
Seuls 50% des projets d’Intelligence Artificielle ont aujourd’hui été déployés. C’est ce qu’il faut tirer des différentes études de Gartner, Capgemini ou encore BCG : le besoin d’industrialiser. Ce qui est mis en cause dans les différents rapports, c’est une durée moyenne de déploiement de 12 à 18 mois, qui mène à un changement d’outil voire à l’arrêt complet du projet par manque de résultats. Alors comment rapidement déployer ces projets ? Les mêmes analystes parlent de plus en plus d’une approche, celle du DataOps. Comparée au DevOps, son penchant dans le développement informatique, elle se distingue pourtant sur de nombreux aspects intrinsèquement liés aux problématiques uniques des initiatives en matière de donnée.
Un peu d’histoire sur les projets data
Avant d’apporter des solutions, il est d’abord intéressant de rappeler les bases. Il n’y a pas si longtemps que ça, traitement de données rimait seulement avec IT (très important d’ailleurs). La DSI s’occupait principalement de la structuration et de la rationalisation, les volumes étaient limités et leur traitement ne concernait que les données structurées. Côté stockage, on parlait uniquement de bases de données, voire de data warehouses (entrepôts de données) qu’on venait alimenter avec les données à notre disposition.
Tout cela change à partir de 2010 et l’arrivée des Data Lakes (lacs de données). Le but n’est plus simplement d’alimenter en données les outils, mais d’aller chercher la donnée où elle se trouve. Elle devient alors centrale, peut être traitée en plus grande quantité et dans des formats beaucoup plus diversifiés, voire déstructurés (images, sons, textes…).
Avec les Data Lakes arrivent le Data Lab et donc, de nouveaux profils comme le Data Scientist et le Data Engineer. Ces changements apportent plus de liberté dans les projets mais certaines contraintes subsistent comme celle de la mise en production, l’écosystème analytique n’apportant pas les mêmes standards de livraison IT que les frameworks hérités du développement logiciel. Transformer une idée en POC devient réalisable, mais la déployer dans un environnement de production est une autre paire de manches.
Les différents défis des projets data
On pourrait parler des contraintes d’infrastructures ou encore de sécurité, mais nous avons décidé de nous concentrer sur trois problématiques qui persistent et sont au coeur de nombreux projets, celles du choix des technologies, de la collaboration des équipes et des processus qui lient l’ensemble :
Le challenge technologique : il est bien beau de trouver des cas d’usage, encore faut-il les supporter. Et pour cela, on a alors besoin d’une stack sous-jacente sur laquelle se reposer. Le problème, c’est qu’il n’existe pas ou peu d’outils uniques pour mener à bien les projets de ce type. Les technologies sont au contraire très nombreuses et évoluent très vite. Il faut alors les assembler, mais aussi suivre leur évolution, les mettre à jour et les maintenir.
Le challenge de la collaboration : une fois la stack technologique mise en place, reste à faire concilier les différents profils qui l’utiliseront. Les Data Engineers préparent la donnée, les Data Scientists la valorisent. Les rôles sont donc définis et différents, et il peut être difficile de les faire travailler ensemble, d’autant qu’ils ne dépendent pas directement de la DSI.
Le challenge des processus : lorsqu’on a les outils et les gens qui seront amenés à les utiliser, il faut alors faire coïncider les deux. Les processus, trop souvent ignorés dans ce type de projet, sont pourtant fondamentaux à leur bon fonctionnement et à l’obtention de résultats rapides. Sans eux, les projets se font de manière artisanale et peuvent entraîner des frictions, des retards et par conséquent, des budgets importants.
C’est là qu’entre en jeu le DataOps. Mais puisque l’approche tient ses origines du DevOps, commençons par ce dernier.
Qu’est-ce que le DevOps ?
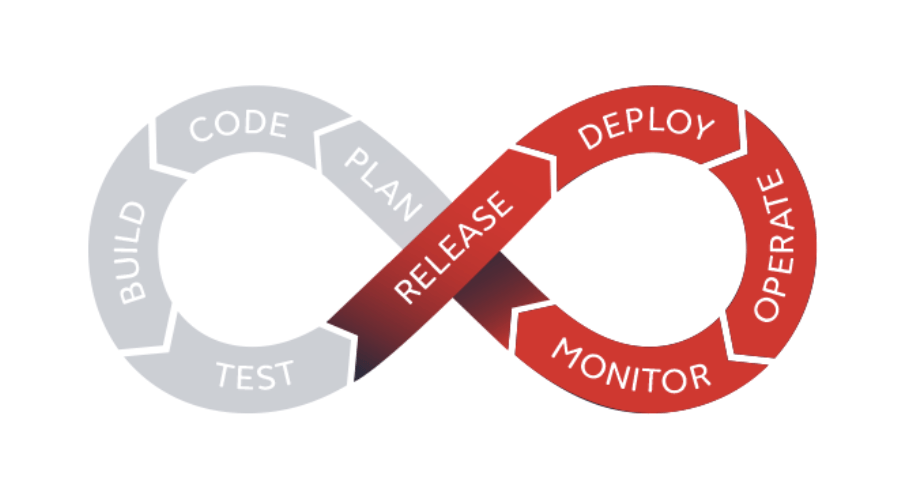
Le terme « DevOps » vient de la contraction des mots anglais « development » et « operations ». Le DevOps est une approche technique, organisationnelle et culturelle visant à améliorer la capacité d’une entreprise à livrer des applications et des fonctionnalités – le tout en gardant un rythme soutenu de delivery.
L’enjeu principal est d’accélérer le « time-to-market » avec des cycles de développement plus courts, une augmentation de la fréquence des déploiements et des livraisons continues.
Le DevOps repose sur deux concepts fondamentaux : le CI/CD qui comprend l’intégration continue (CI) et le déploiement continu (CD) :
- L’intégration continue consiste à construire, intégrer et tester de nouveaux codes de façon répétée et automatisée. Cette méthode permet d’identifier et de résoudre rapidement les potentiels problèmes.
- Le déploiement continu automatise le déploiement ou la livraison de logiciels. Une fois qu’une application a passé l’ensemble des tests de qualification, le DevOps permet son passage en production.
En résumé, l’approche DevOps permet l’alignement entre les équipes de développement / exploitation et l’automatisation de chacune des étapes de la création d’un logiciel, de son développement à son déploiement, jusqu’à son administration.
Qu’est-ce que le DataOps ?
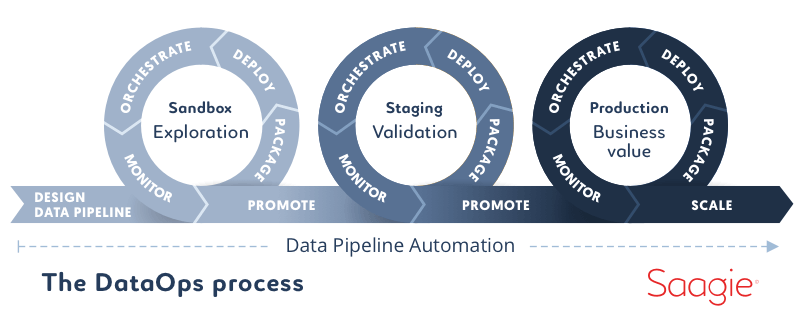
Gartner définit le DataOps comme « une pratique collaborative de gestion des données axée sur l’amélioration de la communication, l’intégration et l’automatisation des flux de données entre les métiers de données (Data Engineers, Data Architects, Data Stewards) et les consommateurs de données « (Data Scientists, Business Analysts, Métiers ou autre service).
La promesse du DataOps est d’améliorer et d’optimiser le cycle de vie des projets Data & Analytics en matière de rapidité et de qualité.
Le DataOps utilise la technologie pour automatiser la conception, le déploiement et la gestion de la livraison des données. C’est un orchestrateur technologique au service de votre projet. De même que le DevOps, le DataOps recentre vos projets sur la collaboration.
L’Agile Manifesto nous préconise « People over process over tools »; de nombreux profils sont en effet impliqués dans les projets Data & Analytics et tous doivent s’accorder pour collaborer autour du projet.
Les principes communs aux DevOps et DataOps
Le modèle de DataOps s’appuie sur le modèle de développement DevOps; Les deux approches intègrent toutes deux les principes « Lean » et « Agile ».
Nous retrouvons donc certaines pratiques communes et aspects techniques au DevOps et DataOps :
- Automatisation (Intégration continue / Déploiement continu)
- Tests unitaires
- Gestion d’environnements
- Gestion de versions
- Monitoring
Ces pratiques ont pour avantage de favoriser la communication et la collaboration de différentes équipes, ce qui permet un déploiement accéléré des projets et donc des coûts réduits.
Les différences principales entre DevOps et DataOps
L’approche DataOps reprend de grands principes du DevOps mais est plus difficile à appliquer puisqu’elle implique des profils qui vont au-delà de la DSI. Il s’agit ici de faciliter et d’accélérer le delivery tout en intégrant de nouveaux profils, en gouvernant différents environnements et en orchestrant un nombre important de technologies.
Plus concrètement, même si le DevOps offre automatisation, agilité et efficacité, son intérêt est limité lorsqu’il s’agit de créer des applications qui traitent et analysent les données de façon continue. L’un des aspects particuliers liés aux projets Data & Analytics consiste à construire et maintenir un pipeline de données (ou flux de données).
On entend par pipeline de données la conception de flux de données, de sa création jusqu’à sa consommation.
Les données entrent continuellement d’un côté du pipeline, progressent à travers une série d’étapes et sortent sous forme de rapports, de modèles et de tableaux de bord. Le pipeline de données est l’aspect « Ops » de l’analyse des données.
Un autre aspect différenciant du DataOps est lié à des spécificités de projets de Data Science :
- Reproductibilité des résultats
- Monitoring des performances du modèle : notez qu’un modèle de prédiction bon aujourd’hui, ne le sera pas forcément demain. Ajouter à cela l’intégration de nouvelles données…
- Mise à disposition et exposition de modèles dans une application pour utilisateurs finaux.
Le DataOps est un nouveau concept émergeant. Il n’y a donc pas encore de cadres ou de normes déterminés. On constate qu’en réalisant des projets plus rapidement en mode agile, le DataOps permet de mettre en production vos projets orientés données. Pour tirer tous les bénéfices des approches combinées DevOps et DataOps, il est important de disposer d’un relai technologique fondamental, un outil doté de capacités d’orchestration.
En intégrant en toute sécurité et transparence les meilleures technologies open source ou commerciales du paysage Big Data / IA, la plateforme DataOps de Saagie se distingue comme le étant premier orchestrateur transversal conçu pour mettre en œuvre une approche DataOps en tirant parti de l’expertise d’un vaste ensemble de partenaires technologiques.
La solution: la plateforme DataOps
On entend souvent “data is the new oil” : la donnée est le nouvel or noir mais l’enjeu n’est pas tellement la donnée elle-même mais ce qui est autour. Ce qu’il faut c’est un raffinerie, car ce que les gens attendent ce n’est pas du pétrole, mais bien de l’essence.
Adrien Blind - VP Product & Technology chez Saagie
Et si la raffinerie était donc un outil que l’on associe au DataOps ? Ce que nous appelons : la plateforme DataOps. Pour faire simple, voilà un aperçu de ce que l’outil permet de faire :
Contrôler l’ensemble du cycle de vie de vos projets. Il s’agit d’une véritable boîte à outils technologique qui permet de gérer l’ensemble du cycle de la donnée (préparation, traitement, valorisation et visualisation) tout en étant opérationnelle (infrastructure stable). De plus, elle offre des fonctionnalités permettant de tracer de monitorer chacune des étapes pour améliorer sécurité et performance.
Accélérer la mise en production des projets Data & Analytics. Toutes les technologies y sont assemblées pour offrir une adaptabilité complète en supportant les dernières versions (R, Python, Spark, Sqoop, Talend, Java, Scala, Jupyter, Docker). Les jobs sont reproductibles, la création de pipelines automatisée et l’outil est conçu pour la production.
Améliorer la collaboration et la communication au sein de votre entreprise grâce à une ergonomie simple et accessible. Tous les acteurs (Data Engineer, Data Scientists, Data Analysts, Data Stewards, IT/Ops) sont réunis au même endroit et peuvent y accéder facilement, et collaborer ensemble.
L’intérêt d’une telle plateforme est d’avoir des jobs reliés par des pipelines de traitements qui permettent de déployer de façon programmatique et automatisée, et tout cela en pouvant facilement passer d’un environnement à un autre. Cela permet donc à vos équipes de faciliter, d’accélérer et de fiabiliser la mise en production de vos projets.





