
Les premiers résultats lorsque l’on recherche « Intelligence artificielle dans les jeux vidéo » dans Google parlent d’eux-mêmes : l’Intelligence Artificielle (IA) dans les jeux vidéo n’est souvent pas satisfaisante. En tant que joueur, il est d’ailleurs fréquent de se retrouver face à des situations qui perdent en crédibilité du fait du comportement de l’IA. Est-ce un vrai problème ? Pourquoi l’IA semble stagner dans les jeux vidéo alors que le reste (graphismes, complexité, gameplay…..) s’améliore continuellement ? Alors que de plus en plus d’IAs sont capables de se mesurer à l’Homme sur des jeux de plateau (échecs, Go) mais aussi plus récemment de stratégie (Dota 2), pourquoi semblent-elles inlassablement se coincer dans le décor ou nous répéter les mêmes tirades lorsque nous jouons ? C’est ce que nous allons essayer d’étudier dans ce dossier complet.
État des lieux et historique
Intelligence artificielle et jeux de plateaux comme les échecs ou le Go ont toujours été liés depuis l’émergence de la discipline. En effet, ceux-ci fournissent un terrain propice afin d’évaluer les différentes méthodes et algorithmes d’IA développés. Quand les premiers jeux vidéo ont fait leur apparition, la recherche en IA battait son plein. C’est donc logiquement que l’intérêt a été porté à ce nouveau support. Cependant et pendant longtemps, la recherche a surtout permis l’amélioration des jeux vidéo et non l’inverse.

Le but principal de l’IA dans un jeu vidéo est de rendre le monde dépeint par le jeu le plus cohérent et le plus humain possible afin d’améliorer le plaisir et l’immersion du joueur. Cet objectif de recréer un monde au plus proche du réel peut passer par beaucoup d’approches différentes comme améliorer le comportement des personnages non joueurs (PNJs) ou encore générer du contenu de façon automatique.A l’instar des jeux de plateau, les premiers jeux vidéo présentaient souvent une confrontation entre deux joueurs (comme Pong en 1972). Puisque deux joueurs s’affrontaient, aucune IA n’était donc nécessaire dans ce type de jeu. Mais rapidement, les jeux se complexifient et de nombreux éléments commencent à présenter des comportements indépendants des actions du joueur rendant le jeu plus interactif, comme les fantômes dans Pac Man.
Il devient donc rapidement nécessaire d’implémenter de l’IA dans les jeux vidéo pour être capable de générer ce genre de comportements. Depuis, IA et jeux vidéo sont irrémédiablement liés, l’IA ayant pris une place de plus en plus importante dans les systèmes de jeu.
Désormais, quel que soit le type de jeux vidéo (jeux de course, jeux de stratégie, jeux de rôle, jeux de plateforme, etc ..), il y a de grandes chances pour que de nombreux éléments du jeu soient gérés par des algorithmes d’IA. Cependant cette forte imbrication entre IA et système de jeu ne s’est pas toujours faite sans accroc et, même aujourd’hui, certaines intégrations sont déficientes.
IA et jeux vidéo, faux frères ?
Au commencement du domaine, il y a longtemps eu un fossé entre la recherche en IA classique et l’IA effectivement implémentée par les développeurs dans les jeux vidéo. En effet, il existait entre les deux des différences majeures dans les connaissances, les problématiques rencontrées mais aussi les façons de résoudre ces problématiques. La principale raison derrière ces différences provient sans doute du fait que ces deux approches de l’IA n’ont pas vraiment les mêmes objectifs.
La recherche en IA classique aspire en général à améliorer ou créer de nouveaux algorithmes pour faire avancer l’état de l’art. En revanche, le développement d’une IA dans un jeu vidéo a pour objectif de créer un système cohérent qui s’intègre le mieux possible dans le design du jeu afin d’être amusant pour le joueur. Ainsi, une IA très performante qui n’est pas bien intégrée au gameplay peut davantage desservir le jeu qu’elle ne va l’améliorer.
Développer une IA pour un jeu vidéo requiert donc souvent de trouver des solutions d’ingénierie à des problèmes peu ou pas du tout adressés par la recherche classique en IA. Par exemple, un algorithme d’IA dans un jeu est très fortement contraint en matière de puissance de calcul, de mémoire et de temps d’exécution. En effet, le jeu doit tourner par le biais d’une console ou d’un ordinateur “ordinaire” et il ne doit pas être ralenti par l’IA. C’est pourquoi certaines solutions de l’état de l’art en IA gourmandes en ressources n’ont pu être implémentées dans les jeux vidéo que plusieurs années après leur utilisation en IA classique.
Les solutions possibles pour résoudre un problème donné sont aussi une distinction entre les deux domaines. Par exemple, il est souvent possible de contourner une problématique difficile d’IA en modifiant légèrement la conception du jeu. De plus, dans un jeu vidéo, une IA peut se permettre de tricher (en ayant accès à des informations qu’elle n’est pas censée avoir, ou en ayant plus de possibilités que le joueur par exemple) afin de compenser son manque de performance. La triche d’une IA en soi n’est pas un problème tant qu’elle permet d’améliorer l’expérience du joueur. Cependant, en général, il est difficile de bien dissimuler le fait que l’IA triche et cela peut entraîner de la frustration pour le joueur.

On peut noter que la plupart des grands concepts de jeux vidéo (Jeux de course, de plateforme, de stratégie, de tir, etc…) ont été créés autour des années 80 et 90. À cette époque, le développement d’une IA complexe dans un jeu était quelque chose de difficilement réalisable au vu des ressources et méthodes existantes. Les concepteurs de jeux de l’époque ont donc souvent dû composer avec le manque d’IA en faisant des choix adaptés de Game Design. Certains jeux ont même été pensés pour ne pas avoir besoin d’IA. Ces conceptions basiques ont été héritées par les différentes générations de jeux vidéo qui, pour beaucoup, restent assez fidèles aux canons du genre qui fonctionnent. Ceci peut donc aussi expliquer pourquoi les systèmes d’IA dans les jeux vidéo sont en général assez basiques quand on les compare aux approches de la recherche classique.
Ainsi, les méthodes que nous allons présenter pourraient surprendre par leur relative simplicité. En effet, lorsque l’on entend parler d’IA aujourd’hui, cela fait référence au Deep Learning et donc aux réseaux de neurones très complexes et abstraits. Cependant, le Deep Learning n’est qu’un sous domaine de l’IA, et les méthodes symboliques ont été les approches communément utilisées pendant longtemps. On fait référence aujourd’hui à ces approches avec le nom GOFAI (« Good Old-Fashioned Artificial Intelligence » ou “bonne vieille IA démodée” en français). Comme son surnom l’indique, l’IA symbolique n’est clairement plus l’approche la plus populaire mais elle permet cependant de résoudre de nombreux problèmes, notamment dans le cadre du jeu vidéo.
L’IA pour les jeux vidéo
Le critère principal de succès d’une IA dans un jeu classique est probablement son niveau d’intégration et d’imbrication dans le design du jeu. Par exemple, des PNJs ayant un comportement injustifiable peuvent briser l’expérience de jeu prévue et donc l’immersion du joueur.

L’un des exemples les plus classiques dans les vieux jeux est le cas où les Personnages Non Joueurs (PNJs) se retrouvent coincés dans le décor. À l’inverse, une IA qui participe pleinement à l’expérience de jeu aura forcément un impact positif sur le ressenti du joueur, en parti parce que les joueurs sont plus ou moins habitués aux comportements parfois incohérents des IA.
Suivant le type de jeu, une IA peut avoir des tâches très variées à résoudre. Nous n’allons donc pas nous pencher sur l’ensemble des cas d’utilisation possibles d’une IA dans un jeu mais plutôt sur les principaux. Il s’agira donc notamment de la gestion du comportement des PNJs (alliés ou ennemis) dans les jeux de tir ou les jeux de rôle, ainsi que de la gestion plus haut niveau d’un agent qui doit jouer à un jeu de stratégie.
Le contrôle des PNJs
Il existe un grand nombre d’approches permettant de développer des comportements réalistes dans un jeu vidéo. Cependant, le côté réaliste ne suffit pas à rendre un jeu amusant. En effet, il ne faut pas oublier que la finalité d’un ennemi dans un jeu reste en général de se faire éliminer par le joueur. Un jeu avec des adversaires trop réalistes ne sera pas forcément agréable à jouer. Par exemple, des PNJs qui passent leur temps à fuir risquent d’agacer le joueur plus qu’autre chose. Il y a donc un compromis à trouver dans le comportement des PNJs qu’il n’est pas forcément facile à balancer.
Dans cette partie, nous allons faire un tour d’horizon des solutions principales pour essayer de résoudre cette problématique. Mais pour commencer, faisons le point sur quelques notions importantes.
Les agents
Probablement la notion première lorsque l’on parle d’Intelligence artificielle pour les jeux vidéo, un agent est une entité qui peut obtenir des informations sur son environnement et prendre des décisions en fonction de ces informations dans le but d’atteindre un objectif. Dans un jeu vidéo, un agent représente souvent un PNJ, mais il peut aussi représenter un système plus complet comme un adversaire dans un jeu de stratégie. Il peut donc y avoir plusieurs niveaux d’agents qui communiquent entre eux dans un même jeu.
Les états
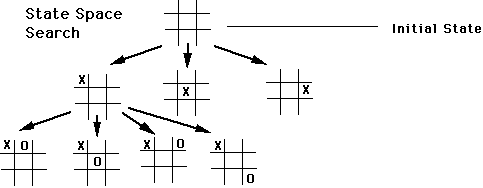
Un état est une configuration unique de l’environnement dans lequel un agent se trouve. L’état peut changer quand un agent (ou le joueur) effectue une action. Pour un agent, l’ensemble des états possibles s’appelle l’espace des états (state space en anglais). C’est une notion importante puisque l’idée de base de la plupart des méthodes d’IA est de parcourir ou d’explorer l’espace des états pour trouver la meilleure façon d’agir en fonction de la situation présente. Les caractéristiques de l’espace des états impactent donc la nature des méthodes d’IA utilisables.
Si l’on considère par exemple un agent qui définit le comportement d’un PNJ, l’espace des états peut être défini de façon assez simple : il s’agit de l’ensemble des situations dans lequel le PNJ peut se trouver. On peut ainsi mettre en place un état dans lequel le PNJ ne voit pas le joueur, un état dans lequel il voit le joueur, un état lorsque le joueur tire sur le PNJ et un état quand le PNJ est blessé. En considérant ainsi l’ensemble des situations possibles pour le PNJ, on peut déterminer les actions qu’il peut entreprendre ainsi que les conséquences de ces actions en terme de changement d’état (on parcourt l’espace des états facilement). On peut donc intégralement définir le comportement de l’agent et choisir les actions les plus pertinentes à chaque instant en fonction de ce qui se passe.
A l’inverse, dans le cas d’un agent qui joue à un jeu comme les échecs, l’espace des états sera l’ensemble des configurations possibles des pièces sur le plateau de jeu. Cela représente un nombre de situations extrêmement grand (10^47 états pour les échecs). Dans ces conditions, Il n’est plus possible d’explorer toutes les possibilités. Par conséquent, on ne peut plus déterminer les conséquences des actions de l’agent et donc de juger de la pertinence de ses actions. On est donc forcé d’oublier les approches manuelles et de s’orienter sur d’autres méthodes plus complexes (que l’on abordera plus tard).
La recherche de chemin
Avant de pouvoir modéliser le comportement d’un PNJ en explorant l’espace des états, il faut définir comment celui ci peut interagir avec son environnement et notamment, comment il peut se déplacer dans le monde du jeu. La recherche de chemin (pathfinding), qui est le fait de trouver le plus court chemin entre un point A et un point B, est donc souvent l’une des briques de base d’un système d’IA complexe. Si cette brique est défaillante, tout le système en pâtira. En effet, des PNJs ayant un pathfinding défaillant risquent de se coincer dans le décor et donc d’impacter négativement l’immersion du joueur.
L’algorithme le plus utilisé pour le pathfinding est l’algorithme A*. Il s’agit d’une version plus rapide d’un algorithme plus ancien, l’algorithme de Dijkstra. Tous deux sont ce que l’on nomme des algorithmes de parcours de graphe. Pour utiliser ces algorithmes dans un jeu vidéo, le terrain de jeu (qui prend en compte les éventuels obstacles et parties cachées) est modélisé sur une grille en 2 dimensions (une grille est une forme de graphe). L’algorithme va s’exécuter dans cette grille 2D.

Le principe de Dijkstra est relativement simple, il va parcourir dans l’ordre chaque case de la grille en fonction de sa distance avec la case de départ jusqu’à trouver la case de destination.
On peut voir avec le schéma ci-dessus que l’algorithme a parcouru toutes les cases bleues avant de trouver la case violette de destination. Cet algorithme trouvera toujours le meilleur chemin mais il est lent puisqu’il parcourt un grand nombre de cases.
Là où Dijkstra trouve toujours la solution optimale, A* peut ne trouver qu’une solution approchée. Cependant, il le fera beaucoup plus rapidement, ce qui est un point critique dans un jeu vidéo. En plus d’avoir l’information de distance entre chaque case avec la case de départ, l’algorithme calcule approximativement la direction générale dans laquelle il doit aller pour se rapprocher de la destination. Il va ainsi chercher à parcourir le graphe en se rapprochant toujours de l’objectif, ce qui permet de trouver une solution bien plus rapidement.

Dans des cas plus complexes où l’algorithme rencontre un obstacle, il repartira du début pour trouver un autre chemin qui se rapproche de la destination mais en évitant l’obstacle.
Pour les jeux plus récents en trois dimensions, le monde n’est pas représenté par une grille mais par un équivalent en 3D que l’on appelle un maillage de navigation. Un maillage de navigation est une simplification du monde qui ne considère que les zones dans lesquels il est possible de se déplacer afin de faciliter le travail de l’algorithme de pathfinding. Le principe de recherche de chemin reste le même.
Ces algorithmes de parcours de graphe peuvent sembler simples et l’on peut se demander s’il s’agit vraiment d’IA. Il faut savoir qu’une bonne partie de l’IA peut se réduire finalement à des algorithmes de recherche. Cette sensation qu’un problème résolu par IA n’était finalement pas si compliqué s’appelle l’effet IA.

Mais pour ce qui est de la recherche de chemin, ce n’est pas un problème si simple, et des chercheurs s’y intéressent toujours. Par exemple en 2012, une alternative à l’algorithme A* a été développée : la méthode Jump Point Search (JPS). Elle permet, lors de la recherche dans certaines conditions, de sauter plusieurs cases d’un coup et ainsi de gagner du temps par rapport à A* qui ne peut chercher son chemin que case par case.
Les implémentations de pathfinding dans les jeux vidéo sont aujourd’hui souvent des variations de A* ou de JPS, adaptées aux problématiques spécifiques de chaque jeu.
Le pathfinding est une composante importante d’un système comportemental des PNJs. Il y en a d’autres comme par exemple la gestion de la ligne de vue (Les PNJs ne doivent pas voir dans leur dos, ni à travers les murs) ou encore les interactions avec l’environnement qui sont nécessaires avant de pouvoir implémenter un comportement cohérent. Mais puisqu’elles ne sont, en général, pas gérées par de l’IA, nous n’allons pas nous attarder davantage dessus. Il ne faut cependant pas oublier que le système final nécessite toutes ces briques pour fonctionner. Une fois que notre PNJ est capable de se déplacer et d’interagir, on peut développer son comportement.

La création de comportements Ad-hoc
La création de comportements Ad-hoc (Ad hoc behaviour authoring en anglais) est probablement la classe de méthode la plus courante pour implémenter de l’IA dans un jeu vidéo. Le terme même d’IA dans les jeux vidéo fait encore aujourd’hui surtout référence à cette approche. Les méthodes Ad Hoc sont des systèmes experts, c’est-à-dire des systèmes où l’on doit définir manuellement un ensemble de règles qui vont servir à définir le comportement de l’IA. Ce sont donc des méthodes manuelles de parcours de l’espace des états. Leur application est donc limitée aux agents confrontés à un nombre de situations possibles assez restreint, ce qui est en général le cas pour les PNJs. Contrairement aux algorithmes de recherche comme A*, les méthodes ad-hoc ne peuvent peut-être pas réellement être définies comme de l’IA classique, mais elles sont considérées comme telles par l’industrie du jeu vidéo depuis son commencement.
Les automates finis (Finite State Machine)
Un automate fini permet de manuellement définir les objectifs et les stimuli d’un agent afin de dicter son comportement. Pour chaque objectif, on définit un ou des états et chaque état dicte une ou des actions pour le PNJ. En fonction d’événements extérieurs ou de stimuli, l’objectif du PNJ peut changer et donc l’automate peut transitionner d’un état à un autre.
Un automate fini est donc simplement un moyen de représenter l’espace des états d’un agent ainsi que l’ensemble des transitions entre ses différents états. Si les états et les transitions sont bien définis, l’agent présentera un comportement pertinent dans toutes les situations. Les automates finis sont en général représentés sous la forme d’un diagramme de flux comme l’exemple ci-dessous.
L’avantage principal des automates finis est qu’ils permettent de modéliser un comportement pertinent assez simplement et rapidement puisqu’il suffit de définir manuellement les règles qui définissent les différents états et transitions. Ils sont aussi pratiques puisqu’ils permettent de voir visuellement comment peut se comporter un PNJ.
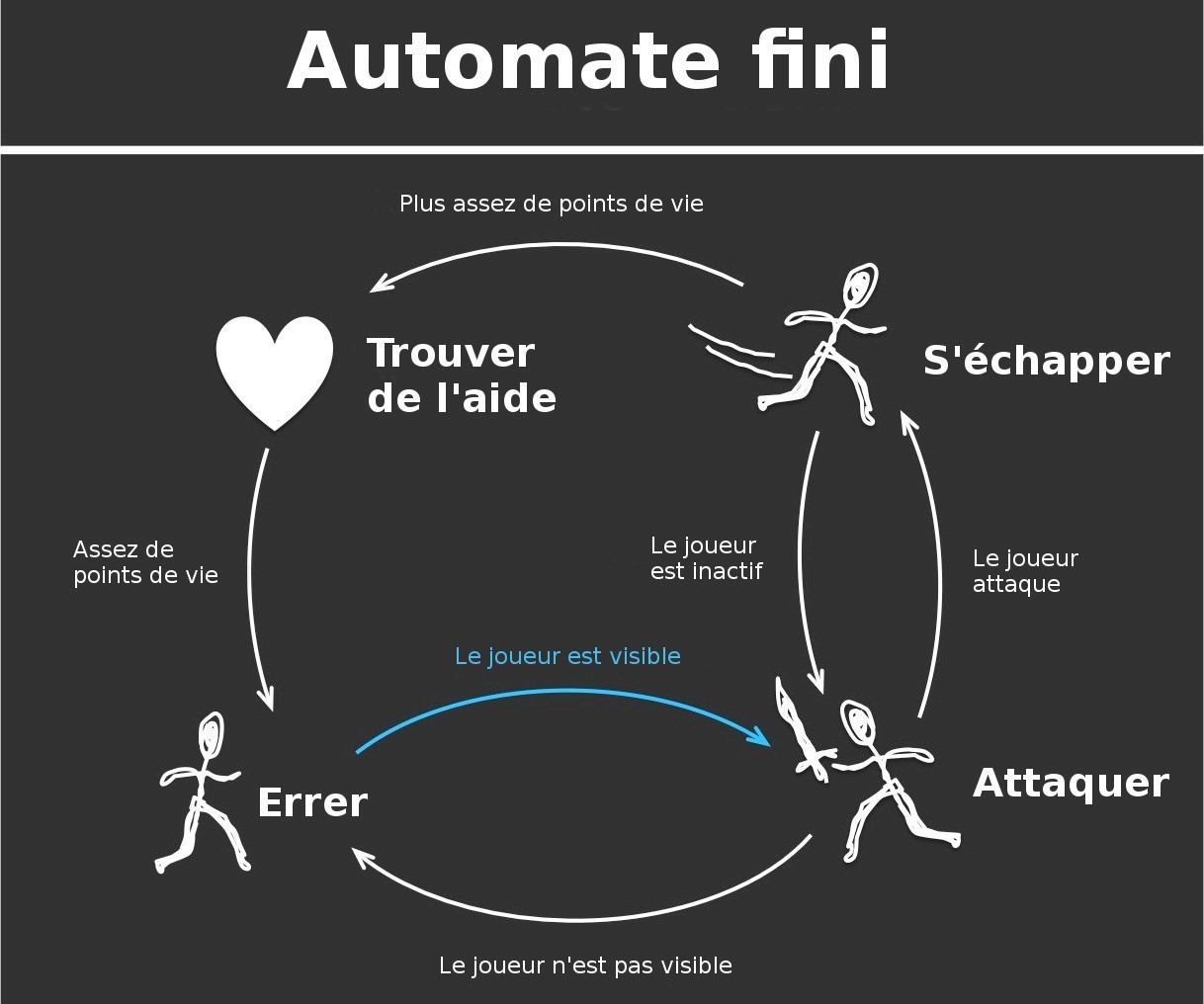
Cependant, un automate fini ne présente aucune adaptabilité, puisque une fois l’automate défini et implémenté, le comportement de l’IA ne pourra pas évoluer ou s’adapter. Pour un même objectif, le PNJ effectuera toujours les mêmes actions. Il présentera donc souvent un comportement relativement simple et prévisible (même s’il est toujours possible de présenter de l’imprévisibilité en ajoutant un peu d’aléatoire dans les transitions par exemple).
Un automate fini permet de manuellement définir les objectifs et les stimuli d’un agent afin de dicter son comportement. Pour chaque objectif, on définit un ou des états et chaque état dicte une ou des actions pour le PNJ. En fonction d’événements extérieurs ou de stimuli, l’objectif du PNJ peut changer et donc l’automate peut transitionner d’un état à un autre.
Un automate fini est donc simplement un moyen de représenter l’espace des états d’un agent ainsi que l’ensemble des transitions entre ses différents états. Si les états et les transitions sont bien définis, l’agent présentera un comportement pertinent dans toutes les situations. Les automates finis sont en général représentés sous la forme d’un diagramme de flux comme l’exemple ci-dessous.
L’avantage principal des automates finis est qu’ils permettent de modéliser un comportement pertinent assez simplement et rapidement puisqu’il suffit de définir manuellement les règles qui définissent les différents états et transitions. Ils sont aussi pratiques puisqu’ils permettent de voir visuellement comment peut se comporter un PNJ.
Les automates finis, par leur conception simple, permettent de compléter, de modifier ou de debugger un système d’IA relativement facilement. Il est ainsi possible de travailler sous forme itérative afin de pouvoir rapidement vérifier les comportements implémentés.
Cependant, lorsque l’on veut mettre en place un comportement plus complexe avec un automate fini, cela devient vite compliqué. Il faut définir manuellement un grand nombre d’états et de transitions et la taille de l’automate peut très vite impacter la facilité de débuggage et de modification.
Une évolution des automates finis essaie d’adresser ce problème : les automates finis hiérarchiques. Cette approche groupe des ensembles d’états similaires afin de limiter le nombre de transitions entre les états possibles. L’objectif est de garder la complexité de ce qu’on souhaite modéliser, tout en simplifiant le travail de création et de maintenance du modèle en structurant les comportements.
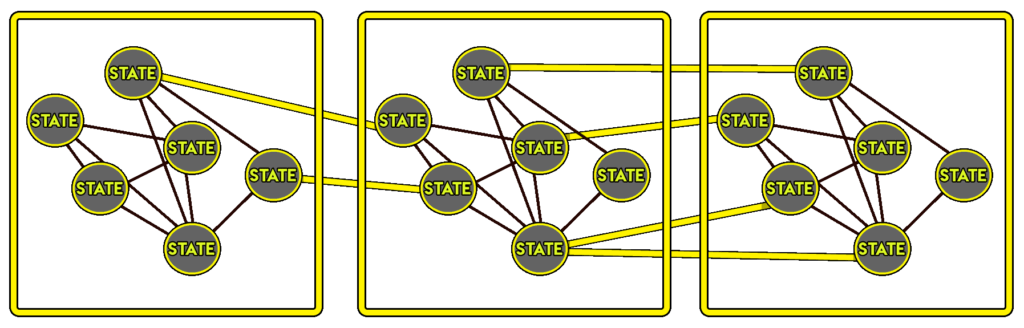
Les automates finis ont été la méthode la plus populaire pour construire des comportements simples dans les jeux vidéo jusqu’au milieu des années 2000. Ils sont encore utilisés sur certains jeux récents comme la série des Batman: Arkham ou DOOM (qui utilise des automates finis hiérarchiques pour modéliser le comportement des ennemis). Cependant, ils ne sont plus les algorithmes les plus fréquemment utilisés sur le marché.
Les arbres de comportements (Behaviour Tree)
Les arbres de comportements sont assez proches des automates finis, à la différence qu’ils se basent directement sur les actions (et non les états), et qu’ils représentent les différentes transitions entre actions sous la forme d’un arbre. La structure de représentation sous forme d’arbre permet d’implémenter beaucoup plus simplement des comportements complexes. C’est aussi plus simple à maintenir, car on obtient une meilleure idée des possibilités d’action de l’agent en parcourant l’arbre qu’avec un diagramme de flux.
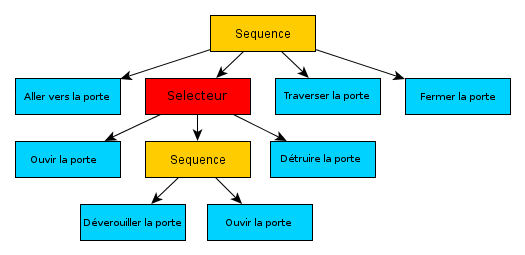
Un arbre de comportement est constitué de différents types de noeuds :
- Les noeuds feuilles (ci dessus en bleu) qui n’ont aucun descendant et qui représentent des actions
- Les noeuds sélecteurs (en rouge) qui ont plusieurs descendants et qui permettent de choisir le plus pertinent en fonction du contexte
- Les noeuds séquences (en jaune) qui exécutent tous leurs noeuds descendants dans l’ordre et permettent donc de faire des séquences d’actions
Un arbre de comportement est exécuté de haut en bas et de gauche à droite On commence du noeud racine (le tout premier noeud) jusqu’à la feuille la plus à droite. Une fois arrivé à la feuille et l’action exécutée, on retourne au noeud racine et on parcourt jusqu’à la feuille suivante.
Ainsi, dans l’arbre ci-dessus:
Le PNJ va aller jusqu’à la porte, ensuite suivant le type de porte et les objets qu’il a sur lui il va soit ouvrir la porte, soit la déverrouiller puis l’ouvrir, soit la détruire. Il va ensuite passer la porte et la refermer. On voit que cet arbre permet de définir différentes séquences d’actions qui permettent d’atteindre un même objectif : passer de l’autre côté d’une porte.
Il est bien sûr possible de construire des arbres beaucoup plus complets qui peuvent représenter l’ensemble des informations de comportement du PNJ. Par exemple ci-dessous un arbre de comportement qui permet de passer par une porte ou par une fenêtre suivant le contexte.
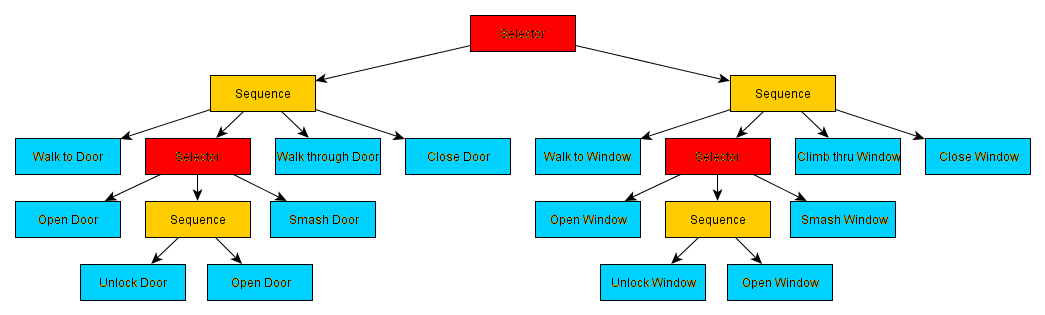
Les arbres de comportements présentent globalement les mêmes limitations que les automates finis. Principalement, ils décrivent un comportement fixe et prédictible puisque toutes les règles et les actions sont définies en amont manuellement. Cependant, leur architecture sous forme d’arbre permet de faciliter le développement et de limiter les erreurs permettant ainsi de créer des comportements plus complexes.
Les arbres de comportements ont été utilisés pour la première fois avec Halo 2 en 2004. Ils ont depuis été utilisés dans un certain nombre de licences à succès comme Bioshock en 2007 ou Spore en 2008 par exemple.
Les approches basées sur l’utilité (utility based AI)
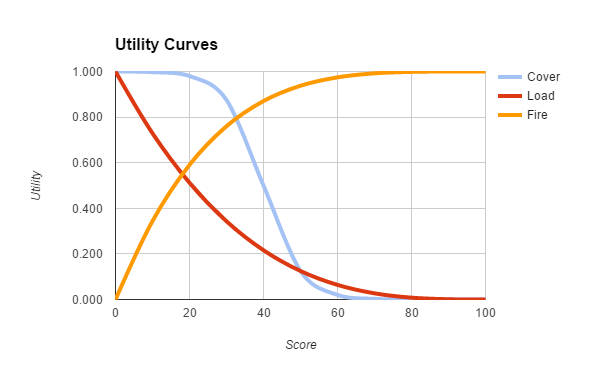
Avec cette approche, plutôt que de transitionner d’un état à un autre en fonction d’évènements extérieurs, un agent va constamment évaluer les différentes actions possibles qu’il peut effectuer à un instant donné et choisir l’action qui a la plus forte utilité pour lui dans les conditions présentes. Pour chaque action on définit en amont une courbe d’utilité en fonction des conditions. On peut par exemple définir une courbe d’utilité sur le fait de tirer sur le joueur en fonction de la distance avec celui-ci. Plus le joueur est proche plus il semble utile de tirer dessus pour éviter de se faire éliminer. En choisissant différents types de courbes (linéaires, logarithmiques, exponentielles, etc..) pour les différentes actions, on peut prioriser quelle action effectuer dans quelles conditions sans avoir à détailler manuellement tous les cas possibles.
Cette approche permet donc de développer des comportements complexes et beaucoup plus modulaires sans avoir à définir un très grand nombre d’états. La liste des actions possibles peut facilement être complétée ou modifiée avec ce type d’approche, ce qui n’était pas le cas avec des automates finis ou des arbres de comportements. Cependant, il est quand même nécessaire de définir toutes les courbes d’utilité et de bien les paramétrer pour obtenir les comportements voulus.
Cette approche, grâce à ses avantages, est de plus en plus utilisée dans les jeux vidéo. On peut citer notamment Red Dead Redemption (2010) et Killzone 2 (2009).
Dans ce premier article, nous avons principalement parcouru les méthodes classiques ad hoc. Comme on a pu le constater, ces différentes méthodes permettant de modéliser des comportements ont chacune leurs avantages et inconvénients. Voici donc un petit tableau récapitulatifs des différentes approches abordées jusqu’ici.
On peut remarquer que toutes ces approches présentent un inconvénient commun : les comportements définis ne peuvent pas du tout s’adapter à la façon de se comporter du joueur. Dans le deuxième article nous allons donc nous intéresser à des méthodes plus poussées comme la planification ou les approches basées sur du Machine Learning pour essayer de corriger cet inconvénient.
Jusqu’ici, nous avons vu les méthodes ad-hoc qui gèrent manuellement les actions et les stimuli des agents. Ces méthodes fonctionnent bien pour présenter des comportements intelligents à court terme. Cependant, pour concevoir des agents qui peuvent penser à plus long terme, il est nécessaire d’utiliser d’autres méthodes : les algorithmes de planification (planning).
Plutôt que de devoir définir manuellement l’espace des états et les différentes actions pour atteindre un objectif, la planification correspond à effectuer une recherche de solution dans l’espace des états pour atteindre un objectif.
En utilisant un algorithme de planification, on va donc rechercher une séquence d’actions qui permet d’arriver à un état voulu.
Présenté pour le pathfinding, l’algorithme A* n’est pas seulement utile pour de la recherche de chemin sur une grille. En effet, on peut aussi l’utiliser pour de la recherche dans l’espace des états et donc pour faire de la planification. L’espace des états est souvent représenté sous la forme d’un arbre où les noeuds sont des états et les branches des actions. Les arbres sont des types de graphes qui sont particulièrement adaptés à la recherche.
L’approche GOAP (Goal Oriented Action Planning)
Cette approche, utilisée pour la première fois en 2005 pour le jeu F.E.A.R, est basée sur l’utilisation d’automates finis ainsi qu’une recherche par A* dans les états de ces automates.
Dans le cas d’un automate fini classique, la logique qui détermine quand et comment transitionner d’un état à un autre doit être spécifiée manuellement ce qui peut être problématique pour des automates avec beaucoup d’états comme on l’a vu précédemment. Avec l’approche GOAP, cette logique est déterminée par le système de planification plutôt que manuellement. Cela permet à l’agent de prendre ses propres décisions pour passer d’un état à un autre.
Avec cette approche, l’espace des états est représenté par un automate fini. Contrairement à l’approche classique où l’on défini un automate avec beaucoup d’états qui correspondent tous à une action spécifique, on va définir un petit automate avec seulement quelques états assez abstraits. Chaque état abstrait correspond donc à de grandes catégories d’actions qui seront dépendantes du contexte. Par exemple, les automates finis des PNJs dans F.E.A.R présentent seulement 3 états très abstraits. Un des états permet de gérer les déplacements et les deux autres permettent de gérer les animations. Le comportement complexes des PNJs est donc simplement une succession de déplacements et d’animations.
L’intérêt de l’approche GOAP est que, suivant le contexte dans lequel un objectif est défini, plusieurs plans d’actions différents peuvent être trouvés pour résoudre un même problème. Ce plan d’action est construit à travers les états de l’automate fini qui dictent les mouvements et animations du PNJ.
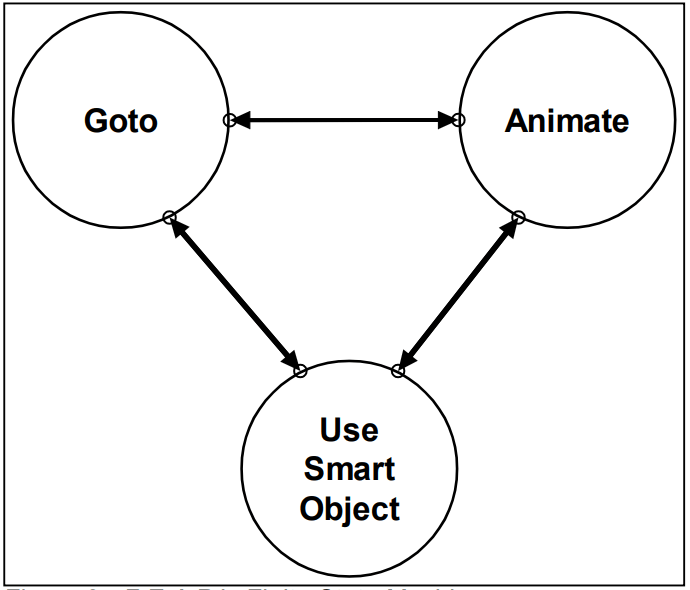
Quoi qu’il arrive, le plan (la séquence d’actions) trouvé par l’algorithme A* sera toujours une réflexion de l’objectif de l’agent à l’instant présent. Si les objectifs des PNJs sont toujours bien définis, ils présenteront un comportement cohérent, complexe et varié voire parfois surprenant. En effet, ces plans peuvent être plus “long terme” que ceux définis manuellement par un simple automate fini ou un arbre de comportement. C’est pourquoi on peut apercevoir des ennemis se déplacer pour contourner le joueur dans F.E.A.R par exemple.
Cette approche permet d’obtenir des comportements très crédibles dans F.E.A.R, mais elle n’est cependant pas forcément adaptée à tous les types de jeux. En effet, pour des jeux très ouverts et complexes où le nombre d’actions possibles est important la méthode peut présenter des limitations. Dans F.E.A.R, les plans trouvés par l’algorithme de recherche restent relativement courts (en général les séquences ne font pas plus de 4 actions), mais comme les actions et les états sont définis de façon abstraite et haut niveau, une séquence de 4 actions est suffisante pour changer de pièce, contourner le joueur, déplacer des objets, se mettre à couvert etc.. Si un jeu nécessite de trouver des plans avec des séquences d’actions beaucoup plus longues, il est fréquent que l’algorithme soit trop lourd en terme de ressources et que les plans trouvés divergent trop du comportement visé par les concepteurs. En effet, ce genre d’approche apporte moins de contrôle sur le résultat final qu’un arbre de comportement ad hoc par exemple.
C’est le problème qu’ont rencontré les développeurs du jeu Transformers: War for Cybertron en 2010. Ils ont donc décidé de changer d’approche et se sont tournés vers une autre méthode de planning : l’approche Hierarchical Task Network planning (HTN). Pour ceux qui sont intéressés, leurs problématiques et l’implémentation de l’approche sont expliqués dans cet article d’AI and Games.
Cette approche dans F.E.A.R a été à l’époque de sa sortie une petite révolution dans le monde de l’IA dans les jeux vidéo et elle a depuis été modifiée et améliorée suivant les besoins (avec l’approche HTN par exemple). Par exemple, on retrouve cette approche dans S.T.A.L.K.E.R, Just Cause 2, Tomb Raider, Middle Earth: Shadow of Mordor ou encore Deus Ex: Human Revolution.
Le cas des jeux de stratégie
Il est évident que, suivant le type de jeu, l’IA n’a pas du tout la même vocation ni les mêmes possibilités. La plupart des méthodes présentées précédemment sont utilisées pour implémenter les comportements d’agents dans un monde dans lequel le joueur évolue. Que ça soit un jeu de tir, ou un jeu de rôle, les PNJ sont en général des personnages similaires au joueur dans le sens ou ils n’ont un contrôle que sur leurs propres actions. De plus, un comportement planifié à court ou moyen terme (4 actions pour F.E.A.R) est souvent suffisant pour présenter un comportement satisfaisant.
Il existe cependant d’autres types de jeu (notamment les jeux de stratégie) où un agent qui joue au jeu doit contrôler plusieurs unités en même temps et mettre en place des stratégies sur le très long terme pour pouvoir se défaire de ses adversaires. Ce genre de jeux peut se rapprocher des jeux de plateaux comme les échecs ou le Go. À un instant donné, un agent peut effectuer un très grand nombre d’actions possibles. Les actions possibles, pertinentes ou non, sont dépendantes de l’état actuel du jeu (qui lui découle de toutes les actions prises précédemment par le joueur et son adversaire).

Dans ce genre de jeu, l’espace des états correspond à l’ensemble des configurations possibles dans lequel peut se retrouver le jeu. Plus le jeu est complexe, plus cet espace est grand et plus il est difficile pour une IA d’y jouer.
En effet, pour pouvoir jouer à ce genre de jeu, une IA doit parcourir l’espace des états pour estimer la pertinence des différentes actions possibles. Pour un jeu comme les échecs il est encore possible de rechercher dans l’espace des états (de taille 10^47) mais pour des jeux plus compliqués comme le Go cela devient impossible en terme de puissance de calcul. Le Go présente environ 10^170 états. En comparaison, le jeu de stratégie en temps réel Starcraft II a un espace des états estimé à 10^1685. Pour donner une idée, on estime qu’il y a environ 10^80 protons dans l’univers observable.
Pendant longtemps l’IA n’était pas capable de battre les meilleurs joueurs aux jeux de plateau comme les échecs (ce n’est qu’en 1997 que l’IA Deep Blue a réussi à battre Kasparov, le champion du monde d’échecs). Le jeu de Go n’a quant à lui été “résolu” qu’en 2016 grâce, entre autres, à l’émergence du Deep Learning. Autant dire que les méthodes de recherche et de planning (comme GOAP dans F.E.A.R) ne peuvent pas fonctionner pour les jeux comme Starcraft et que les développeurs ont dû trouver d’autres solutions.
Les IA des jeux de stratégie ont donc été basées sur des approches plus simplistes ou chaque unité présentait un comportement indépendant des autres. Si chaque unité est prise indépendamment, son espace des états est beaucoup plus réduit et il devient possible de le représenter par une méthode ad hoc (comme un automate ou un arbre de comportement) ou de faire une recherche dedans pour trouver une séquence d’action (de la même façon que pour les PNJs des jeux de tir par exemple).
Avec cette approche, il devient possible de calculer les comportements de toutes les unités, mais l’IA ne peut pas vraiment présenter de stratégie globale, les différentes unités ne pouvant pas se coordonner. Ces IAs sont donc en général incapables de battre des joueurs aguerris.
C’est la difficulté de la tâche qui a souvent amené les développeurs de ces IAs à tricher, seule solution pour pouvoir présenter un quelconque challenge au joueur. C’est parfois toujours le cas aujourd’hui suivant le type de jeu. Par exemple dans Starcraft II (sortie en 2010), les niveaux de difficulté les plus élevés pour le joueur sont gérés par des IA qui trichent.
Les développeurs de Starcraft II jouent ici la transparence sur leur IA. Tout joueur qui se risque contre le niveau de difficulté le plus élevé sait à quoi s’attendre. Malgré cette triche, l’IA du jeu reste prévisible et les bons joueurs arrivent à s’en défaire sans trop de difficulté.
Monte Carlo Tree Search à la rescousse
Récemment, une nouvelle méthode a fait beaucoup parler d’elle pour ce genre de problématiques où l’espace à rechercher est très grand. Il s’agit de la méthode Monte Carlo Tree Search. Utilisée pour la première fois en 2006 pour jouer au Go, elle a rapidement permis d’améliorer les systèmes de l’époque (qui ne pouvaient pas encore rivaliser avec un joueur amateur). Puis plus récemment en 2016, elle a été utilisée comme une des briques principales d’AlphaGo, l’algorithme qui a réussi à vaincre le champion du monde de Go.
Cette méthode peut aussi bien sur être appliquée aux jeux vidéo. Elle a notamment été utilisée pour le jeu Total War : Rome II sorti en 2013. Les jeux de la série Total War présentent différentes phase de jeux:
- Une phase de stratégie au tour par tour sur une carte du monde ou chaque joueur doit gérer son pays ainsi que les relations avec les pays alentours (diplomatie, guerre, espionnage etc..).
- Une phase de bataille en temps réel à une échelle rarement vue dans les jeux vidéo (chaque camp présente souvent plusieurs milliers d’unités).
La phase au tour par tour présente un espace des états très grand dans lequel il n’est pas possible de rechercher des séquences d’actions et donc des stratégies pertinentes. C’est dans cette phase de jeu que la méthode MCTS peut aider. En effet, comme cette phase se déroule au tour par tour, il est possible de prendre un peu de temps pour trouver une bonne solution. Ici le système d’IA n’est pas obligé de répondre en quelques millisecondes comme c’est souvent le cas.
La méthode MCTS permet de rechercher efficacement des solutions dans un espace impossible à parcourir entièrement. La méthode se base sur des notions d’apprentissage par renforcement, particulièrement le dilemme exploration-exploitation. L’exploitation consiste à parcourir les branches de l’arbre que l’on pense être les plus pertinentes pour trouver la meilleure solution. L’exploration à l’inverse consiste à parcourir de nouvelles branches que l’on ne connaît pas ou que l’on avait préalablement considérés comme non pertinentes.
Il peut sembler logique de ne vouloir faire que de l’exploitation, c’est-à-dire toujours se focaliser sur les solutions que l’on pense être les meilleures. Cependant la méthode MCTS est utilisée dans les cas où il n’est pas possible de rechercher l’ensemble des solutions puisque l’arbre est trop grand (sinon on utilise un algorithme comme le minimax). Dans ce cas là il n’est pas possible de savoir si la solution que l’on considère est vraiment la meilleure. Peut-être qu’une autre partie de l’arbre non parcourue contient de meilleures solutions. De plus, une branche non pertinente à un moment donné, peut le devenir plus tard, c’est pourquoi si l’on fait seulement de l’exploitation on risque de rater des solutions intéressantes. La méthode MCTS permet de trouver un compromis entre exploration et exploitation afin de trouver rapidement des solutions satisfaisantes.
L’algorithme MCTS peut être découpé globalement en 4 phases répétées un grand nombre de fois. Tout d’abord, l’idée est de parcourir de façon intelligente l’espace des états depuis la racine jusqu’à atteindre un noeud feuille de l’arbre (c’est la phase de Sélection – voir figure ci-dessous). Ensuite, l’algorithme choisit une action à effectuer, c’est la phase d’Expansion. Une fois cette action choisie, l’idée est et de simuler le jeu en choisissant un enchaînement d’actions de façon aléatoire jusqu’à arriver à la fin du jeu. C’est la phase de Simulation. Et enfin, en fonction du résultat final du jeu (victoire ou défaite), l’algorithme évalue si le noeud choisi à l’étape d’Expansion était pertinent ou non et il pondère tous les noeuds parcourus lors de cette simulation en fonction du résultat. C’est la phase de Backpropagation
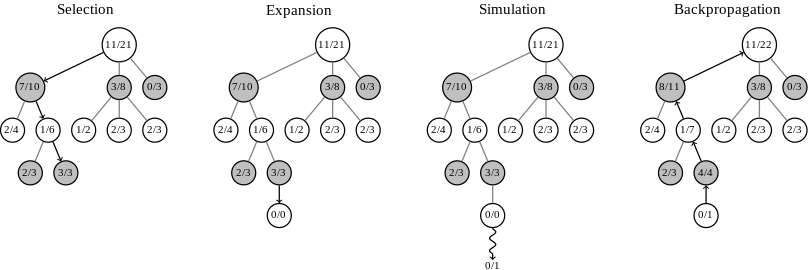
L’objectif de l’étape de Backpropagation est de faire en sorte que les noeuds qui semblent les plus pertinents soient choisis plus fréquemment lors des prochaines étapes de Sélection. C’est lors de la phase de Sélection que le compromis entre exploration et exploitation est fait. L’idée de la méthode MCTS est de lancer des milliers de fois ces quatre étapes de simulations et au moment de prendre une décision, de choisir le noeud qui a donné au total le plus de victoires sur l’ensemble les simulations
L’avantage de la méthode est que l’on peut définir un temps d’exécution maximal. Jusqu’à la limite de temps alloué, l’algorithme va lancer des simulations. Une fois le temps écoulé il suffit de prendre le noeud avec le plus grand taux de victoire. Plus on lui laisse de temps, plus il y a de chances qu’il trouve de bonnes solutions puisque les statistiques calculées seront précises. Ainsi, la solution finalement trouvée par MCTS ne sera peut-être pas la solution optimale mais elle sera la meilleure solution trouvée dans le temps imparti. Cette approche a permis à l’agent qui joue à la phase de stratégie tour par tour de Rome II Total War de présenter des stratégies relativement poussées malgré la complexité très importante de l’espace des états du jeu.

De façon amusante, le système d’IA pour les batailles en temps réel se base quant à lui sur des méthodes ad hoc tirées de l’Art de la Guerre de Sun Tzu (environ 500 avant J-C).
Une citation pertinente même pour un système d’IA
Ces règles de stratégie peuvent aussi être appliquées avec succès dans un jeu vidéo. Par exemple:
- Quand vous entourez l’ennemi, laissez une porte de sortie
- N’essayez pas de bloquer la route de l’ennemi sur un terrain dégagé
- Si vous êtes 10 fois plus nombreux que l’ennemi, entourez-le
- Si vous êtes 5 fois plus nombreux que l’ennemi, attaquez-le de front
- Si vous êtes 2 fois plus nombreux que l’ennemi, divisez-le
Ces règles simples peuvent facilement être implémentées dans un système ad hoc et permettent à l’IA de présenter un comportement pertinent dans bon nombre de situations et donc de proposer des batailles réalistes.
Et le Machine Learning dans tout ça ?
Toutes les méthodes présentées jusqu’ici ne proposent pas d’apprentissage. Les comportements sont régis par des règles définies manuellement et par la façon de considérer ces règles en fonction de l’environnement. Pour obtenir des IA plus complexes qui peuvent vraiment s’adapter à des situations variées, il semble nécessaire de mettre en place des systèmes qui peuvent apprendre automatiquement à agir en fonction du comportement du joueur. La branche d’apprentissage automatique en IA s’appelle le Machine Learning.
Des méthodes d’apprentissage automatiques ont parfois été utilisées pour coder le comportement d’agents. Par exemple les unités dans les batailles temps réel des jeux Total War sont contrôlées par des perceptrons (les réseaux de neurones ancêtres du Deep Learning). Dans ce genre d’implémentation les réseaux sont très simples (on est loin des réseaux énormes du Deep Learning).
Les entrées des réseaux correspondent à l’état du jeu (la situation) et les sorties correspondent à l’action prise. L’apprentissage de ces réseaux est fait en amont pendant le développement du jeu (parfois même manuellement pour les réseaux les plus simples). Ce genre de méthode se rapproche au final des méthodes ad hoc puisque le comportement des unités est fixé par le développeur et qu’il n’évolue pas pendant le jeu.
Il y a cependant eu des cas où les agents pouvaient vraiment apprendre pendant le jeu. Par exemple dans Black and White (sorti en 2000) qui est réputé pour avoir réussi à mélanger différentes approches d’IA en obtenant un résultat performant. Le principe du jeu se base beaucoup sur l’interaction entre le joueur et une créature ayant un comportement complexe.
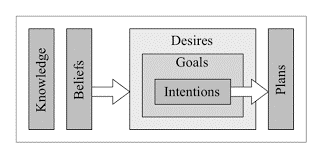
Le comportement de prise de décision de la créature est modélisé selon un agent “croyance-désir-intention” (belief-desire-intention – BDI). L’approche BDI est un modèle de psychologie, qui est ici adapté pour les jeux vidéo. Cette approche comme son nom l’indique modélise, pour un agent, un ensemble de croyances, de désirs et d’intentions qui dictent sa prise de décision.
Les croyances correspondent à l’état du monde vu par l’agent. Ces croyances peuvent être fausses si l’agent n’a pas accès à toutes les informations. Les désirs, basés sur les croyances, représentent les motivations de l’agent et donc les objectifs court et long terme qu’il va chercher à atteindre.
Les intentions sont les plans d’action que l’agent a décidé d’exécuter pour atteindre ses objectifs. Dans Black and White, les croyances de la créature sont modélisés par des arbres de décision et les désirs sont modélisés par des perceptrons. Pour chaque désir, la créature se base sur ses croyances les plus pertinentes.
Le modèle BDI représente le système de prise de décision de la créature, mais au début du jeu, elle est comme un enfant dont les croyances et les désirs ne sont pas bien définis. Au cours du jeu, la créature apprend à se comporter à travers ses interactions avec le joueur. En effet, le joueur peut récompenser la créature ou la punir en fonction de ses actions. À travers un algorithme d’apprentissage par renforcement la créature va découvrir quelles actions entraînent une récompense et lesquelles entraînent une punition. Cela va donc modéliser son comportement pour être en accord avec ce que lui demande le joueur.
Le système comportemental de la créature est donc un système hybride basé sur un socle d’IA ad hoc (le modèle BDI) pour lequel chaque composant est un algorithme d’apprentissage automatique. Ces systèmes hybrides sont probablement le meilleur compromis pour obtenir des comportements complexes et évolutifs mais qui restent quand même dans un cadre défini initialement.
Si ça marche, pourquoi on reste sur de l’ad hoc ?
Ce genre d’approche plus poussée avec de l’apprentissage automatique ne représentent cependant vraiment pas la majorité des implémentations dans les jeux vidéo, et la plupart des IA reconnues comme très performantes récemment comme par exemple l’IA du compagnon dans Bioshock Infinite sont en général plutôt des systèmes ad hoc très complexes et très bien pensés pour rentrer parfaitement dans le gameplay du jeu (avec toutes les triches que cela peut nécessiter, comme la téléportation du compagnon quand le joueur ne peut pas le voir par exemple).
Si les développeurs continuent de se raccrocher aux méthodes classiques d’IA ad hoc, c’est premièrement parce qu’au final, ces méthodes fonctionnent bien (par exemple dans F.E.A.R ou Bioshock Infinite). En effet, ce que les concepteurs cherchent à créer est une illusion d’intelligence qui soit crédible pour le joueur, même si le modèle qui gère les PNJs est au final très simple. Tant que l’illusion est présente, le contrat est rempli. Cependant mettre en place ce type de système peut en fait vite devenir d’une grande complexité suivant le type de jeu et donc nécessiter un temps et des ressources de développement très importants. La majorité des déboires de l’IA dans les jeux vidéo est probablement due à un investissement dans le développement de l’IA trop faible plutôt qu’à des méthodes non adaptées.
La deuxième raison importante qui force les développeurs à rester sur des systèmes sans apprentissage est la difficulté à prévoir le comportement des IA dans toutes les situations. Les concepteurs de jeu craignent qu’une IA qui apprend automatiquement puisse briser l’expérience de jeu du joueur en présentant un comportement non prévu et incohérent qui sortirait le joueur de son immersion dans l’univers du jeu (on peut noter que c’est cependant justement ce qui se passe avec un système d’IA ad hoc mal implémenté). Les designers veulent imaginer intégralement l’expérience que vivra le joueur et c’est beaucoup plus difficile à définir avec une IA qui apprend automatiquement.
Un autre point important est que le comportement du PNJ se doit d’être un minimum prévisible et présenter des codes qui sont connus et attendus par les joueurs. Ces codes de comportements sont hérités des premiers jeux qui ont défini les styles et de leur évolution.
Par exemple, en général dans les jeux d’infiltration les gardes font des rondes en suivant un schéma spécifique que le joueur doit mémoriser pour pouvoir passer sans se faire voir. En implémentant avec une IA un comportement plus complexe on peut risquer de changer l’expérience classique des jeux d’infiltration et c’est donc un choix à faire en connaissance de cause. Un autre cas similaire est le combat de boss. Dans de nombreux jeux les combats contre les boss sont des phases particulières ou le boss à un comportement prédéterminé qui doit être compris par le joueur pour pouvoir gagner.

Un boss qui s’adapterait trop à la façon de jouer du joueur pourrait surprendre les joueurs formatés par leurs expériences passées. En implémentant une IA dans un jeu, il faut être capable de le faire tout en jouant avec les nombreux clichés du médium. C’est pourquoi les approches les plus innovantes en terme d’IA de nos jours sont souvent liées à de nouveaux concepts de jeux, les styles classiques étant parfois considérés trop rigides pour accueillir ce genre d’IA.
Enfin, une autre raison de rester sur des méthodes ad hoc semble être que l’on a toujours fait comme cela dans le domaine, et que se mettre à innover sans assurance de succès dans un cadre aussi restreint en terme de temps et de ressources que le développement d’un jeu vidéo semble être un risque assez conséquent à prendre. Surtout pour des studios de développement dont la santé peut dépendre du succès ou non d’un seul jeu.
L’évolution des méthodes
Comme on a pu le voir les méthodes d’IA dans les jeux vidéo ont évolué sans cesse au cours du temps pour devenir de plus en plus complexes et poussées. On peut ainsi se demander pourquoi lorsque l’on joue, on a la sensation que l’IA stagne et qu’elle ne s’améliore pas vraiment. La réponse est très probablement que les jeux deviennent de plus en plus grands et compliqués et donc que les tâches que les IAs doivent résoudre pour être cohérentes sont de plus en plus complexes.

Ainsi, les jeux dont l’IA a été un franc succès sont souvent des jeux ou le domaine était relativement réduit. Par exemple dans F.E.A.R qui se focalise sur des affrontements à petite échelles. Plus les jeux sont ouverts, plus il y a de chances que l’IA soit prise en défaut. On peut prendre l’exemple de l’IA des bandits dans le jeu de rôle Skyrim.
Ceux-ci présentent des failles assez évidentes qui peuvent amener au genre de situations incongrues dépeintes par l’image ci-dessus. Le problème dans Skyrim est que l’IA des PNJs doit être capable de gérer un nombre très grand de situations différentes, il y a donc très probablement des situations où elle ne sera pas adaptée.
Un autre problème dans les jeux trop grands est que la quantité de contenu à générer pour que ce monde soit cohérent devient très importante. Si on veut que chaque PNJ soit unique et présente une histoire qui lui est propre, cela représente un travail énorme. C’est pourquoi l’ensemble des gardes dans Skyrim ont tous pris une flèche dans le genou dans leur jeunesse quand ils étaient aventuriers.
L’IA peut nous aider face à cette problématique de contenu grâce à ce que l’on appelle la génération procédurale de contenu. Dans la suite de cet article nous nous intéresserons donc à d’autres façon moins fréquentes d’implémenter de l’IA dans des jeux vidéo, et notamment avec la génération procédurale de contenu.
La génération procédurale
Comme nous l’avons vu dans les articles précédents, l’IA dans les jeux vidéo est principalement utilisée pour implémenter les comportements des personnages non joueurs (PNJs). Cette approche a eu tellement d’importance que d’autres problématiques potentiellement adressées par l’IA ont longtemps été négligées. Récemment, ce genre d’approche alternative a commencé à se développer de plus en plus, la principale étant probablement la génération procédurale de contenu.
La génération procédurale de contenu fait référence aux méthodes qui permettent de générer du contenu dans un jeu avec peu ou pas d’intervention humaine. Le contenu généré peut être de nature très variée et toucher à presque l’intégralité d’un jeu. On peut citer : des niveaux, des terrains, des règles de jeux, des textures, des histoires, des objets, des quêtes, des armes, des musiques, des véhicules, des personnes,.. En général, on considère que le comportement des PNJs ainsi que le moteur du jeu ne correspondent pas à du contenu à proprement parler. L’utilisation la plus fréquente de génération procédurale est probablement la création de niveaux et de terrains.
L’utilisation de la génération procédurale a explosé depuis le milieu des années 2000 cependant le domaine existe depuis très longtemps. En effet, en 1980 le jeu Rogue utilisait déjà de la génération procédurale pour créer automatiquement ses niveaux et placer les objets dans ceux-ci. En 1984, Elite un jeu de simulation de commerce spatial générait quant à lui de nouveaux systèmes planétaires (avec leur économie, politique et population) durant le jeu.
Les objectifs
Quel est l’intérêt de la génération procédurale ? Les premiers jeux ont utilisé la génération procédurale pour permettre de réduire l’espace de stockage. En effet, en générant à la volée les textures et les niveaux du jeu, il n’est plus nécessaire de les stocker sur la cartouche ou autres médium du jeu. Cela permettait de dépasser les limites physiques imposées par les technologies de l’époque et donc de faire des jeux potentiellement beaucoup plus grands. Par exemple Elite présentait plusieurs centaines de systèmes planétaires en ne nécessitant seulement que de quelques dizaines de kilooctets (ko) sur la machine.
À l’heure actuelle cela n’est plus la principale raison d’utiliser la génération procédurale. Elle permet surtout de générer de grandes quantités de contenu sans devoir tout concevoir à la main. Dans le développement d’un jeu, la phase de création du contenu peut être très lourde et prendre une part importante du budget. La génération procédurale peut permettre d’accélérer la création de ce contenu.
Anastasia Opara (SEED – Search for Extraordinary Experiences Division – chez Electronic Arts) présente dans cette conférence sa vision de la génération de contenu. La création de contenu présente pour elle une phase de créativité qui correspond à la recherche de l’idée et de création artistique puis une phase de fabrication et d’implémentation de cette idée dans le jeu vidéo. Elle présente cette phase comme une montagne nécessitant des compétences particulières et un investissement en temps très important pour être franchie. La génération procédurale de contenu peut être une approche pour tenter de réduire la taille de cette montagne et permettre ainsi aux artistes de se concentrer principalement sur la créativité pure en s’abstrayant de la difficulté d’implémentation.
En plus de faciliter la phase de fabrication du contenu, la génération procédurale peut aussi encourager la créativité des artistes en proposant du contenu inattendu et intéressant. La génération procédurale présente ainsi un aspect de collaboration entre l’artiste et la machine. On peut ainsi trouver des galeries d’oeuvres d’art générées procéduralement.
La génération procédurale de contenu pourrait ainsi favoriser la création humaine et permettre la création de nouvelles expériences de jeu et même potentiellement de nouveaux genres de jeu. On pourrait ainsi imaginer possible une personnalisation des jeux bien plus poussée que ce qui existe actuellement en modifiant le contenu du jeu dynamiquement en fonction des interactions avec le joueur.

Enfin, avec une génération procédurale capable de produire du contenu en variété, qualité et quantité suffisante, il semble possible de créer des jeux qui ne finissent jamais et donc avec une rejouabilité ultime.
Cependant, comme les développeurs s’en sont rendu compte (notamment ceux de No Man’s Sky), la quantité de contenu dans un jeu ne rend pas celui-ci forcément intéressant. Il y a donc un compromis vital à trouver entre la quantité de contenu que l’on génère et la qualité de celui-ci (intéressant, varié, etc..).
Par exemple dans le jeu Elite présenté précédemment, les concepteurs prévoyaient de générer 282 billions de galaxies (c’est beaucoup). L’éditeur du jeu les a convaincus de se limiter à 8 galaxies, chacune composée de 256 étoiles. Avec ce nombre plus mesuré d’étoiles à créer, le générateur du jeu a pu rendre chaque étoile relativement unique, ce qui aurait été impossible avec le nombre de galaxies prévu initialement. Ainsi le jeu proposait un bon équilibre entre taille, densité et variabilité. Avec la génération procédurale de contenu, on peut vite tomber dans le piège d’un univers gigantesque où absolument tout se ressemble. Chaque élément sera mathématiquement différent mais du point de vue du joueur, une fois qu’il a vu une étoile, il les a toutes vues.
Il y a donc en général un équilibre à trouver entre la taille du monde, sa diversité et le temps alloué du développeur. Générer le contenu à travers les mathématiques est la partie scientifique, alors que trouver le bon équilibre entre les différents éléments correspond à la partie artistique.
Les différentes approches
Il y a énormément d’approches pour faire de la génération procédurale de contenu et toutes ne sont pas basées sur de l’intelligence Artificielle. Des méthodes souvent simples sont utilisées à l’instar de la conception des comportements des PNJs afin de pouvoir garder un contrôle plus facilement sur le rendu final. En effet, le contenu généré doit respecter certaines contraintes afin d’être bien intégré dans le jeu.
Nous allons donc d’abord nous intéresser aux principales méthodes classiques de génération procédurale, puis nous ferons un tour d’horizon (non exhaustif) des approches basées sur l’IA.
La génération procédurale constructive
Les approches basées sur des tuiles
La méthode la plus simple et la plus fréquemment utilisée est la méthode basée sur des tuiles. L’idée est simple : le monde du jeu est découpé en sous parties (les tuiles), par exemple des salles dans un jeu d’exploration de donjon. Un grand nombre de salles sont modélisées à la main. Lors de la génération du monde, on sélectionne aléatoirement les salles pré-modélisées pour créer un univers plus grand. Si un assez grand nombre de tuiles ont été définies en amont, par la magie de la combinatoire, on peut obtenir un générateur de monde qui ne produira quasiment jamais deux fois le même résultat.
Avec cette approche, on obtient une diversité de résultat tout en assurant un cohérence locale puisque chaque tuile a été définie manuellement. En général, ce type d’approche implémente aussi des règles métiers spécifiques qui permettent d’assurer que le résultat sera jouable et intéressant.

Par exemple dans un jeu d’exploration comme Spelunky, le générateur s’assure de choisir des tuiles de façon à construire un chemin viable pour le joueur puis remplit les espaces restants avec des tuiles aléatoires. Il peut ensuite parfois nécessiter quelques retraitements entre les tuiles si celles-ci ne s’imbriquent pas correctement les unes aux autres.
Cette approche est souvent utilisée pour générer le terrain ou le monde dans des jeux de type Rogue-like (Cette catégorie de jeu tire son nom du jeu Rogue de 1980 présenté précédemment. On peut citer notamment la série Diablo, The Binding of Isaac, Spelunky ou Rogue Legacy) mais elle permet aussi de générer bien d’autres types d’éléments et d’objets. Par exemple, dans le jeu Borderlands, les armes sont générées par un système basé sur des tuiles.

Les armes sont découpées en sous parties qui sont interchangeables. Chaque arme générée est un tirage aléatoire des différentes sous parties. Chacune de celles-ci a des répercussions sur les statistiques de l’arme comme le temps de chargement, le type de munition, la précision etc.. ce qui fait que toutes les armes générées sont légèrement différentes les unes des autres.
Les approches fractales
Les approches fractales tirent leur nom des célèbres objets mathématiques puisqu’elles ont quelques propriétés similaires. En effet, ces approches de génération procédurale sont basées sur des systèmes de couches successives à différentes échelles, un peu comme des fractales. On va voir deux types d’approches fractales : les méthodes basées sur le bruit et les méthodes basées sur des grammaires.

Méthodes basées sur le bruit
Lorsque l’on observe le monde depuis un avion, l’agencement du terrain semble être relativement aléatoire. L’idée des approches basées sur le bruit est de se baser sur de l’aléatoire pour générer des terrains s’approchant de ceux du monde réel. Lorsque l’on tire aléatoirement une séquence de valeurs, on obtient ce qu’on appelle du bruit blanc.
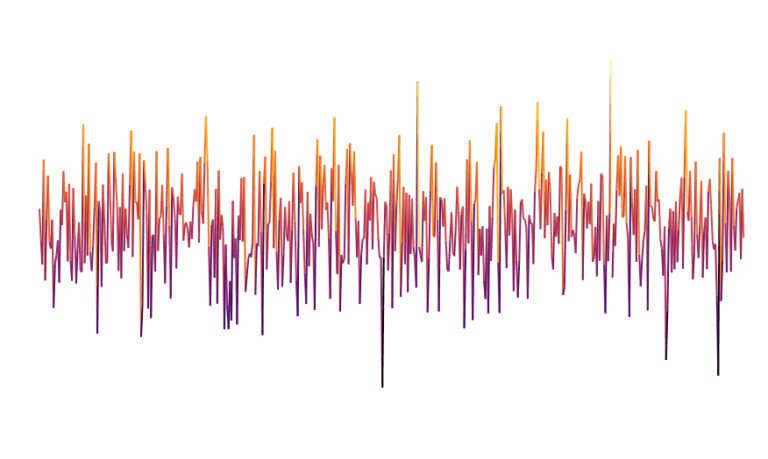
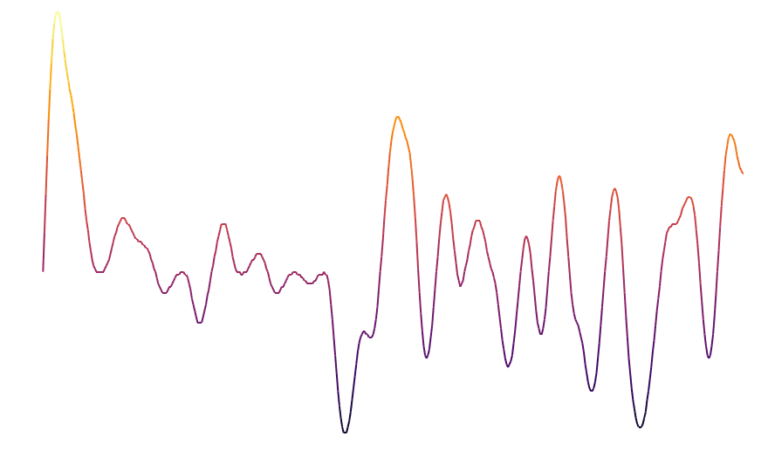
Le bruit blanc n’est pas d’une grande aide pour la génération procédurale puisqu’il est la représentation d’un processus complètement aléatoire (ce qui n’est clairement pas le cas de notre monde). Cependant, il existe d’autres types de bruit qui représentent de l’aléatoire tout en conservant une structure locale. Le plus connu dans le cadre de la génération procédurale est probablement le bruit de Perlin. Ce bruit est généré par un processus aléatoire, cependant les points proches ne sont plus indépendants les uns des autres comme pour du bruit blanc. Cela permet d’obtenir des courbes comme celle ci-contre qui sont plus lisses localement.
Les algorithmes basés sur le bruit deviennent intéressants surtout lorsqu’on augmente le nombre de dimensions. Ainsi, si on prend une grille en deux dimensions et que l’on fait un tirage de bruit blanc et de bruit de Perlin, on obtient les résultats suivants. On a le bruit blanc à gauche et le bruit de Perlin à droite. Chaque pixel est coloré en fonction de sa valeur
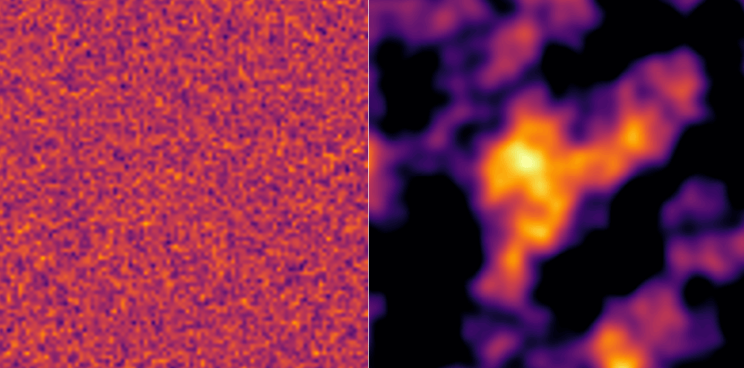
On obtient ainsi pour chaque pixel de la grille une valeur. On peut ensuite considérer la valeur de ce pixel comme une altitude et d’afficher la grille en 3 dimensions. On obtient ainsi une représentation d’un terrain montagneux, intégralement généré par du bruit de Perlin. Le problème du bruit de Perlin est qu’il va avoir tendance à générer des éléments répétitifs et de tailles relativement similaires. On risque ainsi d’obtenir un monde montagneux mais très vide, sans aucun détail entre les montagnes.

Pour éviter ce problème, on utilise plusieurs couches de bruit de Perlin à différentes échelles (on parle d’octaves). Ainsi la première couche sert à générer la géographie grosse-maille du monde et les couches suivantes ajoutent successivement des niveaux de détails de plus en plus fins. On retrouve ainsi l’idée des fractales.
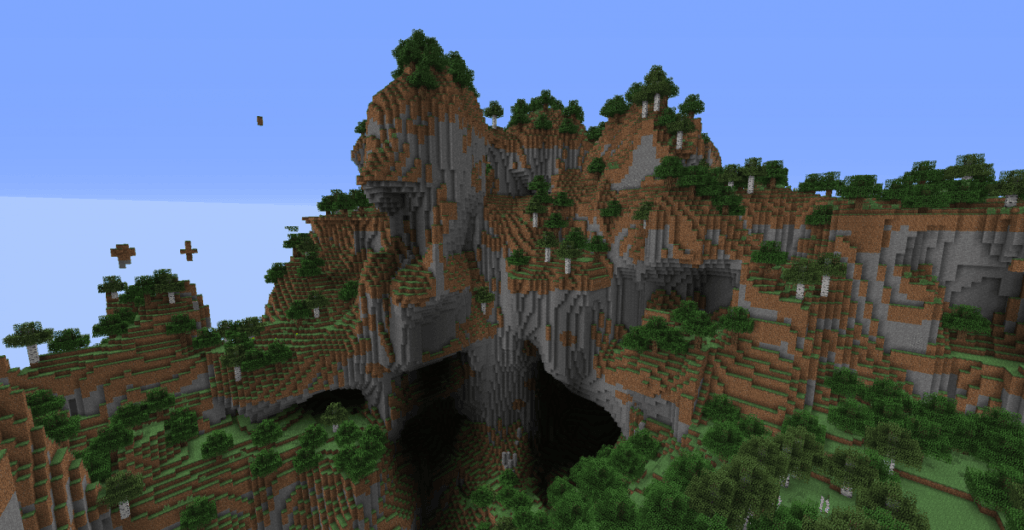
Le bruit de Perlin est probablement l’approche la plus utilisé pour la génération procédurale puisque la génération de terrain est un besoin récurrent dans les jeux vidéo. Cette approche est notamment utilisée par Minecraft pour générer ses mondes.
De nombreuses variations existent autour du bruit de Perlin, puisqu’il faut souvent l’adapter aux besoins spécifiques de chaque jeu. On peut citer le Simplex noise qui est une amélioration du bruit de Perlin (proposée par l’inventeur du bruit de Perlin – Ken Perlin – lui-même). Dans le jeu No man’s sky où presque tout l’univers est généré procéduralement, les planètes sont basées sur ce que les concepteurs appellent l’”Uber noise” qui est une approche se basant sur le bruit de Perlin et combinant nombreux autres types de bruits. Leur approche est censée donner des résultats plus réalistes (et donc plus intéressants pour le joueur) que celles basées seulement sur du bruit de Perlin.
Approches basées sur des grammaires
Une grammaire formelle peut être définie comme un ensemble de règles qui s’appliquent sur du texte. Les règles de la grammaire permettent de transformer une chaine de caractère en une autre. Par exemple :
- A -> AB
- B -> A
Avec la 1ère règle à chaque fois qu’il y aura un “A” dans une chaîne de caractère il sera transformé en “AB” et avec la deuxième règle un “B” sera transformé en “A”.
Les grammaires formelles ont de nombreuses applications en informatique et en IA, mais nous allons nous intéresser à un type de grammaire particulier appelé L-systèmes. Les L-systèmes ont la particularité d’être des grammaires pensées pour faire de la génération de plante. Les L-systèmes présentent des règles récursives, ce qui rend facile la génération de formes fractales. Dans la nature de nombreuses plantes présentent des formes fractales, le chou Romanesco étant l’un des exemples les plus frappants

Un L-système est défini par un alphabet, un ensemble de règles, des modifications et un axiome de départ (qui est la chaîne de caractère que l’on considère pour démarrer)
Prenons un exemple simple :
Un alphabet restreint : {A,B}
Deux simples règles :
- A → AB
- B → A
L’axiome de départ : A
L’idée est d’appliquer plusieurs fois les règles au résultat obtenu précédemment (n étant le nombre de fois où la règle à été appliquée).
On obtient les résultats suivants:
- n = 0 -> A
- n = 1 -> AB
- n = 2 -> ABA
- n = 3 -> ABAAB
- n = 4 -> ABAABABA
- n = 5 -> ABAABABAABAAB
- n = 6 -> ABAABABAABAABABAABABA
- n = 7 -> ABAABABAABAABABAABABAABAABABAABAAB
On peut se demander où est le lien entre cette génération de chaîne de caractère et les plantes. L’idée est d’associer à chaque caractère de l’alphabet une action de dessin. Les chaînes de caractères générées vont donc être des sortes de plans de dessins.
Par exemple on peut considérer un L-système avec l’alphabet suivant:
- F : tracer un trait d’une certaine longueur (par ex 10 pixels)
- + : tourner à gauche de 30 degrés
- – : tourner à droite de 30 degrés
- [ : garder en mémoire la position et orientation actuelle
- ] : revenir à la position et l’orientation en mémoire
On définit une seule règle dans la grammaire :
- F → F[−F]F[+F][F]
L’axiome de départ est : F
Ainsi, pour les différentes itérations, on obtient les résultats suivants. (Les couleurs permettent de faire le lien entre les chaînes de caractères générées et les dessins équivalents)

On peut ainsi continuer à appliquer la règle jusqu’à obtenir un résultat satisfaisant. Les résultats obtenus avec cette grammaire peuvent paraître simplistes mais avec les bonnes règles de grammaire et en itérant l’algorithme assez longtemps, on peut obtenir des résultats très convaincant comme ceux présentés ci-dessous. Il suffit ensuite d’ajouter des textures et des feuilles pour obtenir une belle végétation.
Les L-systèmes ont l’avantage d’être très simple à définir en théorie (une seule règle de grammaire peut être suffisante). En pratique cependant, les choses ne sont pas si simples. En effet, les liens entre axiome, règle et résultats sous forme de dessins après expansions sont très complexes. Il est donc difficile de prévoir le résultat en amont et le tâtonnement semble nécessaire. Ce site permet de jouer avec des L-systèmes afin de visualiser les résultats de grammaire prédéfinies, ainsi que de modifier les règles de ces grammaires et voir l’impact sur les résultat.
Un autre désavantage est que les L-systèmes sont limités à la génération de formes géométriques qui ont des propriétés fractales. C’est pourquoi ils sont principalement utilisés pour la génération de plantes.
Il existe cependant de nombreuses extensions au principe basique des L-système, comme des systèmes avec de l’aléatoire ou des systèmes prenant en compte le contexte. Ces extensions permettent de produire du contenu plus varié. Ainsi, les L-systèmes ont parfois été utilisés pour générer des donjons, des rochers ou encore des caves.
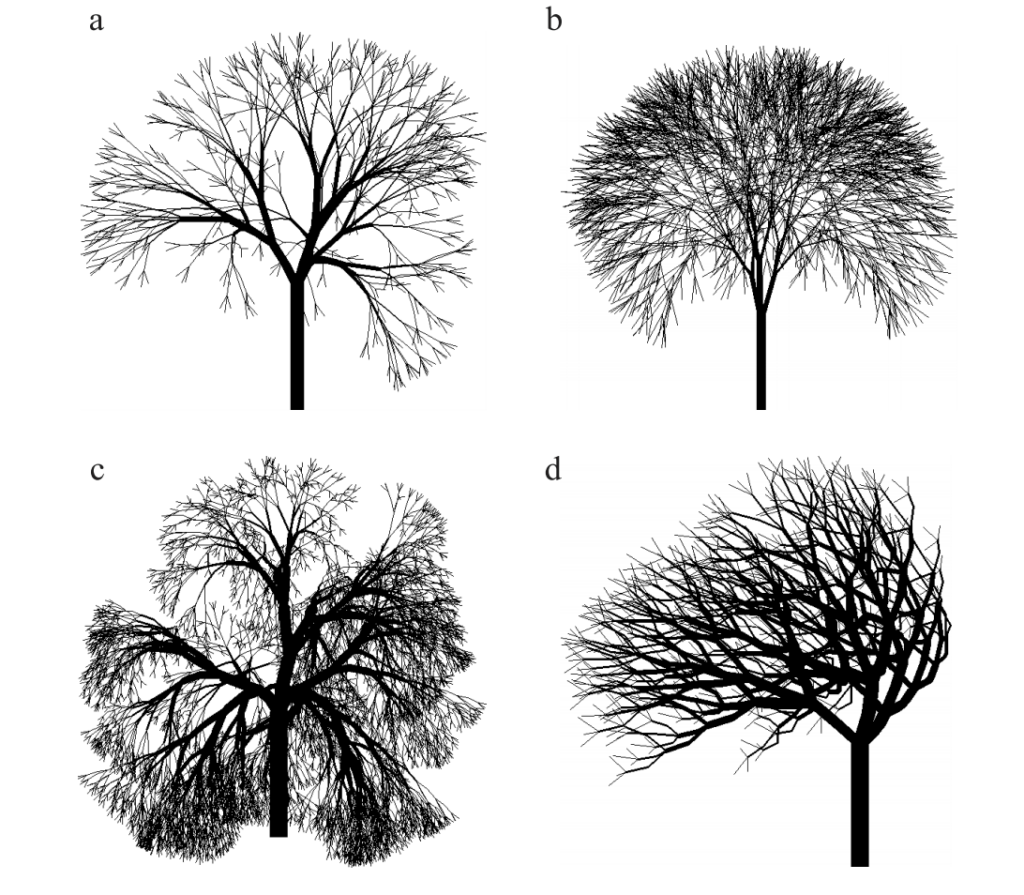
L’image présentée plus tôt dans l’article avec un arbre de nuit a été générée par un système de grammaire (plus complet que celui présenté ici). Ce lien présente les règles utilisées pour générer l’image. Les résultats obtenus par ces méthodes peuvent être superbes. En modifiant légèrement les règles de grammaire, on peut générer des images différentes.


Approches basées sur des automates cellulaires
Les automates cellulaires sont des modèles de calculs discrets basés sur des grilles. Inventés et développés dans les années 50 principalement par John Von Neumann, ils ont principalement été étudiés en informatique théorique, en mathématique ainsi qu’en biologie.
Un automate cellulaire est donc basé sur une grille. Le principe est que chaque cellule qui compose la grille peut présenter différents états (par exemple deux états possibles : un état vivant et un état mort). Les états des cellules évoluent en fonction de l’état des cellules voisines à un instant donné. Dans les automates cellulaires, le temps avance de façon discrète, c’est à dire pas à pas.
Prenons l’exemple de l’automate cellulaire le plus célèbre : Le jeu de la vie de Conway pour mieux comprendre.
Le jeu de la vie peut être décrit par deux règles simples. A chaque étape, l’état d’une cellule évolue en fonction de l’état de ses huit voisines :
- Si une cellule est morte et qu’elle a exactement trois voisines vivantes, elle passe à l’état vivant.
- Si une cellule est vivante et qu’elle a deux ou trois voisines vivantes elle garde son état, sinon elle passe à l’état mort.
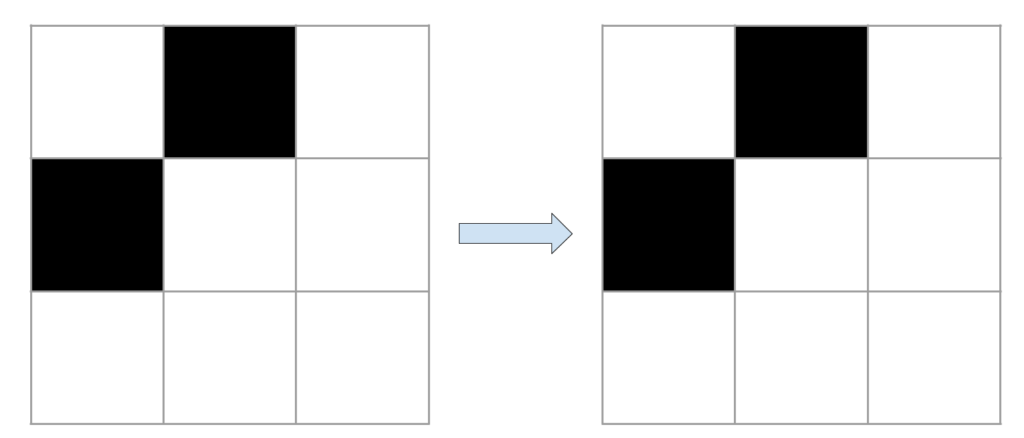
Prenons quelques exemples visuels. Les cellules vivantes sont représentées en noir et les cellules mortes en blanc. Pour chaque exemple, c’est l’état de la cellule du milieu qui nous intéresse.
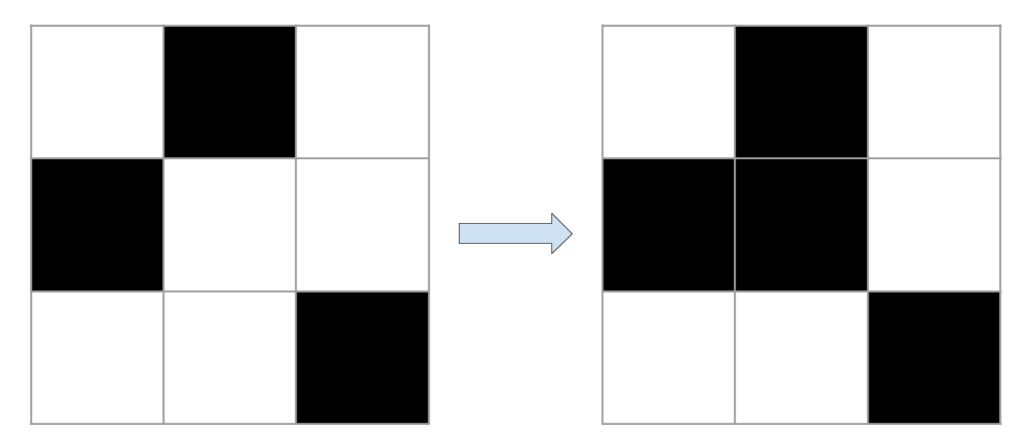
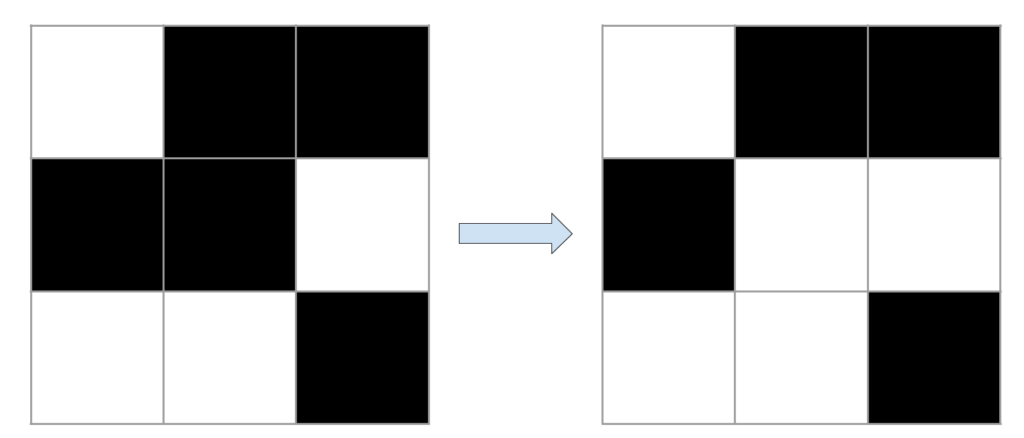
Les exemples présentés ci-dessus sont très simples puisque l’on s’intéresse seulement à la case du milieu d’une grille de taille très réduite. En général, quand on étudie le comportement des automates cellulaires, on utilise des grilles bien plus grandes. Dans ces grandes grilles, des formes plus complexes peuvent apparaître et évoluer. Par exemple avec les bonnes conditions initiales, il est possible de créer des formes qui se déplacent dans la grille. On appelle ces formes des vaisseaux. En considérant des grilles plus grandes et des conditions initiales plus complexes, des structures beaucoup plus importantes peuvent évoluer. Quand les grilles deviennent trop grandes, en général on ne représente plus les délimitations entre les cellules pour pouvoir mieux visualiser.

Voici un exemple de vaisseaux beaucoup plus grand qui laisse dans son sillage des objets capables de générer de nouveaux petits vaisseaux en diagonales. On voit bien qu’une grande complexité peut apparaître d’un automate avec des règles très simples (seulement deux règles pour le jeu de la vie).
Il est possible de construire tout un tas de machine dans le jeu la vie et même des ordinateurs fonctionnels (Voir ce lien pour un exemple). Ils sont d’une complexité énorme et extrêmement lents mais ils prouvent qu’il est possible d’obtenir des systèmes très complexes à partir de règles très simples. Tous les éléments d’un ordinateur (la mémoire, l’unité de calcul, le programme etc..) sont construits grâce à différents types d’objets qu’il est possible d’obtenir dans le jeu de la vie. Par exemple, les bits d’informations dans ces ordinateurs sont représentés par des petits vaisseaux. Pour ceux qui souhaitent en apprendre plus sur le jeu de la vie, vous pouvez aller voir cette excellente vidéo.
Les objets dans le jeu de la vie présentent en général des comportements qui ressemblent à ceux que l’on retrouve dans la nature puisque leur évolution est basée sur des règles simples,. Les automates cellulaires ont donc beaucoup servi à modéliser des systèmes environnementaux. C’est donc pour cette raison qu’ils sont intéressants dans le cadre de la génération procédurale de contenu.
Ils ont ainsi été utilisés dans les jeux vidéo pour modéliser de la pluie, du feu, des écoulements de fluides ou encore des explosions. Cependant, ils ont aussi été utilisés pour de la génération de cartes ou de terrain.
Par exemple, dans un jeu d’exploration de cave en 2 dimensions vu du dessus.
Dans ce jeu, chaque salle est représentée par une grille de taille 50*50 cellules. Chaque cellule peut présenter deux états : vide ou roche.
L’automate cellulaire est défini par une seule règle d’évolution:
- Une cellule devient ou reste de type roche si au moins 5 de ces voisins sont de type roche, sinon elle devient ou reste vide.
L’état initial est créé aléatoirement, chaque cellule ayant 50% de chance d’être dans l’un des deux états.
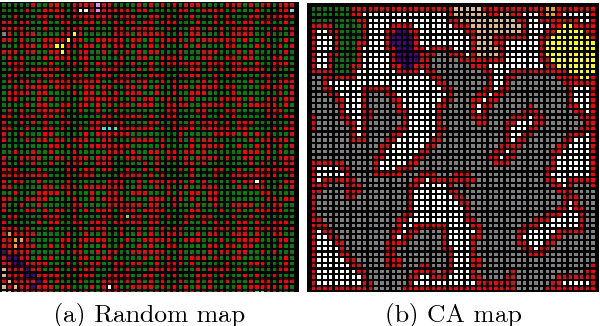
En faisant évoluer la grille depuis son état initial (à gauche) durant plusieurs pas de temps, on obtient un résultat comme sur l’image de droite avec des cases de vides en gris au milieu et des cases de roches en rouge et blanc. Les autres couleurs indiquent des zones de vides qui ne sont pas accessibles car entourées de roche. On remarque que les automates cellulaires permettent de représenter l’érosion.
Pour obtenir des zones plus grandes, on peut générer plusieurs grilles et les regrouper ensuite dans une nouvelle grille plus grande.
En changeant le nombre de cellules à considérer, les règles de l’automate ainsi que le nombre de pas d’évolution on peut obtenir différents types de résultats.
Les automates cellulaires (et les algorithmes constructifs en général) ont l’avantage de présenter un petit nombre de paramètres. Ils sont donc relativement simples à comprendre et implémenter. Cependant, il est difficile de prévoir l’impact sur le résultat final du changement d’un paramètre puisqu’en général les paramètres impactent plusieurs éléments du résultat généré. De plus il n’est pas possible d’ajouter des critères ou des conditions sur le résultat. On ne peut donc pas assurer la jouabilité ou la solvabilité des niveaux générés puisque les caractéristiques de gameplay du jeu sont indépendantes des paramètres de l’algorithme. Il est donc souvent nécessaire d’ajouter une couche de traitements pour corriger les éventuels problèmes. Ainsi dans l’exemple précédent avec l’automate cellulaire il fallait créer des tunnels manuellement si les grilles générées ne présentaient pas de chemin.
Nous allons donc nous intéresser dans l’article suivant à des méthodes plus complexes, basées sur de la recherche ou du Machine Learning et qui permettent entre autres d’ajouter des conditions et des critères sur les résultats générés.
Approches de génération procédurale avec de l’IA
Maintenant que nous avons vu les principales approches classiques appelées méthodes constructives, intéressons nous aux approches basées sur l’IA. Ces approches peuvent être hybrides et mixer de l’IA avec des méthodes plus classiques comme celles présentées précédemment. La plupart des méthodes présentées dans cette partie ne sont pas encore vraiment implémentées dans des jeux commerciaux mais il semble assez probable qu’elles fassent peu à peu leur apparition puisqu’elles permettent d’aller encore plus loin dans la génération procédurale.
Méthodes basées sur de la recherche
On l’a vu dans les articles précédents, les algorithmes de recherche sont une partie importante de l’IA, on les retrouve donc naturellement dans le domaine de la génération procédurale. Avec cette approche, un algorithme d’optimisation (souvent un algorithme génétique) recherche du contenu répondant à certains critères définis en amont. L’idée est de définir un espace des possibilités qui correspond à l’ensemble du contenu qu’il est possible de générer pour le jeu. On considère qu’une solution satisfaisante existe dans cet espace et l’on va donc le parcourir avec un algorithme afin de trouver ce contenu satisfaisant. Trois composants principaux sont nécessaires pour ce type de génération procédurale :
- Un algorithme de recherche. C’est le cœur de l’approche. En général un algorithme génétique simple est utilisé mais il est possible d’utiliser des algorithmes plus poussées qui peuvent prendre en compte des contraintes ou se spécialiser sur un type de contenu particulier.
- Une représentation du contenu. C’est la façon dont le contenu généré sera vu par l’algorithme de recherche. Par exemple pour de la génération de niveau, les niveaux pourraient être représentés sous la forme de vecteurs contenant des informations comme la géographie du niveau, les coordonnées des différents éléments présents dans le niveau ainsi que leur type etc.. Il faut qu’à partir de cette représentation (souvent vectorielle), il soit possible d’obtenir le contenu. L’algorithme de recherche parcourt l’espace des représentations pour trouver le contenu pertinent. Le choix de la représentation impacte donc le type contenu qu’il sera possible de générer ainsi que la complexité de la recherche.
- Une ou plusieurs fonctions d’évaluation. Il s’agit de modules qui regardent un contenu généré et qui mesurent la qualité de ce contenu. Une fonction d’évaluation peut par exemple mesurer la jouabilité d’un niveau, l’intérêt d’une quête ou encore les qualités esthétiques d’un contenu généré. Trouver de bonnes fonctions d’évaluations est souvent une des tâches les plus difficile lorsque l’on fait de la génération de contenu avec de la recherche.
Les méthodes basées sur la recherche sont sans aucun doutes les méthodes les plus versatiles puisque quasiment n’importe quel type de contenu peut être généré. Cependant, elles présentent aussi des défauts, le premier étant la lenteur du processus. En effet, chaque génération de contenu prend du temps puisqu’il faut évaluer un grand nombre de contenus candidats. De plus il est souvent assez difficile de prévoir le temps que mettra l’algorithme pour trouver une solution satisfaisante. Ces méthodes ne sont donc pas vraiment applicables dans les jeux où la génération du contenu doit être faite en temps réel ou très rapidement. De plus pour obtenir de bons résultats il est nécessaire de trouver une bonne combinaison d’un algorithme de recherche, d’une représentation du contenu et d’une façon d’évaluer ce contenu. Cette bonne combinaison peut-être difficile à trouver et nécessiter un travail itératif.
Tout cela étant assez théorique, prenons un exemple. Un des cas d’usage où ce genre d’approche peut être intéressant est la création et l’agencement automatique de pièces. L’idée est d’être capable d’agencer de façon cohérente une pièce à partir d’un certain nombre d’objets spécifiés en amont.
Arranger de façon cohérente et fonctionnelle du mobilier dans une pièce est une tâche complexe, qui doit considérer de nombreux paramètres comme les relations de dépendance entre différents objets, leur relation spatiale par rapport à la pièce etc.. Il est donc nécessaire de trouver une représentation des données qui capture ces différentes relations.
Représentation des données
Pour chaque objet, on assigne ce que l’on appelle une bounding box, c’est à dire une délimitation en 3 dimensions de l’objet. On assigne aussi pour chaque objet un centre, une orientation, et un sens (par exemple un canapé à une face avant et une face arrière). On considère aussi pour certains objets un cône de vision (par exemple il ne doit pas y avoir d’objets devant une TV, on défini donc un cône de vision devant la TV qui doit être vide). On assigne aussi d’autre paramètres aux objets comme la distance au mur le plus proche, la distance au coin le plus proche, la hauteur, l’espace nécessaire qu’il faut laisser devant l’objet pour qu’il soit fonctionnel etc… Une pièce est donc représentée par l’ensemble des paramètres des différents objets.
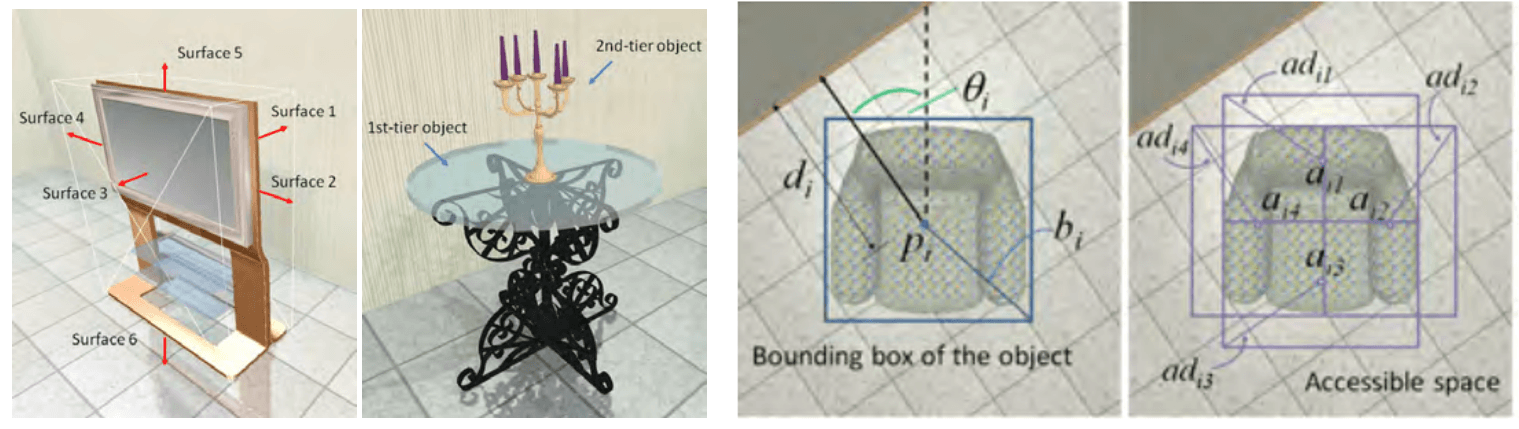
Fonction d’évaluation
Pour savoir si une pièce est cohérente ou non, on a besoin d’une fonction qui regarde la représentation des données d’une pièce et qui retourne un score. Pour savoir ce qu’est une pièce satisfaisante, on utilise un ensemble de pièces aménagées à la main par un humain. On extrait des caractéristiques pertinentes pour le placement des différents objets de la pièce. Ainsi, on observe les relations spatiales entre les différentes objets. Par exemple une TV est toujours contre un mur avec un canapé en face, une lampe est souvent posée sur une table, l’accès à une porte doit être dégagé etc..
Ces différents critères sont utilisés comme référence dans la fonction d’évaluation. Celle-ci mesure l’accessibilité, la visibilité, l’emplacement ainsi que les relations entre tous les objets et regarde si ces valeurs sont cohérentes avec celle des pièces faites par des humains. Plus ces valeurs sont proches des pièces d’exemples plus le score sera bon.
Algorithme de recherche
L’algorithme de recherche utilisé est l’algorithme du Recuit Simulé qui est un algorithme très simple. Pour commencer la génération, on indique à l’algorithme les différents objets que l’on souhaite mettre dans la pièce et la recherche va permettre de trouver une disposition cohérente de ces objets. On commence avec une disposition aléatoire des objets. A chaque itération de la recherche, une petite modification de la salle est effectuée. L’algorithme autorise différentes modifications d’agencement comme déplacer un objet (rotation et/ou translation) et intervertir l’emplacement de deux objets.
Ensuite, la nouvelle disposition de la salle est évaluée par la fonction d’évaluation. Si la nouvelle disposition est meilleure que la précédente, on la garde. Si par contre elle est moins bonne, on la garde selon une certaine probabilité. Cette probabilité de garder une moins bonne solution s’appelle la température et décroît en général avec le temps. Son intérêt est d’éviter de se retrouver lors de la recherche dans ce qu’on appelle un optimum local, c’est à dire une bonne solution mais pas la meilleure. L’objectif à la fin de la recherche est d’avoir trouvé l’optimum global et donc la meilleure solution.
Avec un temps de recherche assez long, cette approche donne des résultats très satisfaisants. D’autres approches plus poussées (comme celle-ci) permettent de trouver automatiquement les objets à mettre dans la pièce.
Comme dit précédemment, ce genre d’approches n’est pas encore vraiment mise en place dans des jeux commerciaux, mais on voit tout de suite l’intérêt pour la génération d’environnement. Elles ont aussi par exemple été utilisées pour créer des cartes du jeu Starcraft ou encore dans Galactic arm race pour trouver automatiquement des caractéristiques d’armes qui plaisent au joueur.
D’autres approches de génération procédurales peuvent être combinées à des méthodes de recherche, par exemple les méthodes basées sur des grammaires. En effet, les grammaires étant une représentation du contenu, il est possible de rechercher avec un algorithme plutôt que manuellement les règles et les grammaires les plus adaptées pour générer son contenu.
Méthodes basées sur un solveur
Les méthodes basées sur un solveur sont assez proches de celles basées sur de la recherche puisqu’il s’agit aussi de chercher une solution dans un espace de possibilités, cependant la méthode de recherche est différente. Au lieu de chercher des solutions complètes de plus en plus pertinentes, ces méthodes cherchent d’abord des solutions partielles afin de réduire au fur et à mesure l’espace des possibilités pour trouver au final une solution complète satisfaisante. Ici la recherche est posée comme un problème de satisfaction de contrainte et les méthodes de résolution sont plus spécialisés (on parle de solveurs).
Ainsi à la différence de méthodes comme la MCTS vue dans l’article précédent qui peut s’arrêter n’importe quand et aura toujours une solution (probablement non optimale mais une solution quand même), ces approches ne peuvent pas être arrêtés en milieu de recherche puisqu’elles n’auront alors qu’une solution partielle au problème.
Un exemple simple de problème de satisfaction de contrainte est la résolution d’une grille de sudoku. Les contraintes sont les règles du jeu et l’espace des possibilités correspond à l’ensemble des choix possibles pour les différentes cases. L’algorithme va trouver des solutions partielles qui respectent les contraintes en remplissant au fur et à mesure la grille, réduisant ainsi les possibilités restantes. Il peut arriver avec ce genre d’approches de rencontrer une contradiction où il n’est plus possible d’avancer la résolution en respectant les contraintes. Si cela arrive, il faut alors relancer la recherche.
En général les solveurs sont assez poussés pour essayer d’éviter ces problèmes.
Prenons un exemple : l’algorithme Wave Function Collapse (WFC). Cette approche est vraiment récente, en effet elle a été proposée en 2016. L’approche peut être implémentée comme un problème de satisfaction de contrainte.
L’idée de base est de générer une grande image en 2 dimensions en se basant sur une plus petite image donnée en entrée. L’image générée a comme contrainte d’être localement similaire à l’image en entrée.
Les contraintes de similarité sont les suivantes :
- Chaque motif d’une certaine taille N*N pixel (par exemple 3*3) qui est présent dans l’image généré doit au moins apparaître une fois dans l’image de base
- La probabilité de trouver un certain motif dans l’image généré doit être le plus possible similaire à sa fréquence de présence dans l’image initiale.

Au début de la génération, l’image générée est dans un état ou chaque pixel peut prendre n’importe qu’elle valeur (couleur) présente dans l’image en entrée. On peut faire l’analogie avec une grille de sudoku où au début de la résolution une case peut prendre plusieurs valeurs.
L’algorithme est le suivant :
- Une zone de taille N*N est choisie dans l’image. Au sudoku on démarre par remplir les cases où il n’y a qu’une seule valeur possible. De façon analogue, ici la zone choisie est celle qui présente le moins de possibilités différentes. Au début de la génération toutes les zones ont les mêmes possibilités puisqu’on démarre depuis zéro. On choisit donc une zone au hasard pour démarrer l’algorithme. La zone choisie est remplacée par un motif de même taille présent dans l’image initiale. On choisit le motif en fonction des fréquences.
- La seconde phase correspond à une propagation de l’information. Comme une zone a été définie, il est probable que les pixels autour de cette zone se retrouvent plus contraints en terme de possibilité. Au sudoku, en remplissant certaines cases, on rajoute des contraintes sur les cases restantes. Ici le principe est le même puisque les motifs possibles sont contraints par l’image de base.
L’algorithme continue ainsi en alternant ces deux phases jusqu’à ce que toutes les zones de l’image générée soient remplacées.
Petit point terminologie :
En mécanique quantique, un objet peut se retrouver dans plusieurs états en même temps (cf le fameux chat de Schrödinger). On parle de superposition d’états. Cela n’est évidemment pas possible avec les objets en physique classique. Cependant, ces objets qui sont dans une superposition d’états semblent obligatoirement revenir dans un seul des différentes états quand on les observe. Il est ainsi impossible d’observer directement la superposition d’états. On appelle ce phénomène la réduction du paquet d’onde et en anglais Wave Function Collapse. C’est donc ce principe qui a inspiré le concepteur pour le développement de l’algorithme. On retrouve en effet, un petit peu cette idée dans les valeurs possibles que peuvent prendre les différents pixels qui se réduisent au fur et à mesure de l’avancement de l’algorithme.
Une version interactive d’un cas simple de Wave Function Collapse peut être trouvée sur ce site web. Il est excellent pour comprendre intuitivement le fonctionnement et particulièrement comment le choix d’une case impacte les possibilités des cases autours.
Le github de l’algorithme WFC présente énormément de ressources et d’exemples de ce qu’il est possible de faire avec cet algorithme. L’algorithme étant un problème de satisfaction de contrainte, il est justement possible d’ajouter de nouvelles contraintes (comme avoir forcément la présence d’un chemin par exemple) pour forcer un résultat différent.
L’approche Wave Function Collapse est assez simple à mettre en œuvre et permet d’obtenir de très bons résultats. C’est pourquoi elle a été très rapidement mise en application dans le monde du jeu vidéo indépendant (par exemple dans Bad North sorti très récemment et dans Caves of Qud toujours en early access).
Méthodes de Machine Learning
La génération procédurale basée sur du Machine Learning apprend à modéliser du contenu à partir de données amassées préalablement dans l’optique de générer du nouveau contenu similaire. Les données de contenu qui seront utilisées pour apprendre le modèle peuvent être créés manuellement ou éventuellement extraites d’un jeu déjà existant par exemple. Dans tous les cas, cette étape de construction d’un jeu de données est cruciale et si les données ne sont pas en quantité et en qualité suffisante les résultats seront très certainement mauvais.
Dans les approches basées sur la recherche, le résultat attendu est défini assez explicitement (à travers la fonction d’évaluation) et une recherche dans l’espace des possibilités est effectuée pour trouver une solution qui correspond aux critères demandés. Avec le Machine Learning, le contrôle sur le résultat final est moins explicite puisque c’est le modèle de Machine Learning qui va directement générer le contenu. C’est donc surtout le travail sur le jeu de données d’apprentissage qui conditionnera le résultat final.
Dans les jeux commerciaux, cette approche est encore très peu démocratisée, les développeurs optant le plus souvent pour des approches plus simples (comme WFC par exemple). La raison principale est probablement qu’il est assez difficile de construire un jeu de données suffisamment important pour bien modéliser le contenu. Cependant, la recherche dans le domaine est très active et de nombreuses nouvelles méthodes voient régulièrement le jour. Il est probable que dans les années à venir, de plus en plus de jeux se basent sur ces approches pour générer procéduralement leurs univers.
Intéressons-nous donc à quelques possibilités intéressantes offertes par le Machine Learning.
Méthodes de tuiles avec Machine Learning
Les méthodes de Machine Learning les plus simples pour la génération procédurale sont probablement les modèles de Markov et plus particulièrement les chaînes de Markov. Les chaînes de Markov sont un ensemble de technique qui apprennent les probabilités d’apparition d’éléments d’une séquence en fonction des éléments précédents de cette séquence. Ces méthodes ont notamment été utilisées dans le monde de la recherche pour générer de nouveaux niveaux dans Super Mario Bros.
Pour ce faire, les niveaux du jeu ont été découpés en bandes verticales. Ainsi, un niveau peut être représenté comme une séquence de bandes verticales. La chaîne de Markov va étudier un ensemble de niveaux de Super Mario Bros afin d’apprendre les probabilités de présence d’une certaine bande verticale en connaissant le début du niveau et donc les bandes verticales précédentes.
En choisissant une bande verticale aléatoire pour commencer le niveau puis en générant le niveau de gauche à droite bande par bande en fonction des probabilités il est ainsi possible de générer des niveaux entiers. En général, on calcule les probabilités d’une bande verticale en fonction d’un certain nombre n de bandes précédentes (Si on prend à chaque fois toutes les bandes verticales depuis le début du niveau ça devient très lourd à calculer). En prenant par exemple n=1, chaque bande est seulement conditionnée par la bande précédente. En pratique cela génère des niveau assez différents des niveaux classiques et difficilement finissables. En prenant en considération plus de bandes précédentes (par exemple 2 ou 3), on obtient des niveaux bien plus cohérents et proches de ce qu’on attend d’un niveau de Super Mario Bros.
Cette méthode donne d’assez bons résultats surtout en terme de cohérence locale, mais il est évident que sans l’accès à des niveaux existants il n’est pas possible de l’appliquer puisque qu’on ne peut pas calculer les différentes probabilités entre les bandes verticales.
De nombreuses approches mélangeant Machine Learning et tuiles ont été proposés dans le monde de la recherche. Avec ces approches, il devient possible de générer de nouveaux exemples réalistes à partir de quelques exemples seulement.
Le Machine Learning dans la génération procédurale est un axe prometteur puisqu’il permet de nouvelles approches, cependant pour obtenir des systèmes qui marchent, il est nécessaire d’avoir des données en quantité suffisante et de trouver comment représenter de façon pertinente ces données. Et quand on parle de représentation des données, en Machine Learning, il semble intéressant de se pencher sur le Deep Learning.
Le Deep Learning
Le Deep Learning, sous domaine du Machine Learning récemment apparu permet d’étendre les possibilités des modèles classiques dans de nombreux domaines. La génération procédurale en fait partie.
Les Séquences
Le Deep Learning permet de gérer les données qui sont sous la forme de séquence de manière plus performante que les algorithmes classiques grâce à un type de réseaux particuliers que l’on nomme Réseaux de Neurones Récurrents (RNN en anglais). C’est principalement avec ces réseaux que le traitement du texte (NLP en anglais) a été profondément modifié. En effet, les données textuelles sont séquentielles.
Les réseaux récurrents sont assez similaires aux réseaux de neurones classiques à la différence donc qu’ils reçoivent les données en entrée de manière séquentielle plutôt que tout d’un coup. Ainsi, un réseau récurrent appliqué sur du texte recevra les mots d’une phrase un par un dans l’ordre de la phrase. Quand le réseau traite un mot, il a donc en mémoire les informations sur les mots précédents, ce qui peut l’aider pour l’analyse.
Cependant les réseaux récurrents classiques sont assez limités en terme de mémoire. Ils ne peuvent pas garder correctement l’information plus de 5 ou 10 pas dans le temps, ce qui n’est en général pas suffisant pour analyser ou générer une phrase complète cohérente (difficile de comprendre si à la fin de la phrase, on a oublié le début).
Une variante des réseaux récurrents à été proposée en 1997 : les LSTMs (Long Short Term Memory). Ces réseaux récurrents sont plus compliqués, ils présentent un mécanisme qui permet de déterminer ce qu’il est important de garder en mémoire et ce qui peut être oublié. Grâce à ce mécanisme, les LSTMs repoussent de beaucoup les limites de mémoires des RNNs classiques et sont donc bien plus utilisés.
La génération procédurale de niveau représente parfois les niveaux sous la forme de séquence (pour appliquer des Chaînes de Markov par exemple), il est donc tout à fait possible d’utiliser du Deep Learning de façon similaire afin de générer des niveaux de jeu.
Ainsi, en représentant un niveau comme une séquence de tranche verticales et en ayant un jeu de données avec suffisamment de niveaux, il est possible d’apprendre un LSTM à générer une nouvelle séquence de tranches verticales et donc un nouveau niveau de Mario. Les LTSMs à la différence des RNNs classiques et des méthodes plus anciennes comme les Chaînes de Markov permettent de modéliser correctement des séquences assez longues. Cela permet donc d’obtenir des niveaux de Mario avec à la fois une bonne cohérence locale (que l’on obtient déjà avec les méthodes classiques) mais aussi une cohérence globale.
L’un des avantages des réseaux de neurones est qu’ils permettent de représenter les données de différentes façon. Il est donc possible de générer des niveaux de Mario autrement qu’en créant des tranches verticales. En effet, cette méthode présente quelques désavantages, le principal étant qu’il ne sera pas possible de générer un niveau présentant des tranches verticales qui n’étaient pas déjà présentes dans le jeu de données initial. Les niveaux générés risquent donc d’être assez similaires aux niveaux utilisés lors de l’apprentissage.
Une autre approche est donc de représenter un niveau de Mario comme une grille de donnée où chaque élément de la grille correspond à un bloc dans le jeu.
Avec cette représentation, on ne génère plus un niveau tranche par tranche mais bien bloc par bloc. Un niveau de Mario étant en 2 dimensions, il y a plusieurs ordres possible de génération des blocs. On peut déjà générer le niveau horizontalement ou verticalement.
La méthode horizontale commencerait par exemple par générer depuis la gauche du niveau la plus haute ligne du ciel (donc avec juste des bloc bleus) puis, une fois arrivée au bord droit du niveau retournerait au début du niveau pour générer la ligne en dessous et ainsi de suite. C’est approche n’est probablement pas la meilleure puisqu’elle rend la cohérence verticale entre différents éléments difficile à assurer. Par exemple si un nuage est présent sur deux lignes verticales, et qu’il a commencé à être généré, il faut s’assurer lors de la génération de la seconde ligne de bien le finir. Cependant, en terme de génération, la fin du nuage arrive longtemps après le début. S’il on considère qu’un niveau de mario fait 500 blocs de long, le réseau aura générer 500 blocs entre le début et la fin du nuage. Les LSTMs présentent une mémoire améliorée par rapport aux réseaux récurrents classiques mais 500 générations est probablement quand même trop long pour pouvoir assurer de bons résultats dans tous les cas. Une approche de génération verticale semble donc plus pertinente.
Avec cette approche, on génère le niveau colonnes par colonnes. Avec cette génération, il n’y a plus de problème de cohérence verticale puisque les éléments sont générés les uns à la suite des autres. Par contre évidemment, il risque désormais d’y avoir un problème de cohérence horizontale. Cependant, un niveau faisant une quinzaine de blocs verticalement, il est beaucoup plus simple de finir un objet commencé à la colonne précédente puisque seulement une quinzaine de blocs auront été générés entre temps, ce qui est tout à fait dans les cordes de la mémoire des LSTMs. Une autre approche appelée le snaking, génère les blocs en serpentant de haut en bas puis de bas en haut plutôt que de toujours générer du haut vers le bas. Avec le snaking, on diminue encore le nombre de générations entre deux colonnes et donc cela améliore encore un peu plus la cohérence des gros objets comme les rampes.

Avec la génération verticale et le snaking, il est possible de générer de nouveaux niveaux intéressants de Mario en se basant sur un nombre relativement restreint de niveaux déjà existants comme base d’apprentissage (quelques dizaines).
Mario est un jeu en 2 dimensions mais les niveaux sont très linéaires. En général il suffit d’aller de gauche à droite pour finir le niveau. C’est pourquoi générer un niveau de Mario est une tâche relativement facile. Les jeux d’explorations plus complexes où il faut explorer plusieurs chemins, revenir sur ses pas etc.. (comme les Metroid ou les Castlevania) posent bien plus de difficultés pour la génération. Dès qu’une vraie cohérence en 2 dimensions est nécessaire les approches avec des LSTMs sur des séquences montrent leurs limites. Cependant d’autres approches semblent pouvoir aborder ces problématiques. Par exemple, dans cet article très intéressant une équipe de développement explique les différentes approches qu’ils ont testés afin de réussir à générer des niveaux avec une cohérence en 2 dimensions pour leur jeu Fantasy Raiders.
Deep Dream et Style Transfert
Jusqu’ici, on s’est surtout intéressés aux réseaux récurrents et donc aux données séquentielles, mais le Deep Learning permet aussi de faire des choses jusque-là impossibles dans le domaine de l’image. En effet, les réseaux convolutionnels sont un type de réseaux de neurones présentant des performances exceptionnelles dans les tâches de traitement et de compréhension d’images. Un des premiers exemples vraiment frappant a sans doute été l’algorithme Deep Dream de Google.
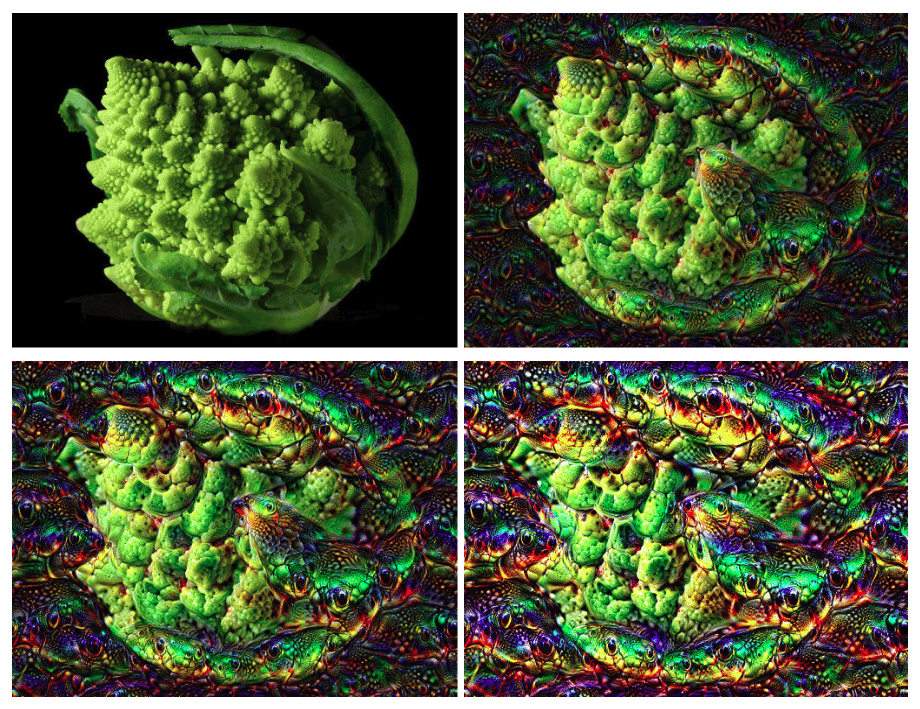
La force des réseaux convolutionnels réside dans leur capacité à représenter les données de manière pertinente. Par exemple un réseau de neurones entraîné pour faire de la classification d’image d’animaux, apprend à extraire les caractéristiques importantes des images afin de construire une représentation qui lui permettra de résoudre le problème de classification. Le réseau apprend donc à extraire les caractéristiques communes des chiens, des chats etc..
L’idée de l’algorithme Deep Dream de Google est de forcer le réseau à montrer les représentations internes que le réseau a appris. Pour ce faire, on fait fonctionner le réseau à l’envers. On lui donne une image en entrée et on lui demande d’accentuer dans l’image les éléments qu’il reconnaît. Dans l’image du ciel, si une partie d’un nuage ressemble à une tête de chien, le réseau va accentuer cela en montrant à quoi ressemble un chien dans sa représentation interne. En itérant plusieurs fois ce processus sur une même image, on obtient des résultats comme l’image du ciel où le réseau a dessiné des formes partout dans l’image. Le réseau utilisé ayant été entraîné pour reconnaître des animaux et des bâtiments, c’est ce type de formes qu’il a dessinés.
Il est aussi possible de générer complètement une nouvelle image avec Deep Dream en donnant du bruit blanc en entrée.
Cette méthode offre des opportunités en génération procédurale, notamment pour générer des textures par exemples, mais surtout elles montrent le potentiel des représentations des données des réseaux convolutionnels et du Deep Learning
Une autre méthode semble avoir des applications plus directes en génération procédurale : le Style Transfert. Le Style Transfert applique le style d’une image ou d’une œuvre sur une autre image. L’idée est d’utiliser les représentations internes des images qu’un réseau de neurones est capable de construire. En travaillant avec ces représentations, il est possible de rapprocher stylistiquement deux images tout en gardant le plus possible le contenu de l’image initiale.
Ces nouvelles approches montrent à quel point les réseaux de neurones sont capables de “comprendre” des images. Cette compréhension en profondeur permet donc une transformation et une création de contenu automatisée qu’il était impossible d’effectuer avant.
C’est pourquoi cela offre de nouvelles opportunités ou de nouvelles façon de travailler dans le cadre de la génération procédurale. Par exemple, le Style Transfert semble pouvoir accélérer le travail des artistes en appliquant un style particulier sur un ensemble de ressources très rapidement.
Cet article présente comment un développeur créatif a réussi à appliquer le style d’un film du studio Ghibli (Le Château ambulant) sur un terrain en 3D généré procéduralement.
Pour l’instant, l’utilisation de ces méthodes nécessite encore beaucoup de tâtonnements. Pour pleinement en tirer parti et voir une réelle utilisation dans les jeux vidéo, il faudra probablement trouver des moyens simples et fiables pour collaborer entre l’artiste et l’algorithme, mais à l’heure actuelle ces méthodes sont déjà assez prometteuses.
Les GANs
Les deux approches précédentes sont intéressantes mais lorsque l’on parle de génération et de Deep Learning, c’est un autre type d’architecture en particulier qui sort du lot : Les GANs (Generative Adversarial Networks ou Réseaux Antagonistes Génératifs).
Un GAN est une architecture regroupant deux réseaux de neurones antagonistes. En entrée de ces réseaux, on fournit un jeu de données de contenu (souvent des images). Un des deux réseau a pour tâche de générer du contenu similaire à celui du jeu de données en entrée et l’autre réseau doit réussir à distinguer les vrai données de celles générées par le premier réseau. L’apprentissage des deux réseaux est simultané et ils entrent en compétition durant cet apprentissage, ce qu’il leur permet au final de chacun s’améliorer dans leur tâche respective. A la fin de l’apprentissage, on garde seulement le réseau génératif qui est en théorie capable de générer du nouveau contenu très similaire au contenu initial.
Les GANs ont pu être utilisés par exemple pour générer des niveaux du jeu DOOM (1993). Pour ce faire, les chercheurs se sont basés sur plus de mille niveaux du jeu créées par la communauté. Pour chacun des niveaux, ils ont extrait plusieurs images décrivant l’agencement des murs, des plafonds, des objets, des ennemis etc.. Chaque niveau est donc entièrement décrit par 6 images vu du dessus. Le GANs est entraîné sur ces images et à la fin de l’apprentissage est capable de générer de nouvelles images qui sont ensuite transformée en niveaux.
Dans cette vidéo, on peut voir les images générées par le réseau au fur et à mesure de l’apprentissage. Au début, le GANs génère des niveaux informes, puis au fur et à mesure, ils ressemblent de plus en plus à des niveaux générés par l’humain. A la fin de la vidéo, on les voit jouer dans un des niveaux générés.
Les GANs ont probablement attiré l’attention du grand public pour la première fois avec l’algorithme pix2pix qui permet de transformer une image. Par exemple, on peut passer d’une image en noir et blanc à sa version colorée, d’une image esquissé à sa version réaliste ou encore d’une image de jour à la même image de nuit.
Pour pouvoir apprendre ce réseau, il faut déjà disposer d’un jeu de données de paires d’images (par exemple, une paire correspond à une esquisse dessiné et l’image complète correspondante).
Durant l’apprentissage, le générateur prend en entrée une esquisse et génère une image complète. Le discriminateur regarde la paire d’images obtenue (l’esquisse et l’image générée) et essaie de déterminer si la paire provient bien du jeu de données initiales ou s’il y a eu génération de l’image. Les deux réseaux s’améliorent au fur et à mesure de l’apprentissage et à la fin on obtient un générateur capable de transformer n’importe qu’elle esquisse en image. Une des versions de cet algorithme qui a bien plus est Edges2cat qui a été entraînée sur des paires d’images de chat.
En mettant en entrée une esquisse assez détaillée, on obtient un résultat photo-réaliste. Quand on est moins talentueux et que l’on donne une esquisse comme celle du bas, les résultats sont moins probants, mais correspondent cependant bien à ce qui est demandé au réseau.
De façon assez étonnante, même en donnant des esquisses qui ne représentent pas du tout des chats, le réseau arrive à s’en sortir et essaie de générer un chat avec la forme demandée.

Cette approche a bien sur été utilisée pour faire de la génération procédurale de terrain. On l’a vu précédemment la génération procédurale de terrain passe souvent par du bruit de Perlin ou ses variantes (comme l’uber noise pour No man’s sky) avec des résultats assez inégaux, puisque beaucoup d’ajustement manuel est souvent nécessaire.
Avec une méthode très proche de pix2pix, il est possible d’apprendre un réseau capable de passer d’une esquisse très simple de terrain à un terrain modélisé en 3 dimensions. Il suffit ensuite de travailler sur l’esquisse pour modifier le résultat en 3D, ce qui permet de gagner beaucoup de temps. Dans cette courte vidéo, on voit comment cette méthode est utilisée en temps réel pour générer des terrains réalistes.
Les GANs sont un sujet de recherche assez florissant (la liste des différentes variantes de GANs publiée est assez impressionnante), et leurs cas d’utilisations sont variés. Il est impossible de présenter toutes les initiatives liées aux jeux vidéo, mais en voici une dernière assez intéressante. Se basant sur le CycleGAN (en quelque sorte une version améliorée de pix2pix), cette méthode applique le style graphique d’un jeu dans un autre jeu. Les résultats sont assez impressionnants, cet article donne plus de détails.
Pour finir
Les approches de génération procédurale basées sur l’IA et principalement celles avec du Deep Learning semblent vraiment prometteuses, mais elles ne résolvent clairement pas tous les problèmes. En effet, le Deep Learning est bien adapté aux données naturelles comme des images, du texte ou du son, mais moins aux données avec des contraintes structurelles fortes.
Par exemple, les GANs ont encore tendance à générer de temps en temps des images impossibles comme des araignées avec beaucoup trop de pattes ou des balles de tennis-chien.

Quand on veut générer le niveau d’un jeu, ce genre de génération erronée pose problème. En effet, un très beau niveau qui n’est pas finissable n’a que peu d’intérêt. Les problématiques posées par la génération procédurale de contenu dans les jeux vidéo sont donc quelque peu différentes de celles de la génération d’images ou de texte simples et il faut donc adapter les méthodes. Cependant, le travail de recherche sur DOOM a prouvé que c’était possible d’utiliser les GANs pour ce genre de cas d’usage.
Sans être des outils fiables a 100%, il est clair que ces méthodes semblent pouvoir accélérer ou faciliter le travail des développeurs et des artistes. Il est difficile de prévoir si les approches avec du Deep Learning vont remplacer les approches plus classiques, mais il est évident qu’elles apportent de nouvelles perspectives et inspiration sur les méthodes de génération de contenu.
Quoi qu’il en soit, il est probable que dans le futur la majeure partie du développement des jeux sera automatisée et les humains s’occuperont des tâches les plus créatives. Pour ceux intéressés pour aller plus loin, ce github regroupe beaucoup de ressources intéressantes sur la génération procédurale.
Les jeux vidéo pour faire avancer l’Intelligence Artificielle
Récemment, beaucoup de médias ont abordé les thématiques d’IA et de jeux vidéo, en présentant des agents capable de rivaliser ou de battre des joueurs professionnels sur des jeux vidéo complexes notamment Dota 2 ou très récemment Starcraft 2 avec l’algorithme AlphaStar.
Jusqu’ici nous nous sommes surtout intéressés à ce que l’IA pouvait apporter au monde du jeu vidéo. Nous avons vu comment elle pouvait permettre de créer des mondes plus grands, plus vivants, plus cohérents etc.. Cependant la relation entre les deux domaines ne s’arrête pas là. Les jeux vidéo peuvent ainsi être un moyen d’améliorer et d’accélérer la recherche en IA. Dans cette partie, nous allons donc nous intéresser au jeu vidéo en temps que médium de recherche en IA en présentant quelques réussites importantes du domaine.
L’intérêt des jeux vidéo
En quoi les jeux peuvent-ils aider à développer de meilleurs systèmes d’IA et pourquoi les chercheurs s’intéressent-ils tant aux jeux vidéo ? L’objectif de la recherche en IA est de produire des agents de plus en plus complexes capables de comprendre leur environnement, de raisonner et de prendre des décisions complexes. À terme l’idée est d’avoir des agents capables de prendre des décisions importantes (par exemple économiques, environnementales etc..) en prenant en considération plus de paramètres qu’il est possible pour un humain de le faire.
La meilleure approche que nous ayons pour l’instant pour atteindre ces objectifs est de se baser sur un apprentissage. Ainsi, plutôt que de dire explicitement à l’agent comment il doit agir, on va essayer de lui faire apprendre de lui-même un comportement. On parle de Machine Learning et plus particulièrement d’apprentissage par renforcement. Il s’agit d’un framework d’apprentissage très ouvert qui permet d’obtenir de bons résultats sur des tâches variées. Cependant, pour mettre en place cet apprentissage, il faut des données. Beaucoup de données. Et il faut aussi souvent expliciter un objectif précis pour orienter l’apprentissage.
Les problématiques du monde réel sont en général assez difficiles à représenter dans ce framework puisqu’il n’y a souvent pas de grands volumes de données accessibles, ni d’objectifs bien définis.
Les jeux sont donc très propices à l’apprentissage d’IA puisqu’ils peuvent être assez analogues au monde réel tout en proposant des objectifs très clairs (par exemple battre le joueur en face, ou maximiser un score). Ainsi, le jeu Starcraft représente un environnement partiellement observable ou le joueur doit prendre des décisions stratégiques sans avoir accès à toutes les informations. Cet environnement peut-être rapproché en terme de complexité à des scénarios compétitifs du monde réel comme la logistique ou la gestion de chaîne d’approvisionnement par exemple.
De plus, les jeux peuvent être joués un très grand nombre de fois puisque ce sont des programmes, ce qui permet de générer énormément de données. On peut aussi accélérer le processus en parallélisant l’apprentissage sur des centaines ou des milliers d’instances du jeu en même temps.
Transférer directement un apprentissage effectué dans un jeu vidéo à une problématique du monde réel est quelque chose de difficile. Cependant, les méthodes inventées pour résoudre les problèmes dans les jeux s’avèrent souvent utiles aussi pour d’autres problématiques du monde réel.
Par exemple, la méthode Monte Carlo Tree Search (inventée pour le jeu de Go) dont nous avons parlé dans les articles précédents a déjà été appliquée à des problématiques du monde réel comme la planification de trajectoires interplanétaires de sondes spatiales. De même l’algorithme d’apprentissage par renforcement développé par OpenAI pour jouer à Dota2 a pu être utilisé quasiment directement pour apprendre dans une simulation à une main mécanique à contrôler et déplacer des objets.
Les développeurs d’OpenAI ont même réussi à transférer ce qui avait été appris dans cette simulation et à l’appliquer au monde réel. Ainsi, ils ont appris à une véritable main mécanique à contrôler des objets en faisant l’apprentissage dans une simulation grâce à ue algorithme développé pour un jeu vidéo.
L’évolution des médias
Les jeux (principalement les échecs) ont depuis longtemps été considérés comme “la drosophile de L’IA« . La drosophile ou “mouches des fruits” a été énormément utilisée dans les laboratoires pour effectuer de la recherche en génétique. Même si elle ne présente pas d’intérêt en soit, elle est très pratique pour la recherche puisqu’elle se reproduit très rapidement et elle est simple à nourrir et à conserver. Il est donc facile de tester et comparer rapidement différentes expérimentations.
Les jeux de la même façon fournissent un environnement simple et stable pour mesurer les performances des différents algorithmes d’IA. Les jeux de dames puis les échecs ont donc longtemps servi de benchmark pour la recherche en IA. Cependant, la recherche évoluant, lorsqu’un jeu devient trop simple à résoudre avec les méthodes actuelles, on trouve un jeu plus difficile pour le benchmark. Ainsi le jeu de Go a remplacé les échecs et les jeux vidéo comme Starcraft II ou Dota 2 remplacent le jeux de Go. L’intérêt de la recherche en IA pour les jeux vidéos reste ainsi relativement récent. La majorité des compétitions et des benchmarks d’IA effectués sur des jeux vidéos datent de dix dernières années.
L’intérêt du grand public
Les jeux sont de bon médiums puisqu’ils suscitent l’intérêt du public. Il suffit de voir l’engouement généré par les compétitions d’e-sport sur les plus grands jeux pour se rendre compte de l’importance du phénomène. De plus les oppositions entre IAs et humains ont toujours fasciné ou au moins intéressé la plupart d’entre nous.
Ainsi, les jeux permettent de mesurer l’évolution des performances des algorithmes d’IA de manière accessible pour tout le monde. Savoir qu’un algorithme a battu le champion du monde aux échecs est probablement plus parlant que de savoir que l’état de l’art en classification d’image est de 2.25% en top-5 error sur ImageNet.
Un autre point plus matérialiste est qu’en intéressant le grand public aux problématiques de l’IA, on diminue le risque de voir venir un nouvel hiver de l’IA (un gel des investissements dans l’IA).

La recherche en IA
Avant le Deep Learning
Le jeu Pac-Man a été assez important dans le développement de l’intérêt pour les jeux vidéo dans le milieu de la recherche en IA. Ainsi, Pac-Man a été considéré comme un problème intéressant pour l’IA dès le début des années 90, mais la recherche à réellement commencé dessus au début des années 2000. Les premières approches pour jouer aux jeux se basaient sur des algorithmes génétiques et des réseaux de neurones simples.
Rapidement, la recherche est passée sur le jeu Ms. Pac-Man qui rajoutait un petit peu d’aléatoire dans le déplacement des fantômes, ce qui rend le problème plus difficile d’un point de vue algorithmique. L’intérêt croissant des chercheurs pour Ms. Pac-Man a ainsi permis la création de deux compétitions basées sur le jeu. La première, la “Ms. Pac-Man AI Competition” eut lieu de 2007 à 2011 et l’objectif était de développer un agent faisant le meilleur score possible dans le jeu. La deuxième compétition, “Pac-Man vs Ghosts competition” eut lieu de 2011 à 2012 est permettait de développer des agents pour contrôler les fantômes. Les agents contrôlant Pac-man et ceux contrôlant les fantômes jouaient ainsi les uns contre les autres.
Ces deux compétitions ont permis d’améliorer certains domaines, notamment les algorithmes génétiques, mais c’est surtout la méthode MCTS (encore elle) qui fut beaucoup développée grâce à ce jeu. Des approches à base d’apprentissage par renforcement furent testées mais sans grand succès par rapport aux autres approches.
L’intérêt pour la communauté scientifique sur ces compétitions, lança en quelque sorte le domaine et ainsi des compétitions sur d’autres jeux furent créés. Aujourd’hui l’intérêt en IA pour Ms. Pac-Man est retombé, mais le jeu fut important pour le domaine.
Un autre jeu important fut Super Mario Bros. avec “The Mario AI Competition” qui eu lieu de 2009 a 2012. La compétition fut d’abord orientée vers la création d’agents pouvant jouer au jeu comme pour celles sur Ms. Pac-Man. Le jeu étant très différent, cela présentait une alternative intéressante d’un point de vue de la recherche. De nombreuses solutions furent proposées, notamment des approches classiques à base d’apprentissages par renforcement, d’algorithmes génétiques et de réseaux de neurones, mais la première place fut remporté à la surprise générale par un agent implémentant un simple algorithme de recherche A*. Cette vidéo permet de voir l’agent en action. Cela mit en avant le fait qu’un algorithme très simple mais bien implémenté peut faire mieux que des solutions plus complexes. Les années suivantes, des niveaux plus labyrinthiques de Mario furent proposés et l’algorithme A* montra rapidement ses limites.

En 2010, une tâche de génération procédurale sur le jeu fut proposée. Voir la partie 3 de cette série et cet article pour avoir plus de détail sur les solutions proposées. Ainsi, l’IA dans les jeux vidéo ne se limitait plus simplement à faire des agents jouant bien aux jeux.
En 2012, une autre approche de recherche fut proposée : mettre en place des agents qui jouent exactement comme des humains. L’objectif est qu’une personne extérieure regardant la manière de jouer ne puisse pas déterminer si c’est un humain ou une IA qui joue. On parle donc de test de Turing pour un jeu puisque c’est une variante du test de Turing classique.
Cette tache sur le jeu Mario n’eu lieu qu’une année et les agents ne furent pas capables de passer le test.
Cependant, cette tâche fut aussi proposée sur d’autres jeux, notamment sur Unreal Tournament 2004 entre 2008 et 2012. Sur ce jeu deux agents ont réussi à passer le test en 2012. Les deux agents apprenaient à imiter les comportements humains jusqu’à présenter un comportement quasiment indissociable.
Depuis le Deep Learning
L’arrivée du Deep Learning en 2012 a transformé nombre de domaines en IA comme la reconnaissance d’images ou l’analyse de langage. Le monde de l’IA sur les jeux vidéo a aussi été fortement impacté principalement à travers l’évolution de l’apprentissage par renforcement.
En baisse de régime depuis le début des années 2000, l’intérêt pour le renforcement a été relancé par DeepMind en 2013 et leur solution appelée DQN (Deep Q-Network). Ils ont réussi à créer un système d’apprentissage par renforcement basé sur du Deep Learning capable de jouer à certains vieux jeux Atari 2600 aussi bien que les humains en utilisant seulement les images du jeu (comme un humain jouerait). Ils ont ensuite amélioré leur solution en 2015 (après un rachat par Google entre temps). Cette fois ci, l’algorithme joue mieux que des professionnels sur une trentaine de jeux et presque aussi bien sur une vingtaine d’autres.
Là où leur solution est intéressante, c’est qu’ils ont utilisé la même architecture avec les mêmes paramètres pour tous les jeux. Un apprentissage du réseau pour chacun des jeux est bien effectué, mais il s’agit à chaque fois du même réseau initial, ce qui est une avancé importante en Machine Learning où il est souvent nécessaire de concevoir une architecture spécifique pour chaque problème. Avoir un seul algorithme capable de développer un large panel de compétences sur des tâches variées est un des objectifs de l’intelligence artificielle générale.
Avant de s’intéresser plus en détail à leur solution, faisons d’abord un petit point sur l’apprentissage par renforcement.
Apprentissage par renforcement et Q-Learning
L’apprentissage par renforcement est la dernière approche principale du Machine Learning (avec l’apprentissage supervisé et l’apprentissage non supervisé). C’est la forme d’apprentissage la plus libre puisqu’elle ne nécessite pas de données en amont, celles-ci vont être en quelque sorte construites au cours de l’apprentissage. De nombreux cas d’usage peuvent donc être traités par l’apprentissage par renforcement. Cependant, en pratique c’est aussi l’approche la plus difficile à mettre en place et à faire fonctionner, justement parce que les données sont beaucoup plus brutes que pour les approches supervisées ou non supervisées.
L’approche reprend les notions d’agents, d’environnements, d’états et d’actions que nous avons vu dans le premier article de cette série avec les automates finis.
Pour rappel, dans un jeu vidéo, un état correspond à n’importe quelle situation qu’il est possible de rencontrer dans le jeu. En général, même les jeux simples présentent un très grand nombre d’états.
Une action correspond à une des possibilités qu’a un agent pour faire passer le jeu d’un état à un autre. Par exemple, les déplacements d’un agent sont des actions.
Ici, plutôt que de définir manuellement les actions que l’agent doit effectuer en fonction de l’état dans lequel il se trouve, on va laisser l’agent trouver lui-même les actions pertinentes à effectuer. Pour décider si une action est pertinente l’agent va se baser sur une notion appelée récompense. A chaque action effectuée, l’agent reçoit une récompense. Cette récompense va indiquer si l’état dans lequel se trouve l’agent est positif ou non. En général, on définit l’agent de façon à ce qu’il essaye de faire les actions qui sont censées maximiser ses récompenses dans le futur. Il essaie ainsi d’estimer la meilleure façon d’agir pour obtenir le plus de récompenses possible au global.
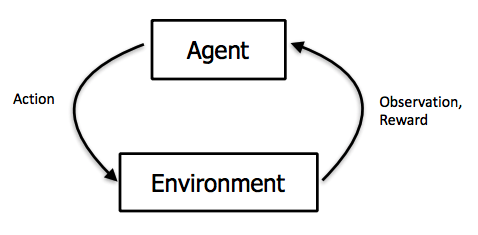
C’est le concepteur de l’algorithme qui doit définir comment les récompenses sont distribuées pour que l’apprentissage de l’agent puisse se faire. Si le système de récompenses a été bien défini, le fait de maximiser celles-ci revient à résoudre le problème d’apprentissage. Si elle a été mal défini, l’agent maximisera la récompense mais n’agira pas forcément comme prévu, c’est donc un des points cruciaux dans la réussite de l’apprentissage.
Avec l’apprentissage par renforcement, le jeu de données est construit de manière itérative en fonction des différentes actions effectuées par l’agent. Un échantillon de données correspond donc à une transition d’état, c’est-à-dire un état initial, l’action effectuée par l’agent, l’état après l’action et la récompense obtenue pour l’action. Avec beaucoup d’échantillons comme cela, il est possible pour un algorithme d’apprendre les meilleures actions à effectuer pour obtenir le plus de récompense.
Dans la vrai vie, il est difficile de construire ces échantillons puisqu’il faut réellement effectuer des actions et observer les récompenses. Par contre, dans une simulation ou un jeu vidéo, cela ne pose en général pas de problèmes.
Voyons un exemple d’algorithme avec le Q-Learning. Le Q-learning est une approche qui se base sur une fonction particulière appelée la Q-value.
La fonction Q-value peut-être considérée comme un grand tableau de valeurs qui regroupe tous les états et toutes les actions possibles associées. Pour chaque état et action possibles, on a une valeur qui représente la récompense que l’on peut espérer obtenir si l’on effectue cette action alors qu’on était dans cet état.
Ainsi, quel que soit l’état dans lequel on se trouve, il suffit de regarder les valeurs des différentes actions dans le tableau pour savoir comment se comporter.
Pour construire le tableau de valeur de la Q-value, il faut donc jouer au jeu et tester toutes les actions dans tous les états possible et observer les récompenses obtenues. Si le jeu n’est pas déterministe, c’est-à-dire si certains événements sont aléatoires dans le jeu, il faut tester chaque action dans chaque état plusieurs fois. Il est assez clair que s’il l’on joue à un jeu avec beaucoup d’états et d’actions cela devient impossible. Donc, plutôt que de construire entièrement le tableau, on va essayer d’en faire une approximation. L’idée est d’être capable de construire une fonction qui donne la valeur de récompense estimée pour n’importe quelle paire d’état et d’action mais sans avoir besoin de tout calculer.
Le meilleur outil d’approximation de fonction dont on dispose actuellement en IA, c’est le Deep Learning. L’idée du DQN (Deep Q Network) est donc de faire du Q-Learning en approximant le tableau de Q-value avec un réseau de neurones.
DQN
Cette approximation du tableau avec du Deep Learning est possible parce qu’un réseau de neurones est capable de trouver les similitudes entre des états proches. Ainsi, il ne sera pas nécessaire de tester l’ensemble des cas possibles pour estimer la Q-value de façon pertinente.
Concrétisons cela en nous intéressant au problème Atari. Les différents jeux Atari 2600 tournent sur un émulateur ce qui permet de récupérer facilement les différentes images (on parle de frames) et de brancher un algorithme qui effectuera les actions à la place du joueur.
L’algorithme a accès aux mêmes informations qu’un joueur humain pour que la comparaison puisse être cohérente. Les états du jeu sont donc simplement les frames du jeu.
Il y a quand même une petite subtilité, dans le cadre de l’apprentissage par renforcement, un état doit contenir l’ensemble des informations nécessaires à la compréhension d’une situation donnée pour pouvoir prédire la suite. On dit que le futur doit être indépendant du passé au vu du présent.
Prenons le jeu breakout comme exemple, si on défini un état comme étant une seule frame on a un problème : on ne sait pas dans quelle direction se déplace la balle. On ne peut donc clairement pas déterminer la suite du mouvement. Pour résoudre ce problème, il suffit de définir un état comme étant une succession de frames. Dans leur solution, DeepMind utilisent quatre frames pour définir un état.
Les actions possibles sont les différentes combinaisons de touches permises par les jeux. Au maximum, il y a dix-huit actions (dix,septs actions permises par le joystick de l’Atari 2600 de l’époque + l’action de ne rien faire), mais dans beaucoup de jeux le nombre d’actions est beaucoup plus restreint. Par exemple dans Pong il y a trois actions possible (haut, bas et ne rien faire)
Enfin, l’objectif à maximiser est le score du jeu. Celui-ci est visible en haut des frames donc il suffit de l’extraire pour savoir si les actions choisies ont eu des résultats positifs ou négatifs. L’objectif de l’algorithme est de prendre les décisions qui vont maximiser le score futur espéré.
Le tableau de Q-value est remplacé par un réseau de neurones qui prend en entrée un état du jeu (donc 4 frames). Le réseau va traiter ces frames et en sortie indiquer la récompense espérée pour chacune des différentes actions possibles. En prenant la meilleure action on maximise la récompense et donc le score sur le jeu.
Jusqu’ici on a décrit le fonctionnement du réseau de neurones, mais on n’a pas encore vu comment se passe l’apprentissage. En effet, au début le réseau n’a jamais joué au jeu, il n’a vu aucune frame et donc il ne sait pas estimer quelles actions sont pertinentes.
Un réseau de neurones classique (c’est-à-dire dans le cadre d’un apprentissage supervisé) s’apprend en comparant ses propres prédictions avec une vérité terrain (un label). Par exemple pour de la classification d’image, si un réseau prédit que l’image est un chien alors que c’est une image de chat, le réseau va avoir une grosse erreur de prédiction.
Cette erreur va ensuite être utilisée pour mettre à jour les différents poids du réseau afin qu’il ne fasse plus une aussi grosse erreur si jamais il revoit cette image de chat dans le futur.
Lorsque l’on fait de l’apprentissage par renforcement, on n’a pas accès à une vérité terrain puisqu’on n’a pas de label. Il faut donc trouver une autre façon de calculer ses erreurs de prédictions.
Les seules informations dont on dispose lorsque l’on fait de l’apprentissage par renforcement sont la récompense associée à l’action que l’on vient de choisir et le nouvel état dans lequel on se trouve.
On peut donc comparer les récompenses futures que l’on estimait avant de faire l’action avec les récompenses futures que l’on estime dans le nouvel état une fois que l’action est faite. En comparant ces deux estimations de récompenses futures et en prenant en compte la vrai récompense que l’on a reçu pour l’action effectuée, on peut calculer une erreur de prédiction du réseau. Le réseau s’utilise donc lui-même pour mesurer ses performances et donc s’améliorer. Cette pratique d’utiliser le même réseau à l’état suivant pour s’auto-évaluer s’appelle le bootstrapping.
Il y a quand même un soucis avec le DQN. L’idée d’appliquer des réseaux de neurones au Q-Learning n’est pas nouvelle. En effet, cela avait déjà été appliqué quand l’appellation Deep Learning n’existait pas encore et cette idée ne marchait pas. Lorsque l’on fait du Q-Learning avec un réseau de neurones, l’apprentissage a tendance à diverger à cause de ce que l’on appelle la Deadly Triad. En pratique, ce qu’il se passe c’est qu’un réseau qui s’utilise lui-même pour s’évaluer et s’améliorer présente une forte tendance à apprendre n’importe quoi.
Pour lutter contre cela et permettre quand même l’apprentissage, DeepMind a proposé deux idées :
La première idée consiste à utiliser un deuxième réseau de neurones en parallèle du premier pour estimer les erreurs. Le deuxième réseau de neurones est mis à jour beaucoup moins régulièrement que le premier. Ainsi, on ne calcule pas l’erreur de prédiction en fonction d’une cible qui change tout le temps, mais plutôt en fonction d’une cible stable générée par un réseau qui est fixé la plupart du temps. Cela permet d’aider à stabiliser l’apprentissage.
La deuxième idée est d’utiliser ce qu’ils appellent un expérience replay. On peut voir cela comme une bibliothèque contenant un grand nombre d’états, d’actions et de récompenses passées (par exemple 50000). Au lieu de faire l’apprentissage du réseau de neurones en suivant le cours du jeu, on tire au hasard dans la bibliothèque des triplets état, actions, récompenses qui vont être utilisés pour mettre à jour le réseau. L’idée avec cette méthode est d’enlever la corrélation temporelle que l’on peut avoir quand on prend les actions de façon séquentielle, ce qui permet aussi de stabiliser l’apprentissage.
Une fois le réseau appris, on peut afficher les Q-values pour différents états pour voir ce que l’agent a compris du jeu. L’agent contrôlé par l’algorithme est à droite en vert. Dans le jeu Pong il y a trois actions possibles : haut, bas et ne rien faire.
- À l’état 1, la balle est encore loin donc l’algorithme estime que les trois actions se valent en terme de récompense.
- À l’état 2, la balle se rapproche et la valeur de récompense estimée de l’action “haut” augmente alors que celle de “bas” et “ne rien faire” deviennent négatives. L’algorithme a compris que s’il ne va pas vers le haut à partir de maintenant le point sera perdu.
- À l’état 3, l’agent continue de faire l’action “haut” et touche la balle.
- À l’état 4, la balle est partie de l’autre côté et le point va être gagné donc l’algorithme a compris que quelle que soit l’action effectuée le point sera gagné. C’est pourquoi les valeurs des trois actions sont à 1.
Pour chacun des jeux, l’apprentissage s’est fait sur 50 millions de frames, ce qui correspond à près de 38 jours de jeux au total. L’agent faisant son apprentissage sur un émulateur, toutes les parties ont en pratique été jouée en accélérée, l’apprentissage n’a donc pas vraiment pris 38 jours.
Le DQN n’est pas un algorithme efficace, il a besoin d’énormément de données pour obtenir un niveau satisfaisant. Ainsi, il lui faut 38 jours pour apprendre à jouer aux jeux alors qu’un humain aurait probablement besoin de 30 secondes pour comprendre leur fonctionnement. De nombreuses améliorations de l’algorithme ont été proposées par la suite afin d’améliorer cette efficacité et permettre donc l’apprentissage de tâches plus complexes.
Regain d’intérêt pour le renforcement
Le succès du DQN a vraiment relancé l’intérêt général pour l’apprentissage par renforcement. De nombreuses variantes et améliorations de l’algorithme ont donc rapidement été développées.
Le problème posé par l’environnement Atari étant en grande partie résolu, il fallait trouver de nouveaux sujets plus difficiles. Ainsi, de nombreuses plateformes de recherche sur des jeux vidéo ont été déployées dans le but de faciliter et d’accélérer la recherche.
De bons environnements ou plateformes de recherche sont importants pour pouvoir développer et comparer des algorithmes de manière efficaces et sérieuse. La principale plateforme technique est probablement OpenAI Gym. Il s’agit d’une interface assez simple en Python qui facilite la comparaison d’algorithmes de renforcement. La plupart des plateformes de recherches qui existent sont basées sur Gym. Il n’est pas possible d’aborder toutes les plateformes, nous allons donc en présenter quelques-unes qui semblent importantes.
Les environnements d’OpenAI
On peut citer tout d’abord Universe développé par OpenAI en 2016. Universe élargissait les possibilités offertes par l’environnement Atari en proposant de travailler sur des jeux flash ou même des jeux comme GTA V. L’objectif d’Universe était de pouvoir généraliser un apprentissage fait sur un jeu à d’autres jeux ou d’autres environnement. Universe était probablement trop ambitieux et les résultats ne furent pas concluants. Le principal problème était que pour pouvoir lancer des types de jeux aussi variés, l’environnement lançait un navigateur chrome dans un docker. Du fait de ce choix d’implémentation, le système n’était pas stable et les algorithmes devaient forcément interagir avec les jeux en temps réel ce qui est gênant pour faire de très gros apprentissages.
C’est pourquoi OpenAI a développé Retro pour remplacer Universe. L’objectif de Retro était de revenir à un système plus fiable tout en proposant des environnements qui restent challengeant pour les algorithmes. Avec Retro il est donc seulement possible d’apprendre des modèles sur des jeux de Mega Drive (console de SEGA). Les jeux de la Mega Drive sont plus poussés que ceux de l’Atari, ils proposent donc un challenge plus grand. De plus l’objectif de l’environnement est encore une fois d’essayer d’apprendre des comportements qui peuvent être généralisés sur plusieurs jeux différents.
Un concours sur Retro à été mis en place à la sortie de l’environnement. Les différentes équipes participantes doivent apprendre un agent sur certains niveaux du jeu Sonic et ensuite leur agent est testé sur d’autres niveaux inédits. L’agent qui va le plus loin dans le niveau remporte la compétition.
Les résultats ont montrés que les solutions les plus performantes étaient des approches assez classiques d’apprentissage par renforcement (notamment la 2ème place qui utilise une variante améliorée du DQN) ce qui est assez encourageant car ce ne sont pas des solutions très manuelles et spécifiques au problème qui ont gagné. Par contre les résultats obtenus sont assez loin du score maximal théorique ce qui montre que le problème est encore loin d’être résolu.
Les résultats du concours ont montré que les agents sont performants sur les niveaux utilisés pour faire l’apprentissage mais assez mauvais sur de nouveaux niveaux présentant des situations inédites. Les algorithmes d’apprentissage par renforcement présentent donc des problèmes de généralisation. Les niveaux de Sonic étant assez complexes et labyrinthiques, la tâche proposée par le concours Retro est vraiment difficile. C’est pourquoi OpenAI a décidé de développer un environnement appelé CoinRun spécifiquement dédié à la généralisation. CoinRun présente un environnement de jeu de plateforme ou un personnage doit atteindre une pièce à l’autre extrémité d’un niveau.
Les niveaux de CoinRun sont en général beaucoup plus simples que ceux de Sonic mais les agents sont toujours testés sur des niveaux qu’ils n’ont pas vu durant leur apprentissage. L’objectif de cet environnement est donc d’être un bon compromis entre challenge d’un point de vue recherche et difficulté de la tâche.
VizDoom
VizDoom comme son nom l’indique est une plateforme qui permet de faire l’apprentissage par renforcement dans le jeu Doom. La plateforme permet d’obtenir plusieurs types d’informations sur le jeu, comme l’image affichée, la position et le type des différentes éléments, des informations de profondeurs ou encore des informations sur le niveau vu d’en haut. Elle permet aussi bien sur de faire tourner le jeu très rapidement pour accélérer les apprentissages.
Depuis trois ans, une compétition a lieu sur la plateforme. Il s’agit de la Visual Doom AI Competition (VDAIC). Dans cette compétition, des agents qui n’ont accès qu’aux images du jeu doivent s’affronter dans des matchs à mort. Jusqu’ici, les agents de cette compétition n’ont pas encore atteint le niveau des humains
D’autre approches assez innovantes ont été développées sur VizDoom notamment celle des World Models. Il s’agit d’une approche d’apprentissage par renforcement où un agent se construit un modèle du monde (comme une sorte de rêve) et apprend à agir dans ce modèle du monde rêvé.
En tout, la plateforme VizDoom a permis la publication de plus de 150 articles de recherche.
TORCS
TORCS (The Open Racing Car Simulator) est un jeu de simulation de course automobile. Il est utilisé en temps que jeu et en temps que plateforme de recherche. Il s’agit d’une simulation donc les agents qui jouent doivent prendre en compte de nombreux paramètres comme les arrêts au stand ou l’usure et la température des pneus par exemples. Le jeu a servi de base pour de nombreuses compétitions en IA, que ce soit la création d’agents conduisant les voitures ou d’agents construisant automatiquement de nouveaux circuits. Il y a même tous les ans un championnat du monde sur le jeu qui est organisé. Il s’agit d’un championnat entre agents ou chaque équipe propose en amont une IA qui doit concourir durant différentes courses.
Les environnements de course automobile très proches de la réalité sont intéressants puisqu’ils peuvent servir de base pour la conception d’algorithmes destinés aux voitures autonomes. Le fait que le jeu soit libre de droit est important. En effet, plusieurs projets de recherche de simulation de voiture autonome basés sur le jeu GTA V (dont un dans l’environnement Universe de OpenAI) ont dû être complètement arrêtés pour des questions de droits liés à l’éditeur du jeu Take-Two Interactive. L’environnement TORCS est moins photo-réaliste que GTA V, mais il n’y a pas de risque que les projets de recherches basés dessus soient stoppés pour des raisons similaires.
Le projet Malmo
Un autre projet de plateforme notable est le projet Malmo. L’objectif ici est de développer des algorithmes d’IA capable de comprendre un environnement complexe, d’interagir avec le monde, d’apprendre des compétences et de les appliquer sur de nouveaux problèmes difficiles. L’environnement choisi pour développer des solutions à ces problématiques est le jeu Minecraft. Minecraft est un jeu bac à sable dans lequel le joueur est beaucoup plus libre que dans la plupart des autres jeux. Les possibilités d’action sont très vastes, allant de tâches très simples comme se promener pour chercher du minerais à des tâches très complexes comme la construction de superstructures. Cette liberté fait donc de Minecraft un bon bac à sable pour les algorithmes mais il est assez probable que le projet Malmo permette des avancées en IA à plus long terme que les autres environnements.
Pour finir, tout récemment Unity a mis à disposition un environnement appelé The Obstacle Tower en proposant en parallèle un concours (qui commencera le 11 février prochain) sur cet environnement.
Il s’agit d’un jeu en 3 dimensions dans lequel l’agent doit monter dans un tour de 100 étages. Chaque étage correspond à un niveau et la difficulté est croissante. Le jeu peut être joué par des humains, mais il est destiné à la recherche. Avec quelques minutes d’entraînement, les humains qui ont testé le jeu arrivent en général à atteindre le 20ème niveau. L’environnement est donc difficile, et même pour un humain atteindre le haut de la tour semble être un challenge.
Unity propose cet environnement dans l’objectif d’être un benchmark sur une tâche difficile pour remplacer un précédent environnement difficile : le jeu Atari 2600 Montezuma’s Revenge.
Montezuma’s Revenge
Si l’on regarde les scores de l’algorithme DQN sur les différents jeux Atari 2600 et que l’on s’attarde sur le fond du classement, on remarque un jeu avec un score de 0% (ce qui correspond au score obtenu en jouant aléatoirement). Cela signifie que l’agent DQN qui est capable de jouer mieux que des joueurs professionnels sur une trentaine de jeux n’est pas capable de faire mieux que l’aléatoire sur ce jeu en particulier : Montezuma’s Revenge. Pourquoi donc ? Qu’est-ce qui rend ce jeu si différent des autres ? Intéressons-nous un petit peu à ce jeu.
Voici le premier niveau de Montezuma’s Revenge. C’est un jeu labyrinthique où le joueur doit avancer en trouvant des clés pour ouvrir des portes, tout en combattant des ennemis. Pour gagner des points dans ce jeu, il faut soit trouver une clé, soit ouvrir une porte (ce qui nécessite une clé). L’image présentée ici est la toute première salle du jeu.
Afin de pouvoir obtenir des points dans cette salle, le joueur doit donc descendre de l’échelle, aller vers la droite (le sol est un tapis roulant qui va à gauche et qui projette dans le vide), sauter sur la corde, sauter sur la plateforme de droite, descendre l’échelle, aller à gauche, sauter par-dessus la tête de mort qui bouge, monter l’échelle et enfin sauter sur la clé.
L’apprentissage par renforcement se base sur les récompenses obtenues pour estimer si les actions faites sont pertinentes ou non. Si on ne reçoit aucune récompenses, il n’y a pas de moyen de s’améliorer. Les algorithmes de renforcement commencent donc en général par jouer de façon aléatoire au début afin de voir quelles actions donnent des récompenses et lesquelles n’en donnent pas.
Le problème de Montezuma’s Revenge est qu’en jouant aléatoirement, il est quasiment impossible d’obtenir la première clé et donc impossible d’obtenir de récompense. L’algorithme DQN se casse donc les dents sur ce jeu puisque l’apprentissage ne peut même pas démarrer. Les nombreuses variantes et améliorations du DQN ont permis d’améliorer quelque peu les résultats, mais aucune ne donnent des résultats vraiment satisfaisants. Aucune n’arrive à finir le premier niveau. Pour donner un ordre d’idées, il y a 23 autres salles de ce genre à compléter pour finir le premier niveau du jeu.
Récemment, DeepMind et OpenAI ont proposé des méthodes pour jouer à Montezuma’s Revenge. Leurs méthodes ont réussi à terminer le premier niveau du jeu, ce qui est un résultat bien supérieur à ce qui était possible jusque-là. Cependant on ne peut pas vraiment considérer que leurs approches ont résolu le jeu par de l’apprentissage par renforcement pur. En effet, leurs méthodes sont basées sur des démonstrations humaines pour aider l’apprentissage.
La première méthode de DeepMind se base sur des vidéos Youtube de joueurs humains complétant le niveau. À partir de ces vidéos, ils construisent une récompense qui correspond au fait d’atteindre des zones visités par les joueurs. L’algorithme obtient donc des récompenses bien plus fréquemment ce qui permet l’apprentissage.
L’approche d’OpenAI utilise les trajectoires d’un joueur humain pour initialiser l’agent différemment. En effet, si on initialise l’agent juste devant la clé, un algorithme classique trouvera sans problème qu’il faut sauter dessus pour obtenir des points. Une fois que cette phase est apprise, on peut initialiser l’agent en bas de l’échelle sous la clé. Encore une fois depuis cette initialisation, un agent va forcément monter en haut de l’échelle. Une fois en haut, il se trouve dans une situation qu’il connaît puisqu’il l’a appris juste avant, il va donc sauter pour récupérer la clé.
En continuant ainsi l’apprentissage en éloignant de plus en plus le point de démarrage, on peut réussir à apprendre un agent capable de résoudre le premier niveau. Cependant, cela demande du travail spécifique puisqu’il faut définir plusieurs points d’initialisation qui suivent la trajectoire d’un joueur humain mais en sens inverse.
Ces deux approches sont intéressantes mais elles présentent un problème.
Utiliser des démonstrations humaines pour apprendre une tâche n’est pas un problème en soit (c’est en général comme cela que les humains apprennent de nouvelles compétences d’ailleurs) mais ça l’est dans le cadre de Montezuma’s Revenge. En effet, le jeu est déterministe, c’est-à-dire qu’à chaque fois qu’on y joue, il y aura les mêmes salles, les mêmes ennemis et rien ne sera laissé au hasard.
En utilisant une démonstration humaine sur le jeu, on ne permet pas à l’agent de comprendre la démonstration et de la généraliser à de nouvelles situations, on lui permet juste d’apprendre par cœur les trajectoires qu’il doit prendre pour résoudre le jeu. Ce qui est appris au final n’est pas comment jouer à Montezuma’s Revenge, mais plutôt comment exécuter une séquence d’actions spécifique pour finir le jeu. Ceci n’était clairement pas l’objectif initial puisque l’on cherche plutôt à créer des méthodes d’apprentissage par renforcement les plus générales possibles.
L’approche RND
Très récemment (fin octobre 2018), OpenAI a proposé un algorithme capable de parfois terminer le premier niveau sans se baser sur une démonstration humaine. Leur approche, appelée RND (Random Network Distillation) encourage l’agent à explorer son environnement en attisant en quelque sorte sa curiosité. Ainsi, ils proposent un système de récompense supplémentaire qui va encourager l’agent à visiter les zones qu’il n’a pas encore vu. En explorant ainsi de façon plus méthodique les différentes zones du jeu, il va tomber sur les éléments qui donnent les vraies récompenses, comme les clés ou les portes et ainsi l’apprentissage sera facilité.
Pour trouver les zones non visitées, l’agent se base sur ses propres prédictions de l’état futur. En effet, si l’agent est capable de prédire ce qu’il va se passer après une action, c’est qu’il est dans une zone connue. Au contraire, s’il ne peut pas prédire ce qu’il va se passer, c’est qu’il n’a jamais dû parcourir la zone. En donnant une récompense à l’agent quand il n’arrive pas à prédire le futur, on le pousse à toujours aller dans de nouvelles zones. En combinant cette approche favorisant l’exploration avec un algorithme classique d’apprentissage par renforcement, le jeu à pu être résolu.
Montezuma’s Revenge a longtemps montré les limites de nos algorithmes d’apprentissage. On a longtemps cru que pour bien résoudre le jeu, les agents devraient avoir une meilleure compréhension des différents concepts du jeu, comme ce qu’est une clé, ce qu’est une porte, le fait qu’une clé ouvre une porte, etc.
Au final, en trouvant un moyen astucieux pour explorer le niveau et avec un apprentissage suffisamment long, le jeu a pu être résolu. Il semble donc que les différents problèmes difficiles qui paraissent nécessiter des capacités humaines (comme la compréhension de concepts, le raisonnement, etc.) pour être résolu, peuvent souvent au final être résolu de manière complètement différente par les algorithmes.
L’environnement d’Unity, The Obstacle Tower est pensé pour être une sorte de successeur à Montezuma’s Revenge. Le futur nous dira si l’environnement se montre vraiment intéressant en terme de recherche en IA.
Les approches principales de DeepMind et OpenAI sur des jeux vidéo
Nous allons maintenant nous intéresser particulièrement à trois approches présentant des résultats vraiment impressionnants. Ces méthodes sont très récentes, elles ont été développées en 2018 et 2019 et ont fait beaucoup parler d’elles dans les médias. Elles sont développées par DeepMind et OpenAI qui ont des moyens en terme de puissance de calcul bien supérieur aux laboratoires de recherches académiques. Cela permet à ces équipes de s’intéresser à des sujets à la fois en temps que problèmes de recherche, mais aussi comme des problèmes d’ingénierie. Les laboratoires académiques s’intéressent en général à des problèmes plus restreints et/ou fondamentaux principalement par manque de moyens.
Les jeux concernés par ces approches sont Quake III, Dota 2 et Starcraft 2.
Quake III
La première approche est le travail de DeepMind sur le jeu Quake III. En pratique, il s’agit d’un clone maison de Quake III qui s’appelle DeepMind Lab. Le mode de jeu sur lequel ils ont travaillé s’appelle Capture The Flag (CTF ou Capture du drapeau en français). Il s’agit d’un mode ou deux équipes s’affrontent pour essayer de voler le drapeau du camp adverse et le ramener à son propre drapeau. L’équipe qui a réussi à ramener le drapeau adverse le plus de fois dans son propre camp en 5 minutes l’emporte. Cette courte vidéo de Deepmind explique le principe. Les règles sont simples, mais les dynamiques de ce mode de jeu sont complexes. Pour être performant, il est nécessaire de mettre en place des stratégies, des tactiques et surtout de jouer en équipe.
Deepmind a réussi à développer des agents capables de jouer aussi bien voir mieux que des humains à ce mode de jeu. De façon intéressante, leurs agents arrivent à travailler en équipe avec d’autres agents, mais aussi avec des humains.
Le problème posé par ce jeu s’appelle le multi-agent learning. En effet, plusieurs agents doivent apprendre à agir indépendamment tout en apprenant à interagir et coopérer avec d’autres agents. C’est une tâche difficile puisque comme les agents évoluent durant leur apprentissage, l’environnement auquel ils sont confrontés change continuellement. De plus pour que les agents apprennent réellement à jouer au mode CTF plutôt que de retenir par cœur la disposition de l’environnement, ils jouent dans des environnements générés procéduralement (et oui la génération procédurale peut aussi servir à créer un meilleur cadre d’apprentissage !).
Comme pour beaucoup d’autres approches présentées dans ce poste, les agents ont accès aux mêmes informations que les joueurs humains, c’est-à-dire simplement les informations qui s’affichent à l’écran. Les règles du CTF ne sont jamais explicitées, les agents doivent les comprendre d’eux-mêmes. De plus, les différents agents n’ont pas de moyen pour communiquer entre eux, ils doivent donc agir et apprendre indépendamment.
L’architecture des agents
Comme pour l’algorithme DQN, le cœur de l’agent va être un réseau de neurones. Ici tout est juste un peu plus complexe. Les agents doivent être capables d’être performants à plusieurs échelles de temps : ils doivent pouvoir réagir vite quand un ennemi apparaît ou que le drapeau est volé par exemple et ils doivent aussi pouvoir agir sur le plus long terme pour mettre en place une stratégie. En général, quand on a ce genre de problématiques, on s’intéresse à ce que l’on appelle l’apprentissage par renforcement hiérarchique. Ainsi, pour pouvoir proposer un tel comportement les agents sont donc basés sur un réseau récurrent hiérarchique à deux niveaux de temporalité. Les réseaux récurrents sont les réseaux que l’on utilise classiquement pour traiter des données séquentielles (comme le texte). Les plus connus sont les LSTMs. Les agents sont donc pourvus d’une hiérarchie de deux LSTMs (en pratique les réseaux utilisés sont un peu plus complexes que des LSTMs mais l’idée reste la même). Le premier voit tous les états et agit à toutes les étapes tandis que le deuxième ne voit qu’un état de temps en temps. Les deux niveaux peuvent donc traiter l’information de façons différentes. De plus, les agents sont équipés d’un système de mémoire qui leur permet de stocker les informations qu’ils jugent importantes afin de pouvoir les réutiliser au moment opportun.
En amont de ce système se trouve un réseau convolutionnel classique qui est simplement là pour comprendre les images et extraire les informations importantes (n’oublions pas que les agents jouent avec comme seule information les images à l’écran). Comme pour le DQN, un état est une succession de 4 images. Le jeu tourne à 60 images par seconde, cela fait donc 15 étapes d’apprentissage par seconde.
Les différentes actions
En sortie de la hiérarchie de LSTMs, une action pour l’agent est choisie. Dans l’environnement Atari, il y avait 17 actions possibles. Ici le jeu est beaucoup plus compliqué, les actions possibles sont continues plutôt que discrètes (on peut déplacer le viseur n’importe où sur l’écran) et elles sont combinables (on peut par exemple avancer, sauter, déplacer le viseur et tirer en même temps). Pour simplifier grandement cela, les actions ont été limitées principalement au niveau du viseur. Ainsi, il devient seulement possible pour l’agent de déplacer le viseur d’une certaine valeur verticale et/ou horizontale par rapport à la position à l’étape d’avant (Ainsi par exemple seuls les déplacements horizontaux du viseur avec un angle de 10 degrés ou de 60 degrés sont autorisés). Grâce à cette simplification, le nombre d’actions possible à chaque étape est de 540.
La hiérarchie de LSTMs choisit donc une de ces actions en fonction des images qu’elle reçoit et des informations du passé.
La récompense
Les agents ont donc un moyen de choisir des actions en fonction des états. Comme dans tout algorithme d’apprentissage par renforcement pour apprendre comment choisir ces actions de façon pertinente on utilise la récompense. Comme le but est d’apprendre aux agents à gagner au CTF, la récompense est positive si l’équipe de l’agent gagne la partie, négative si elle perd et nulle s’il y a match nul. Le problème est que cette récompense est très rare, en effet des milliers d’actions peuvent être faites avant la fin d’une partie. On tombe donc dans le même type de problème qu’avec le jeu Montezuma’s Revenge ou l’apprentissage n’est pas possible puisque l’agent n’arrive pas à faire le lien entre actions et récompenses. Il faut donc trouver un moyen de fournir aux agents des récompenses plus fréquemment. Quake III contient un système de points pour chaque joueur qui est indépendant du score de l’équipe (qui est lui basé seulement sur les captures de drapeaux). Les joueurs gagnent des points en touchant des joueurs ennemis, en capturant un drapeau, en ramenant son propre drapeau dans sa base etc..
Deepmind propose un système où l’agent se crée son propre système de récompense interne basé sur le système de points de Quake III. Avec ce système, les récompenses deviennent beaucoup plus fréquentes et l’apprentissage devient possible.
L’algorithme d’apprentissage
L’algorithme de renforcement utilisé pour l’apprentissage est l’algorithme UNREAL (aussi développé par DeepMind) qui est une amélioration de l’algorithme A3C (Asynchronous Advantage Actor-Critic) avec des tâches non supervisées pour accélérer l’apprentissage. Cet article du blog de DeepMind donne plus de détails sur cette méthode. L’algorithme A3C est lui-même une amélioration de l’algorithme DQN. Ces algorithmes sont visibles sur la figure présentant les algorithmes principaux de renforcement dérivés du DQN présentée précédemment.
L’apprentissage
On a vu comment était représenté un agent, son système de récompense et l’algorithme de renforcement utilisé. Désormais, il faut des données pour faire l’apprentissage. Une solution possible pour apprendre ce type d’agent est de le faire jouer contre lui-même. Cependant, cette approche peut être assez instable et n’apporte pas beaucoup de variété. En effet l’agent va jouer continuellement contre une version de lui-même qui sera de plus en plus forte au cours du temps, mais qui aura probablement un comportement global assez similaire sur le long terme. Afin d’amener de la diversité dans les tactiques et les stratégies de jeux, ce n’est pas un agent mais une population entière d’agents différents qui est entraînée en parallèle. Les différents agents jouent les uns contre les autres ce qui permet de stabiliser l’apprentissage. Cette population d’agent évolue dans le temps grâce à un algorithme génétique appelé PBT. Cet algorithme remplace les agents les moins performants par des versions mutées des agents les plus performants. Ainsi, l’ensemble de la population s’améliore au cours du temps. C’est aussi cet algorithme qui adapte le système de récompense interne de chaque agent. Ainsi, les objectifs les plus pertinents pour un agent ne seront peut-être pas les mêmes pour un autre agent.
L’apprentissage des agents a nécessité 450 000 parties. À la fin de cette phase ils sont bien meilleurs que les humains. Après un peu plus de 100 000 parties la population d’agents jouait au niveau d’un humain moyen.
Le système proposé par DeepMind pour jouer au Capture The Flag est donc une approche complexe à deux niveaux d’apprentissage mélangeant algorithme génétique et apprentissage par renforcement. Grâce à ce système, les agents découvrent comment équilibrer leurs objectifs individuels (leur système de récompense interne) avec l’objectif de l’équipe (la récompense finale, c’est-à-dire gagner ou perdre la partie).
Il est intéressant de noter que différents comportements stratégiques et de travail d’équipe comme ceux-ci dessus ont été découverts et compris durant l’apprentissage. Les agents une fois entraînés ont tendance à mieux coopérer avec leurs équipiers que les joueurs humains.
Dota 2
Plus ou moins en même temps que la solution proposée par DeepMind pour jouer à Quake III CTF, OpenAI à fini de mettre au point son approche pour jouer à Dota 2 en 5v5. Durant le printemps et l’été 2018, ils ont continuellement amélioré et complété leur approche, proposant des agents de plus en plus performants jusqu’au point culminant fin août : deux matchs contre des équipes de joueurs professionnels à The International 2018, la plus grosse compétition du monde sur Dota 2.
Dota 2 est un jeu de type Moba (Multiplayer online battle arena). C’est un type de jeu où deux équipes d’en général 5 joueurs chacune s’affrontent dans le but de détruire la base de l’équipe adverse. Chaque joueur contrôle un seul personnage, un héros qui présente des capacités et des pouvoirs particuliers. Au cours de la partie, les héros évoluent, devenant de plus en plus performants et débloquant de nouveaux pouvoirs. De très nombreux héros existent et chaque joueur commence par choisir le sien parmi les différentes possibilités, l’aspect stratégique commencent donc avant même le début de la partie. En effet, certains héros permettent de contrer d’autres héros et ainsi de suite. Le jeu se déroulant en 5 joueurs contre 5 joueurs, les possibilités sont énormes.
La complexité du jeu
Si l’on compare Dota2 avec le mode CTF de Quake III, la complexité est bien plus importante. En effet, là où le nombre d’actions possible à chaque instant avait été réduit à 540 sur Quake III, ici le nombre d’actions possible est de 170000 (même si en pratique à chaque instant, toutes les actions ne sont pas exécutable, l’ordre de grandeur est donc plutôt du millier d’actions).
Comme pour Quake III, il s’agit d’un jeu ou l’information est imparfaite (contrairement au Go) puisque seules les zones proches de l’équipe sont visibles. On ne sait donc pas à chaque instant ce que fait l’adversaire. De plus, le déroulement du jeu se fait en temps réel et une partie dure en moyenne 45 minutes (contre 5 minutes pour Quake III). Et le dernier point, Dota 2 est un jeu hautement stratégique, pour gagner il faut être capable d’être coordonné entre les différents membres de l’équipe et de prévoir ses actions sur le long terme. L’ensemble de ces facteurs fait de Dota 2 un jeu très complexe pour une IA, c’est donc un bon challenge pour améliorer la recherche dans le domaine.
L’approche itérative D’openAI
Devant la complexité de la tâche, OpenAI a pris la décision de partir sur une approche itérative, en proposant un agent pour une version très simplifiée et restreinte du jeu, puis en enlevant au fur et à mesure les restrictions pour arriver au final jusqu’au jeu complet.
Ainsi, ils ont commencé par proposer un agent pour le mode de jeu 1v1. Il s’agit d’un mode où chaque équipe n’est composée que d’un seul joueur, ce qui réduit grandement les possibilités du jeu. Il s’agit d’un mode de jeu moins populaire que le 5v5 mais il existe quand même des compétitions en 1v1, le mode est donc joué par des humains.
À la compétition The International 2017, leur agent a battu un joueur professionnel en 1v1 sur scène, devant de nombreux spectateurs. Les jours précédents leur agent avait aussi battu d’autres joueurs professionnels dont les meilleurs du monde. Ceux-ci décrivant l’agent comme imbattable.
À cette époque, OpenAI n’avait pas encore détaillé son approche (voulant dévoiler les informations seulement une fois l’agent prêt pour le jeu en 5v5). La seule information disponible étant que l’agent est appris entièrement en jouant contre lui-même. L’approche semble donc similaire à celle pour Quake III.
Au final, il s’avéra que l’agent n’était pas imbattable. Tous les joueurs professionnels ont évidemment voulu se mesurer à l’IA et des failles furent trouvées. En effet, l’agent était extrêmement fort face à un adversaire jouant de manière conventionnelle, mais il se retrouvait rapidement confus si celui-ci jouait de façon complètement anormale. Ainsi, avec les bonnes stratégie (non conventionnelles) tous les joueurs professionnels furent capables de battre cette version de l’agent.
OpenAI pouvant corriger ces problèmes rapidement en considérant ces stratégies durant la phase d’apprentissage de l’agent contre lui-même décidèrent d’en rester là pour l’agent en 1v1 et de commencer à travailler sur la version 5v5. La raison principale est qu’en 5v5, le nombre de stratégies imprévues comme celle trouvée par les joueurs est forcément bien plus important. Apprendre ces stratégies en les implémentant une à une durant la phase d’apprentissage n’est donc pas une solution viable. Il faut un agent capable d’apprendre à réagir de lui-même face à ces situations non conventionnelles.
OpenAI Five
OpenAI a donc continué son approche itérative de développement de son IA en enlevant des restrictions de jeu au fur et à mesure de leur succès. Chaque restriction enlevée augmente la complexité du jeu et se rapproche des règles officielles des grands tournois. L’ascension de leur agent en 5v5 – nommé OpenAI Five – est assez impressionnante. En effet, c’est seulement fin avril 2018 qu’ils ont réussi à battre une équipe de bots dont les règles sont manuelles. Ce genre de bot est très loin du niveau des bons joueurs humains. Ils étaient donc encore assez loin de l’objectif à ce moment là. Et pourtant, en juin 2018, leur agent a battu une équipe de joueurs semi-professionnels. Et finalement en août ont eu lieu les matchs contre deux équipes de joueurs professionnels. OpenAI Five a perdu les deux fois, mais les matchs étaient très serrés. Leurs agents sont donc très proches du niveau des meilleures équipes professionnelles. Les matchs en août étaient aussi les premiers avec les règles officielles. En effet, ceux de juin étaient encore joués sur une version du jeu avec des règles restreintes.
Voyons donc comment ils ont réussi cette impressionnante progression. OpenAI n’a pas encore fourni tous les détails de son implémentation mais plusieurs articles sur leur blog décrivent quand même assez précisément l’approche utilisée.
Les données
OpenAI Five utilise l’API fournie par Valve le développeur de Dota2. Ainsi, à chaque instant, toutes les informations visibles à l’écran pour un joueur humain sont accessibles pour les agents. C’est une grosse différence avec la solution pour Quake III qui elle regardait et analysait les images à l’écran. Ici, il n’y a pas cette étape de reconnaissance d’image pour obtenir les informations. Les agents ont ainsi accès à toutes les informations d’un coup (en pratique cela représente 20 000 valeurs à chaque état), contrairement aux humains qui ne peuvent pas tout regarder en même temps. Il peut y avoir débat ici sur le fait que cela soit équitable ou non par rapport aux humains, mais l’apprentissage avec les images du jeu à analyser aurait nécessité des milliers de GPUs supplémentaires.
Comme l’agent Quake III, OpenAI Five observe le jeu toutes les 4 images (parce qu’un état est une séquence de 4 images). Dota 2 tourne à 30 images par seconde donc au maximum l’agent pourrait effectuer 7.5 actions par seconde ou 450 actions par minute. En pratique, un agent effectue en moyenne entre 150 et 170 actions par minute ce qui est dans les cordes d’un joueur humain. Cependant, le temps de réaction moyen d’un agent est de 80 ms ce qui est plus rapide que le temps de réaction d’un humain.
L’architecture des agents
Chacun des cinq héros de l’équipe d’OpenAI Five est contrôlé par un agent indépendant, comme pour une équipe d’humains. Ce n’est donc pas un super agent qui contrôle tous les héros en même temps. Ainsi, chaque agent contient un modèle qui est initialement le même pour tous, mais qui peut apprendre différemment des autres en fonction des expériences encourues durant l’entraînement. Les modèles des agents sont des réseaux de neurones. Ceux-ci reçoivent à chaque étape les données fournies par l’API.
Les réseaux sont constitués tout d’abord de couches de neurones classiques dont l’objectif est de représenter les informations de façon pertinente pour que le cœur des agents puissent prendre des décisions. Les 20000 valeurs fournies par l’API sont donc agrégés et transformés par ces couches afin de ne garder que ce qui est pertinent pour l’agent.
Les cœurs des agents qui reçoivent ces données transformées sont de simples réseaux récurrents de type LSTM. Le LSTM analyse la séquence de données et contextualise ainsi le présent grâce aux évènements du passé. Grâce aux données contextualisées par le LSTM différentes “têtes” de classification estiment les actions à accomplir. Ainsi, on peut voir qu’une tête a pour objectif de choisir l’action la plus pertinente, une autre doit estimer les coordonnées en X de l’exécution de l’action, une autre les coordonnées en Y et ainsi de suite.
Le LTSM contextualise la séquence de données et les 8 têtes de classification prennent la décision de quoi faire. Le diagramme complet et non retouché se trouve ici. Dans cet article, une interface dynamique permet de faire le lien entre ce qui est affiché à l’écran et les différentes têtes.
Certains choix dans la modélisation (notamment au niveau des têtes d’actions) ont été faits en analysant les comportements des agents durant des parties. Si un certain comportement ne correspondait pas à ce qui était attendu, l’architecture du réseau était modifiée pour faciliter l’apprentissage de ce comportement.
Un point intéressant, si l’on compare cette solution avec celle pour Quake III, on constate qu’il n’y a pas de hiérarchie de LSTM à différentes temporalités pour gérer les actions à court et long terme. Il semble qu’avec un seul LSTM les agents d’OpenAI Five arrivent à gérer de la planification sur le long terme. Les chercheurs d’OpenAI eux-mêmes expliquent qu’ils pensaient cela impossible avec les approches classiques. L’apprentissage par renforcement hiérarchique (décrit pour la première fois ici) et utilisé pour Quake III leur semblait par exemple être une nécessité. Mais ce n’était visiblement pas le cas.
L’algorithme d’apprentissage
L’algorithme d’apprentissage par renforcement utilisé s’appelle Proximal Policy Optimisation (PPO). Il ne s’agit pas d’une variante du DQN comme tous les autres algorithme que nous avons vu jusqu’ici. La différence est qu’ici ce n’est pas la Q-Value qui est optimisée mais directement la politique de choix des actions. L’algorithme PPO a été proposé par OpenAI en 2017 et a depuis démontré de bonnes performances, notamment durant le concours Retro sur le jeu Sonic ou sur Montezuma’s Revenge.
Pour tout algorithme de renforcement, l’objectif est de maximiser les récompenses futures. En générale, on essaie de maximiser la somme des récompenses futures pondérées par des valeurs décroissantes. L’idée est de dire que l’ensemble des récompenses du futur sont importantes, mais que celles dans un futur proche le sont plus que celles dans un futur lointain car celui-ci est trop incertain.
En général, on prend souvent des valeurs qui décroissent exponentiellement sur 100 valeurs, ainsi à chaque instant on considère les récompenses des 100 prochaines étapes. Suivant la durée entre les étapes cela peut être une durée plus ou moins longue, mais en général cela n’excède pas quelques secondes.
Au début de l’apprentissage d’OpenAI Five, le nombre de récompenses futures considérées par l’agent est assez restreint mais au fur et à mesure le nombre augmente jusqu’à prendre en considération l’ensemble des récompenses.
Ainsi, une fois appris Dota Five essaie à chaque instant d’optimiser les récompenses qu’il estime obtenir jusqu’à la fin de la partie, ce qui permet de mettre en place des stratégies à l’échelle d’une partie entière. C’est probablement la première fois qu’un apprentissage par renforcement sur si long terme fonctionne.
L’apprentissage
Comment cela peut-il donc fonctionner si l’approche utilisée est un algorithme classique et connu de tous ? OpenAI discute de deux raisons de ce succès : l’apprentissage à très grande échelle et la présence de bons moyens d’exploration.
L’infrastructure pour faire l’apprentissage est impressionnante : 256 GPU par agent et 128 000 CPU. Avec cela, il est possible pour les agents de jouer à Dota chaque jour l’équivalent de 180 années pour un humain.
Les agents apprennent à jouer intégralement en faisant des matchs contre eux-mêmes. Durant les premières parties, les héros font un peu n’importe quoi, errant sans but dans la carte. Puis, au fur et à mesure, ils commencent à présenter des comportements plus proches de ceux des humains. Pour éviter ce qu’ils nomment “l’effondrement de stratégies”, les agents jouent 80% des parties contre eux-mêmes et 20% contre des versions d’eux même du passé. Il s’agit d’un problème similaire à la deadly triad du DQN. Ainsi en prenant des version du passé, on diminue le risque d’avoir des données d’apprentissage trop corrélées.
Avec cette approche d’apprentissage, OpenAI Five a pu devenir assez bon pour battre un bot avec des règles manuelles (en mars 2017) mais il devenait confus face à des humains. Ceux-ci jouaient de façons trop variées, présentant toujours de nouvelles situations non vues pendant l’apprentissage. On l’avait vu avec Quake III, le fait de jouer contre soi-même n’apporte pas assez de variété dans les situations, même en jouant contre des versions du passé.
Pour mieux explorer durant l’apprentissage, c’est-à-dire tester de nouvelles configurations de jeu pour voir les résultats des différentes actions, OpenAI a décidé d’ajouter de l’aléatoire dans les parties. Ainsi, dans certaines parties, les propriétés des différentes unités comme la vie, la vitesse ou encore le niveau de départ ont été modifiés aléatoirement. Ainsi, les agents se sont retrouvés dans des situations bien plus variées qu’en faisant simplement des parties normales.
Cet aléatoire forcé permit aux agents d’atteindre pour la première fois le niveau des humains. En apprenant plus longtemps et avec encore plus d’aléatoire, le niveau de Dota Five n’a fait qu’augmenter.
La récompense
Comme pour Quake III, utiliser une seule récompense en fin de partie n’est pas suffisant pour entraîner correctement les agents. Une récompense plus fréquente a donc été construite manuellement par OpenAI. Elle comprend les différents indicateurs que les humains considèrent pour connaître l’état d’une partie, c’est-à-dire le nombre de héros tués, le nombre de morts, le nombre de PNJs tués etc.. Cette récompense est interne à chaque agent mais il y a aussi une récompense globale liée à l’équipe qui correspond en gros au fait de gagner ou perdre la partie.
Les agents n’ont pas de moyen explicite pour communiquer entre eux. Pour gérer le travail d’équipe durant l’apprentissage, un paramètre permet de définir l’importance des récompenses propres à l’agent par rapport aux récompenses liées à l’équipe. Au début de l’apprentissage, les agents s’intéressent seulement à leurs propres récompenses. Cela permet aux agents d’apprendre les règles et les principes importants du jeu. Puis au fur et à mesure de plus en plus d’importance est mise sur les récompenses d’équipe pour que les agents développent des stratégie tous ensembles. Ce système est très performant puisque le travail d’équipe des différents agents est ce qui a le plus impressionné les experts observant Dota Five jouer.
Les derniers composants manuels
Les choix stratégiques en terme de combinaisons d’objets et de compétences des héros (ce qu’on appelle les builds des héros) sont pour l’instant définis manuellement. Ils ont été codés en amont et à chaque partie ils sont choisis aléatoirement. Il est probable qu’OpenAI essaie d’enlever dans le futur ces dernières étapes manuelles pour apprendre automatiquement les builds les plus adaptés à chaque situation. Il reste encore dans leur approche quelques autres fonctionnalités qui sont définies en dur. Peut-être qu’à l’été prochain à The International 2019, Dota Five sera un agent complètement automatique dont tous les paramètres seront appris automatiquement. Dans tous les cas, si OpenAI a continué à travailler sur cet agent et qu’ils organisent un match contre une équipe professionnel durant cet évènement, tout porte à croire que l’agent remportera cette fois-ci la victoire face aux humains.
Starcraft II
Starcraft II un jeu de stratégie en temps réel (RTS) dans lequel deux joueurs s’affrontent en développant une base afin d’obtenir des ressources qui leur permettent de construire différents types d’unités pour attaquer l’adversaire. Starcraft II est depuis longtemps considéré comme un grand challenge pour la recherche en IA voir le challenge ultime dans le cadre des jeux vidéo. Les joueurs de Dota diront probablement le contraire, mais quoi qu’il en soit les deux jeux sont très complexes et présentent probablement un challenge assez similaire pour une IA.
En effet, Starcraft 2 est aussi un jeu où l’information est imparfaite puisque seules les zones proches des unités du joueur sont visibles. Le déroulement du jeu se fait en temps réel et le nombre d’actions possibles à chaque instant est énorme. Il n’y a pas de stratégies toujours gagnantes dans Starcraft II. Un peu comme au jeu pierre-papier-ciseau, il y aura toujours une approche pour en contrer une autre.
De plus, pour bien jouer il faut pouvoir faire preuve de stratégie à deux niveaux de hiérarchie :
- La micro-gestion c’est-à-dire gérer de façon intelligente, rapide et précise les différentes unités que l’on a à disposition lors des combats.
- La macro-gestion c’est-à-dire gérer la stratégie globale de la partie en construisant les bonnes unités, en décidant quand attaquer, comment gérer ses ressources etc..
Pour bien jouer à Starcraft II, il faut donc être capable de prévoir à long terme puisque les décisions prises à un instant donné peuvent avoir des répercussions bien plus tard dans la partie, mais aussi de prendre des décisions très rapidement et d’agir précisément. Voir les joueurs professionnels jouer est assez impressionnant.
La recherche sur Starcraft
Bien qu’il y ait eu de nombreux succès en IA dans les jeux vidéo comme on a pu le voir (Atari, Quake III, Dota2,..), jusqu’ici les différents algorithmes n’arrivaient pas à gérer la complexité de Starcraft. Aucun agent basé sur une IA ne pouvait rivaliser avec des joueurs professionnels. Ce n’est pas pour autant qu’il n’y avait pas de recherche sur le jeu. Plusieurs compétitions ont eu lieu, parfois en restreignant le tâche à une sous-partie du jeu complet.
En 2018 à la AIIDE Starcraft AI competition c’est un agent avec des règles manuelles qui a remporté la compétition (devant un agent de Facebook appris par renforcement).
En 2016 et 2017 Blizzard et DeepMind ont travaillé ensemble pour fournir un environnement appelé PySc2 avec différents outils pour simplifier la recherche et l’apprentissage d’algorithmes sur Starcraft II.
Grâce à cet environnement, quelques approches récentes (comme celle-ci ou celle-ci) commencent à proposer des agents avec apprentissage capables de battre les meilleurs bots de Starcraft II (qui trichent en ayant plus de ressources ou en voyant tout le jeu par exemple) mais pas encore du niveau des humains.
AlphaStar
Toujours grâce à PySc2, DeepMind a pu mettre au point AlphaStar, une IA capable de battre des joueurs professionnels sur le jeu complet (avec quand même quelques restriction : le jeu est pour l’instant limité à une seule race et une seule carte).
AlphaStar à joué jusqu’ici contre deux joueurs professionnels est à pour l’instant (en janvier 2019) engrangé dix victoires pour une défaite. Les résultats sont donc bien supérieurs aux approches antérieures.
L’approche utilisée
Tous les détails d’AlphaStar ne sont pas pour l’instant accessibles puisque DeepMind n’a pas encore fourni le papier de recherche décrivant en détail la solution. Un article de blog nous donne cependant les informations principales sur le fonctionnement de l’agent.
La méthode semble être une amélioration de celle utilisée pour jouer au mode CTF sur quake III. En effet, on retrouve l’idée d’un apprentissage à deux niveaux : une population d’agent au sein de laquelle chaque agent fait lui-même son apprentissage par renforcement mais qui au niveau global est gérée par un algorithme génétique qui ne garde que les meilleurs agents pour améliorer au fur et à mesure le niveau de la population entière.
Les différentes phases de l’apprentissage
Une différence importante est que Starcraft II est bien plus complexe que le mode CTF, il semble donc quasiment impossible d’apprendre le fonctionnement basique du jeux seulement par renforcement. En effet, au début si les agents ne savent pas du tout jouer, ils auront beau faire des matchs les uns contre les autres, ils n’apprendront rien. C’est pourquoi l’apprentissage initial des agents est fait de façon supervisé grâce à ce que l’on appelle l’Imitation Learning. De façon assez similaire aux approches discutées pour Montezuma’s Revenge, les agents ont accès à de très nombreuses parties de joueurs humains et ils apprennent les bases du jeu à partir de ces parties. C’est seulement après cette phase que les agents commencent à jouer les uns contre les autres dans ce que DeepMind a nommé l’AlphaStar League. Dans cette league, la population d’agent fait un très grand nombre de matchs les uns contre les autres pour s’améliorer.
Pour les matches en cinq manches contre les joueurs professionnels, les cinq meilleurs agents de la League ont été sélectionnés. L’algorithme génétique qui gère la population force une certaine variété entre les agents, ce qui fait que les cinq agents choisis par DeepMind jouaient de façons différentes, ce qui a étonné et perturbé les joueurs professionnels.
Détails techniques de l’apprentissage
Pour le premier match contre un joueur professionnel, les agents se sont entraînés durant 7 jours complets. L’environnement PySc2 permet d’accélérer le jeu et de lancer de nombreuses instances en parallèle. Les 7 jours correspondent donc au final à 200 ans de jeu pour les agents. Pour le deuxième match, les agents ont eu 7 jours d’entraînement de plus. Pour chaque agent, 16 TPUs ont été utilisés durant l’apprentissage ce qui représente une puissance de calcul assez énorme. Cependant, une fois l’agent entraîné, le faire jouer ne nécessite qu’une machine classique dotée d’un GPU.
L’algorithme d’apprentissage
L’algorithme de renforcement utilisé est IMPALA (à ne pas confondre avec Apache Impala le moteur de requête SQL sur Hadoop présent dans Saagie.
Il s’agit d’une amélioration de A3C optimisée pour la parallélisation massive. De plus de nombreuses astuces d’apprentissage sont utilisées comme par exemple le self-imitation learning qui incite l’agent à répéter plus souvent les bonnes actions qu’il a pu faire dans le passé.
L’architecture des agents
Pour le mode CTF de Quake III, le cœur des agents étaient une architecture avec deux niveau de réseaux LSTMs. Ici, l’agent est basé sur un Transformer combiné avec un LSTM (avec en plus d’autres approches récentes comme les pointer networks).
Le Transformer est un modèle de réseau de neurones qui a fait beaucoup parler de lui dans le monde du traitement du langage (NLP). Il s’agit d’ailleurs de l’architecture sur laquelle beaucoup de solutions de l’état de l’art en NLP sont basées (comme la traduction automatique par exemple). Cette architecture est pensée pour gérer les données sous formes séquentielles. En général, on l’utilise sur des phrases mais ici les actions à effectuer dans le jeu sont aussi des données séquentielles. C’est un choix assez intéressant parce que le Transformer est connu pour avoir des difficultés à gérer les séquences très longues. Or, les séquences d’actions à effectuer dans un jeu comme Starcraft II sont bien plus longues que n’importe quelle séquence de mots dans une phrase. DeepMind a probablement trouvé une approche pour contrer ce phénomène, peut-être créer une hiérarchie de séquences ou limiter les séquences temporellement par exemple. On aura probablement les détails une fois l’article de recherche paru.
Les pointer networks sont une variante des architectures de type seq2seq (l’état de l’art en traduction avant l’arrivée du Transformer) dont l’objectif est de trier d’une certaine façon une séquence en entrée. Par exemple, ces réseaux peuvent servir à résoudre le problème du voyageur de commerce en indiquant dans quel ordre se déplacer. DeepMind ne détaille pas encore dans quel cadre ces réseaux sont utilisés, mais cela pourrait servir à gérer l’ordre dans lequel les actions doivent être exécutés. Par exemple dans une bataille, choisir quelles unités attaquer en priorité, lesquelles il faut protéger, etc..
Les prédictions de l’agent
L’architecture de l’agent prédit à chaque instant du jeu la séquence d’actions attendue jusqu’à la fin du jeu. Évidemment, cette séquence d’action est continuellement mise à jour et modifiée en fonction de ce que fait réellement l’adversaire dans la partie.
Le Transformer est ce que l’on appelle un modèle à attention, c’est-à-dire qu’il peut en quelque sorte se focaliser sur seulement certaines parties de l’information qu’il considère importantes. On peut voir sur la minicarte à droite que l’agent à chaque instant se focalise sur une seule zone et qu’en une minute, il change sa zone d’attention une trentaine de fois (ce qui est similaire au comportement des joueurs professionnels humains).
Dans l’interface proposée par Deepmind, on voit qu’à chaque instant, le modèle considère s’il doit construire de nouveaux bâtiments ou de nouvelles unités et surtout, il estime s’il est en train de gagner ou de perdre la partie. Cet indicateur de son état dans la partie lui permet d’agir en fonction. Par exemple, s’il sent qu’il est en train de perdre, il va peut-être se replier pour essayer de mieux se défendre dans sa base.
Un des points importants durant les parties contre les joueurs professionnels est que l’agent semblait toujours capable d’estimer quand il pouvait attaquer ou quand, au contraire il fallait plutôt ne pas prendre de risque. Le modèle semble donc capable de prédire à chaque instant s’il est en train de gagner la partie, mais à plus petite échelle, il semble aussi capable de prédire s’il peut remporter une escarmouche ou non.
Pertinence de l’architecture
DeepMind pense que leur architecture pourra aussi servir dans d’autres tâches où il est important de modéliser des séquences sur le long terme (comme la traduction automatique par exemple).
Une des avancées majeures à propos de AlphaStar (et de OpenAI Five) et qu’il semble que ces modèles continuent d’apprendre et de s’améliorer plus on ajoute de puissance de calcul. Ce n’était clairement pas le cas avec du Machine Learning classique où on atteignait souvent un palier de performance difficile à dépasser même en ajoutant plus de données. Cela signifie donc que les architectures choisies sont pertinentes et permettent de bien encoder les différentes problématiques de ces jeux.
Remarques sur les restrictions
À propos des restrictions du jeu, le fait de pouvoir jouer avec les trois races augmente encore beaucoup la complexité du jeu. Cependant, l’architecture proposée semble capable d’apprendre cela avec un temps et une puissance de calcul suffisant surtout en commençant l’apprentissage en imitant des parties humaines. L’autre grande restriction est liée aux cartes de jeu. Actuellement, AlphaStar est appris sur seulement une carte alors que le jeu en propose bien plus et renouvelle régulièrement son panel. Il existe certaines stratégies très agressives viable sur seulement une carte par exemple, l’agent devra donc être capable de s’adapter à ces stratégies spécifiques et généraliser un comportement. Encore une fois, vu les résultats déjà accomplis, cela semble possible avec l’architecture actuelle.
La dextérité de l’agent
Un point important à considérer lorsque l’on parle d’IA qui joue a Starcraft II est en quelque sorte la “dextérité” de l’agent. En effet, Starcraft étant un jeu où il faut contrôler beaucoup d’unités en même temps, un humain ne pourra jamais rivaliser avec un agent pouvant effectuer plusieurs milliers d’actions par seconde. DeepMind a donc volontairement ralenti ses agents pour que cela soit plus juste vis-à-vis des joueurs humains et donc que ce soit les stratégies proposées par l’agent qui fassent la différence et non son exécution parfaite.
On peut voir ci-dessus le nombre moyen d’actions par minute (APM) de l’agent et des joueurs professionnels. L’agent semble effectuer moins d’actions en moyenne. Il faut aussi prendre en considération le temps de réaction. En effet, un agent qui réagit instantanément aux différentes situations aura aussi un avantage considérable sur un humain même s’il ne fait pas beaucoup d’actions. On peut voir à droite le temps de réaction de l’agent qui a été réduit à celui du niveau d’un humain.
Ce graphique présente la théorie. En pratique, il y a quand mêmes beaucoup de questionnements au niveau de la dextérité réelle d’AlphaStar. Il est clair que l’IA a montré par moment une dextérité non-humaine durant les parties.
En effet, l’agent était initialement limité en terme d’APM. Avec cette limitation, l’agent n’arrivait visiblement pas à apprendre à micro-gérer ses unités pendant les affrontements. Pour faciliter l’apprentissage, certains pics d’APM ont été autorisés. Par exemple, pendant une séquence de cinq secondes AlphaStar à la possibilité de monter à 600 APM, pendant quinze secondes, il peut faire 400 APM etc.. Grâce à cela, AlphaStar a pu apprendre à microgérer durant les affrontements.
Ces valeurs de pics d’actions sont basées sur les APMs des joueurs professionnels. Le problème est que les joueurs humains n’ont pas une précision parfaite donc pour effectuer une seule action, en général ils effectuent plusieurs clics pour être sur de cliquer au moins une fois au bon endroit. On appelle cela le spam cliking. Ainsi les actions par minute d’un humain ne sont pas toutes des actions effectives. La courbe d’actions par minutes de TLO (en jaune) en est l’exemple extrême, probablement autour de seulement un dixième de ces actions ne sont pas du spam clicking. Les actions effectives par minutes (EPM) d’un humain représentent donc mieux façon de jouer d’AlphaStar qui ne fait pas ou très peu d’actions inutiles. Ainsi, il aurait probablement mieux valu utiliser les valeurs d’EPM des humains pour calculer les seuils des pics. Actuellement AlphaStar durant les affrontement présente une vitesse et une précision inhumaine.
Du coup, les victoires d’AlphaStar deviennent quelque peu questionnables. L’agent a-t-il vraiment gagné parce qu’il a mis en place de bonnes stratégies ou simplement parce qu’il contrôlait mieux ses unités que les joueurs professionnels ? Comme chacune des parties a été jouée par un agent différent, AlphaStar s’adapte t-il vraiment aux actions de l’adversaire ou a-t-il juste une stratégie bien rodée en tête dès le début qu’il applique suffisamment bien pour gagner la plupart des parties ?
L’objectif de DeepMind est de battre les joueurs professionnels à Starcraft II, mais surtout de le faire “bien”. C’est-à-dire que l’IA doit gagner sans que l’on ait l’impression qu’elle triche ou que le match ne soit pas équitable. Pour l’instant, il semble que leur solution n’ait pas encore atteint ce stade, mais ils sont clairement sur la bonne voie. Leur solution donne l’impression qu’un apprentissage plus long et plus poussé résoudra la plupart des problèmes et questionnements à propos de la version actuelle. Le futur nous dira si c’est bien le cas.
En conclusion
La recherche évolue très vite dans le domaine des jeux vidéo et la deuxième moitié de 2018 a été très importante avec le développement de plusieurs systèmes très impressionnants.
Un des points que la fin d’année nous à montré est que le fait de faire jouer un agent contre lui-même (self-play) donne de très bons résultats. C’est visiblement la meilleure façon (ou la plus simple) pour créer des gros volumes de données d’apprentissage. Cette approche, complétée par une bonne architecture de réseau de neurones pour un agent, est suffisante pour résoudre de nombreuses tâches si le domaine est relativement restreint (comme pour Quake III). Par contre, on observe que lorsque la complexité augmente (comme pour Dota 2 et Starcraft 2) cela ne devient plus suffisant et il faut trouver d’autres approches complémentaires.
Pour Dota2, l’approche a été de restreindre le jeu en simplifiant les règles et en codant manuellement les concepts les plus difficiles, puis au cours de l’apprentissage d’enlever au fur et à mesure les restrictions et les règles manuelles. L’exploration des différentes possibilités du jeu a été gérée principalement en ajoutant de l’aléatoire dans les parties durant l’apprentissage.
Pour Starcraft 2, l’approche a été d’utiliser ce que l’on appelle de l’imitation learning, c’est-à-dire copier le comportement des humains pour apprendre les règles fondamentales, puis apprendre à mieux jouer ensuite en self-play. L’exploration a été ici gérée par un algorithme génétique haut niveau et la League AlphaStar ce qui permet aux agents de trouver régulièrement de nouvelles stratégies.
Le “bug” d’AlphaStar
Durant la seule partie en live de l’affrontement entre AlphaStar et MaNa (un des joueurs professionnels), celui-ci a remporté le match contre l’IA en exploitant une faiblesse de celle-ci.
MaNa a réussi à faire tourner en rond AlphaStar pendant plusieurs minutes grâce à une seule unité (un Warp Prism), alors que la simple création de l’unité contre aurait résolu le problème (C’est visible dans cette vidéo de l’événement vers 2h39 minutes). Grâce à ce petit jeu MaNa a pu gagner la partie.
N’importe quel joueur humain (même de niveau très faible) aurait créé l’unité capable de détruire le Warp Prism ce qui aurait tout de suite stoppé la stratégie de MaNa. Seulement AlphaStar ne l’a pas fait. À ses réactions, on pouvait voir que l’agent considérait le Warp Prism comme étant important, il le surveillait, mais il n’a pas eu la réaction évidente que tout joueur humain aurait eu. Un des commentateurs a décrit cet échange comme : “C’est ce que je suis habitué à voir quand un humain joue contre une IA”. L’humain détecte une faille dans le comportement de l’IA et l’exploite à fond, l’IA étant incapable de réagir.
Les développeurs d’AlphaStar considèrent qu’un des grands challenges en IA est le nombre important de possibilités qu’un système a de mal tourner. En effet, une IA classique est facile à exploiter puisqu’elle présente de nombreuses failles visibles. Les systèmes complexes d’apprentissage pensée par OpenAI et DeepMind permettent de limiter beaucoup ces failles en trouvant les approches et les stratégies les plus fiables, mais le match en live contre MaNa nous a prouvé qu’il y en a toujours. Il semble que durant l’entraînement de l’agent ses adversaires n’ont pas utilisé cette stratégie à base du Warp Prism. En augmentant la durée de l’AlphaStar Training League et donc du temps d’apprentissage, il est probable que ce genre de faille disparaisse.
AlphaStar ne comprend pas du tout le jeu comme les humains et des concepts évidents pour nous lui sont inconnus. Ainsi, si durant l’apprentissage, l’agent n’a jamais eu à contrer un Warp Prism présentant une telle stratégie, il ne pourra pas comprendre comment contrer cette stratégie alors qu’un humain en aura probablement l’intuition même sans connaître le jeu en particulier. En effet, les humains sont capables de tirer parti de leurs expériences passées, de les agréger comme concepts et de les généraliser à de nouveaux problèmes, ce que ne font pas encore bien les IA.
Les concepts dans Montezuma’s Revenge
Quand une personne voit pour la première fois le premier niveau de Montezuma’s Revenge, même si elle ne va pas forcément savoir exactement quoi faire, certains concepts vont lui être familiers. Par exemple, la clé semble être un objet important. Il est probable qu’elle permette d’ouvrir une porte. Le crâne semble être un élément à éviter. Les échelles permettent de monter et de descendre. Le fait de tomber de haut risque d’entraîner la mort du personnage etc… Juste en observant cela, la personne va pouvoir planifier une suite d’actions pour sortir de la salle. Ces concepts généraux sont applicables à quasiment l’ensemble des jeux de plateforme de ce style.
C’est ce genre de raisonnement haut niveau basé sur une agrégation de concepts qui semblent être la base de l’intelligence humaine et qui semblent donc important à implémenter dans des systèmes d’apprentissage.
Le problème est que ces raisonnements et ces compétences sont très difficiles à mettre sous formes algorithmiques puisque l’on ne les comprend déjà pas bien chez l’humain. Quand on apprend de nouveaux concepts, on utilise en général en tant qu’humain des connaissances générales extérieures que l’on met en relation avec ces concepts. Ainsi, si l’on n’a pas accès à nos connaissances préalables (innées ou apprises), les jeux que l’on considère très simples deviennent d’un coup beaucoup plus complexes.
Ils ont pris un jeu de plateforme classique et ont enlevé successivement les concepts visuels que nous utilisons en tant qu’humains pour jouer à ce genre de jeu. Ainsi, cette page interactive permet de jouer au jeu dans une version où toutes nos connaissances antérieures sont supprimées. Le jeu s’avère relativement injouable. On peut considérer qu’un algorithme d’apprentissage par renforcement est mis dans une situation similaire au début d’un apprentissage. Cela peut expliquer en partie le manque d’efficacité de ces algorithmes par rapport aux humains en terme d’apprentissage (par exemple les 200 ans de Starcraft pour présenter le niveau d’un joueur professionnel). Comme les algorithmes n’ont pas les connaissances des bases que nous humains avons, la première étape de l’apprentissage consiste à créer ces connaissances depuis zéro grâce aux récompenses obtenues en réaction aux différentes actions, ce qui prend nécessairement du temps.
Un algorithme d’apprentissage par renforcement (A3C) a été appris sur cette version du jeu et il s’avère que l’algorithme met autant de temps que sur le jeu initial, cela ne lui pose pas de problème particulier, contrairement à nous humains.
L’apprentissage des concepts
L’objectif est donc de trouver comment faire apprendre à un agent ces connaissances de bases pour lui permettre de “comprendre” le jeu et comment faire en sorte que ces connaissances s’appliquent à l’ensemble des jeu de ce style et pas seulement à un seul.
Les deux façons d’aborder ce problème proposées par OpenAI et DeepMind à savoir la définition manuelle des concepts et l’apprentissage par imitation semblent permettre de résoudre en surface le problème, mais probablement pas suffisamment pour pouvoir bien généraliser les concepts à d’autres domaines. Il reste encore donc du travail en recherche pour atteindre ces objectifs
D’un autre côté, si on regarde les avancés liées au jeu de Go, la toute première version de l’agent AlphaGo présentait un apprentissage très similaire à celui d’AlphaStar. En effet, l’agent était initialisé avec de l’Imitation Learning puis la suite de l’apprentissage était faite en self-play. Cette version a été capable de battre les meilleurs joueurs du monde. Cependant, DeepMind en continuant à travailler sur le sujet a sorti une nouvelle version appelée AlphaGo Zero apprise intégralement en self-play. Cette version à battu AlpaGo 100 parties à zéro. Cela a montré que le fait d’imiter la façon de jouer des humains limitait en pratique l’algorithme. Les humains ne sont donc visiblement pas si bon que ça au jeu de Go et les biais induits en copiant leur façon de jouer n’étaient pas optimaux pour jouer.
Ainsi, essayer d’inculquer des notions et des concepts humains à des agents et se baser sur notre façon de réfléchir pour inventer des algorithmes d’apprentissage n’est peut-être pas la meilleure approche.
Il va être intéressant de voir si AlphaStar peut être appris de la même façon qu’Alphago Zero et présenter aussi des performances surhumaines en terme de stratégie sur Starcraft II.
Saagie, les jeux vidéo et l'IA
Comme on vient de le voir L’Intelligence Artificielle (IA) est devenue un élément essentiel dans l’industrie des jeux vidéo, permettant de créer des expériences plus immersives, réalistes et adaptatives.
Saagie, en tant que leader des plateformes DataOps fournit une plateforme puissante qui permet aux entreprises de collecter, de stocker et d’analyser des volumes massifs de données provenant de sources diverses. Cette approche permet aux entreprises d’obtenir des informations précieuses sur leurs clients, leurs opérations et leur marché, favorisant ainsi une prise de décision plus éclairée et une meilleure performance globale. Les développeurs de jeux peuvent ainsi mieux comprendre les comportements des joueurs, leurs préférences et améliorer constamment leur offre.
Saagie intègre également dans sa plateforme les processus de création d’IA. Que ce soit le module Data Service Orchestrator de Saagie, une solution cross plateforme pour orchestrer et ordonnancer des pipelines de données au travers de multiples services, ou le module Data Apps Manager pour déployer et gérer n’importe quelle application Docker, la plateforme DataOps de Saagie est un espace de travail collaboratif clé en main pour gérer vos projets IA de bout en bout.
Elle inclut des fonctionnalités avancées d’Observabilité pour monitorer les usages et la consommation des ressources. Elle permet également la gestion des environnements Data sur le Cloud pour une scalabilité accrue comme elle permet l’automatisation des déploiements avec le contrôle des versions et des capacités de CICD.
En conclusion, Saagie partage avec le monde du jeu vidéo une vision commune : révolutionner l’expérience utilisateur avec l’IA et une meilleure gestion des données. En continuant à exploiter la puissance de la plateforme DataOps Saagie, nous pouvons transformer la manière dont les entreprises gèrent leurs données et optimisent leurs performances, tout en offrant aux joueurs des expériences uniques.





