
Le nettoyage des données d’une entreprise (data cleaning) n’est peut-être pas la partie la plus appréciée de la data science, mais c’est certainement l’une des plus importantes : sans données propres, il est impossible d’entreprendre quoi que ce soit. En effet, si les données en entrée d’un modèle ou d’une analyse ne sont pas de bonne qualité, les résultats en sortie ne pourront pas l’être non plus…
Aussi, l’aspect crucial de la data quality mérite qu’on y consacre du temps. En général, l’étape de l’épuration des données occupe environ 60 à 80 % du temps consacré à un projet de data science.
Mais de quoi s’agit-il exactement et comment s’y prendre ?
Qu’est-ce que le data cleaning ?
Le data cleaning (ou data cleansing) consiste à préparer et à valider des données d’entreprise avant d’effectuer le projet principal que l’on souhaite réaliser avec elles. Ce processus ne consiste pas seulement à supprimer les données erronées, même si cela en fait souvent partie. La plus grande part du travail, en réalité, est de détecter les données erronées et (dans la mesure du possible) les corriger.
Les données « indésirables » sont des données incomplètes, inexactes, non pertinentes, corrompues ou mal formatées. Le processus de nettoyage des données comprend également le « dédoublonnage ». Il s’agit en fait de ne garder qu’un seul point de données si celui-ci est présent plusieurs fois.
L’objectif du nettoyage des données issues du big data est de conserver intacte la plus grande partie possible d’un ensemble de données. Cela permet d’améliorer la fiabilité des informations.
Comment s’opère le data cleaning ?
Les étapes et les techniques de data cleaning varient d’un ensemble de données à l’autre. Par conséquent, il est impossible qu’un seul guide couvre tout ce que vous pourriez rencontrer dans votre travail de nettoyage des données. Cependant, notre guide fournit un cadre général qui peut être utilisé à chaque fois. C’est parti !
Suppression des observations indésirables
La première étape du processus de nettoyage de données consiste à supprimer les observations indésirables de votre ensemble de données. Plus précisément, il s’agit de supprimer les observations en double ou non pertinentes.
Nettoyage des observations en double
Il est important de supprimer les observations en double, car vous ne voulez pas qu’elles faussent vos résultats ou vos modèles. Les doublons surviennent le plus souvent pendant la collecte des données, par exemple, lorsque les données proviennent de plusieurs sources.
Nettoyage des observations non pertinentes
Les observations non pertinentes sont celles qui ne correspondent pas aux problèmes spécifiques que vous essayez de résoudre. Par exemple, si vous construisez un modèle uniquement sur des maisons, vous ne voudrez pas y inclure des observations sur des appartements.
C’est également le moment idéal pour examiner vos graphiques d’analyse exploratoire. Vous pouvez examiner les graphiques de distribution des variables catégorielles pour vérifier s’il existe des classes qui ne devraient pas s’y trouver.
Correction des erreurs structurelles
La prochaine étape du data cleaning consiste à corriger les erreurs structurelles. Ce sont celles qui surviennent lors de la mesure, de l’import des données ou d’autres types de « mauvaise manipulation ».
Par exemple, vous pouvez vérifier les fautes de frappe ou les incohérences. Cela concerne surtout les variables de catégories. Là encore, vérifier les graphiques permet de passer aisément cette étape du processus d’épuration des données.
Enfin, vérifiez les classes mal étiquetées, ou les classes distinctes qui devraient en réalité être les mêmes. Par exemple, « IT » et « information_technology » doivent constituer une seule et même classe, idem pour « Mlle » et « Mademoiselle »…
Retirer les valeurs aberrantes indésirables
De quoi s’agit-il ?
Les valeurs aberrantes sont des valeurs numériques extrêmes, comparé au reste de la distribution. Si l’âge maximal dans notre population d’étude est 90 ans, alors que toutes les autres observations sont inférieures à 65 ans, on doit se pencher sur cette observation.
Comment les repérer ?
Les graphiques « Box Plot » ou fameuses « Boîtes à moustache » sont des outils précieux pour identifier les valeurs aberrantes.
Les valeurs extrêmes sont celles qui sont représentées à l’extérieur des moustaches. Ici, elles sont représentées par de petits ronds.
On ne peut pas dire que tous ces points extrêmes soient des valeurs aberrantes. Toutefois, ce sont des observations qui méritent qu’on les étudie pour savoir s’il faut les enlever ou pas.
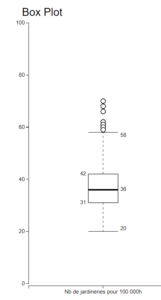
Ne retirez que les valeurs aberrantes indésirables
Ces valeurs extrêmes peuvent poser problème avec certains types de modèles. Par exemple, les modèles de régression linéaire sont moins robustes aux valeurs aberrantes que les modèles d’arbres de décisions.
Cependant, les valeurs aberrantes sont innocentes jusqu’à preuve du contraire. Vous ne devez jamais supprimer une valeur aberrante lors de votre processus de data cleaning simplement parce qu’il s’agit d’un « gros chiffre ». Ce grand nombre pourrait être très instructif pour votre modèle.
Nous ne saurions trop insister sur ce point : vous devez avoir une bonne raison de supprimer une valeur aberrante, par exemple, des mesures suspectes qui ne sont probablement pas des données réelles, ou encore des fautes de frappe…
En général, si vous avez une raison légitime de supprimer une valeur aberrante, alors les performances de votre modèle de machine learning s’en trouveront améliorées.
Gérer les valeurs manquantes en data cleaning
Les valeurs manquantes ne peuvent malheureusement pas simplement être ignorées. Elles doivent être traitées d’une manière ou d’une autre pour la raison très simple que la plupart des algorithmes de machine learning n’acceptent pas les valeurs manquantes.
Données catégorielles manquantes
L’une des techniques les plus utilisées pour traiter les données manquantes des variables catégorielles est de les étiqueter simplement comme « données manquantes » !
Cela revient à ajouter une nouvelle classe à la variable et permet de contourner l’exigence technique d’absence de valeurs manquantes.
Données numériques manquantes
Pour les données numériques manquantes, de nombreuses options sont possibles. On peut par exemple choisir de remplacer la valeur manquante par la moyenne de la distribution, par la médiane, ou encore par la valeur la plus fréquente.
Il est possible également d’utiliser des algorithmes pour estimer les valeurs manquantes (algorithme des plus proches voisins, arbres de décisions…).
Après avoir procédé correctement au nettoyage de vos données, vous disposerez d’un ensemble robuste de données de qualité qui vous évitera la majorité des pièges les plus courants. Vous éviterez également de développer des modèles biaisés et d’avoir de nombreux maux de tête par la suite… La data quality est capitale, alors surtout, bichonnez vos données d’entreprise !





