un projet Data Science ?
Python et R sont des langages gratuits dont le code est entièrement basé sur la communauté.
L’utilisation de ces deux langages est très répandue parmi les data scientists, les développeurs Big Data et les data miners. Python a été élu langage de l’année dans l’index Tiobe (un indicateur de popularité des langages de programmation) et R est classé à la 12e place.
Python
Python aide à être productif et avoir un code lisible. Il est plus apprécié des ingénieurs Big Data qui ont davantage de contraintes de déploiement. Son adoption en machine learning est très importante.
« Ceux qui travaillent dans un environnement proche de l’ingénierie auront tendance à préférer Python. »
R
Ce langage se concentre sur l’analyse de données, les statistiques et les modèles graphiques et se présente comme user friendly. Il est très apprécié par les universitaires et les chercheurs en Big Data, mais aussi de plus en plus par les statisticiens pour l’analyse des données.
« Plus vous êtes proche des statistiques, de la recherche et de la Data Science, plus vous irez vers R. » (Theuwissen)
Chez Saagie, nous avons opté pour le choix de l’open source. Notre solution a été conçue pour intégrer le plus large panel de technologies open source possible (R et Python dont nous avons parlé, mais aussi Spark ou Scala, et bien d’autres !), toujours mises à jour afin de développer et déployer facilement des applications à l’usage des métiers de la data science (analyse et traitement de données, Machine Learning, Big Data…).





