
Cet article fait partie d’une série d’articles sur les bonnes pratiques à destination du Data Engineer. Une version synthétique de cette série a été présentée lors d’un webinar que vous pourrez retrouver ici ! Vous trouverez les autres articles de cette série ici et là : Le monitoring : la clé pour superviser vos projets data et Pourquoi et comment mettre en place une politique de CI/CD ?
"Ça marchait la dernière fois que je l'ai lancé"
Lorsqu’une équipe data dans une entreprise commence à prendre de l’ampleur (multiplication des projets en phase de développement et 1ers passage en productions), il n’est pas rare qu’elle se retrouve face à des problèmes d’environnements de développement.
Deux difficultés principales peuvent se poser :
-
Les traitements qui tournaient sur l'environnement de développement ne fonctionnent plus lors de la reprise des projets.
En effet, dans les quelques semaines / mois entre la fin de la 1ère phase de développement et la reprise d'un projet, des mises à jour de packages ont été fait sur l'environnement de développement (pour les besoins d'autres projets), rendant le code inopérant.
De plus, on ne sait plus exactement quel package a été modifié ou quelle version était en place lorsque le script était fonctionnel. On rentre donc dans une phase de recherche pour retrouver ce qui a été changé, modifier les éléments pour les rendre compatibles avec les nouvelles versions, ... perdant ainsi de nombreux jours, voire semaines.
-
"Ça marche sur mon poste" !
Plus généralement, le passage d'un environnement à un autre (local, dev, recette, prod, CI) peut engendrer des complications si les environnements de développement ne sont pas identiques et constants dans le temps.
Si ce n'est pas le cas, il faudra alors rentrer de nouveau dans une phase de développement pour adapter son application aux spécificités des différents environnements, complexifiant la tâche des ingénieurs data, et augmentant leur charge de travail inutilement.
Ces deux difficultés ne sont pas rares dans les environnements data.
La 1ère vient d’une non-isolation des environnements de développement par projet. En effet, avoir un environnement de développement commun pour toute une équipe pour tous les projets va forcément entrainer des difficultés. Cela obligerait soit à ne jamais faire de mises à jour, privant ainsi les ingénieurs data des dernières innovations et optimisations, ce qui est difficilement acceptable dans un écosystème de technologies aussi mouvant que celui de la data, soit à devoir constamment reprendre tous les projets pour résoudre les problèmes de rétrocompatibilités qu’introduisent ces mises à jour, consommant par la même occasion une énergie non négligeable. Il devient ainsi essentiel, pour éviter ces écueils, de créer un environnement de développement par projet, isolé de ceux des autres projets.
Quant à la 2ᵉ difficulté, elle vient de la non-uniformisation des différents environnements de développement pour un même projet. Pour assurer un passage simplifié d’un environnement de développement à un autre (local, dev, recette, prod, CI), il faut ainsi s’assurer que ces environnements soient identiques. Il faut de plus qu’ils soient également constants dans le temps, même plusieurs années après, sans quoi il faudra investir du temps et de l’énergie pour redévelopper des éléments.
Plusieurs solutions existent pour répondre à ces problématiques, certaines spécifiques par technologie, et d’autres plus générales.
Des solutions spécifiques par technologies
Il existe de nombreuses solutions spécifiques par technologies (environnements conda ou virtuels pour Python, builds sbt pour Spark, …), et l’ambition de cet article n’est pas de les présenter de manière exhaustive, mais de mettre l’emphase sur certaines de leurs limites en déroulant un exemple particulier, celui des environnements conda sous Python.
Créer des environnements de développement Python avec les environnements conda
Conda est un gestionnaire de packages et d’environnements pour Python (entre autres). Il est open-source et cross-plateforme.
Il permet de créer et gérer différents environnements Python isolés les uns les autres sur une même machine, et de passer facilement de l’un à l’autre, permettant ainsi de faire coexister différentes versions de Python et différentes versions de packages associés.
Pour créer un nouvel environnement, il faut lancer les commandes suivantes

Quelques précisions :
-
La version de Python utilisée dans l'environnement est configurable.
- Il est important d'installer pip à l'intérieur de l'environnement, soit à la création de l'environnement comme précisé ici, soit via un conda install pip une fois l'environnement activé. Sans ça, utiliser des pip install à l'intérieur de l'environnement risque d'utiliser le pip de l'environnement principal et pas le pip de l'environnement virtuel (qui n'existe pas), et donc d'installer des packages dans l'environnement principal, ce qui n'est pas un comportement voulu
- Il est important d'installer pip à l'intérieur de l'environnement, soit à la création de l'environnement comme précisé ici, soit via un conda install pip une fois l'environnement activé. Sans ça, utiliser des pip install à l'intérieur de l'environnement risque d'utiliser le pip de l'environnement principal et pas le pip de l'environnement virtuel (qui n'existe pas), et donc d'installer des packages dans l'environnement principal, ce qui n'est pas un comportement voulu.
- Pour installer des packages, 2 possibilités : via conda install ou pip install. Il est recommandé dans un même environnement d'utiliser soit l'un, soit l'autre, mais pas les deux.
- pip est plus permissif que conda sur la gestion des dépendances des packages. L'ordre d'installation des packages n'a par exemple pas d'effet avec conda, alors qu'il en a avec pip. Conda va refuser certaines installations en cas de dépendances contradictoires avec certaines versions de paquets déjà installés, là où pip va silencieusement l'autoriser.
- Il est possible d'installer un Kernel Jupyter Notebook spécifique pointant sur un environnement conda, et donc d'avoir en plus d'un interpréteur Python spécifique, des notebooks utilisant cet interpréteur (et donc les versions de Python et de packages associés).
Les avantages de la technologie de Python
En se forçant à créer un environnement par projet avec conda, on isole complètement les environnements de développement projets les uns les autres, et on est assuré que le code fonctionnant à un instant t fonctionnera de la même façon plusieurs semaines / mois après : il suffira de réactiver l’environnement en question qui n’aura pas bougé puisque chaque projet aura le sien, et de lancer les traitements.
Conda propose également des fonctionnalités qui permettent dans une certaine mesure d’embarquer les environnements créés autre part (sur des solutions de CI par exemple).
Les limites de cette technologie
Même s’il propose certaines fonctionnalités pour, ce n’est en pratique pas si simple de réinstaller un même environnement conda sur un autre hosting (environnement de dev, recette ou prod par exemple). Il y a de nombreuses subtilités qu’il faut scripter : ordre d’installation des packages avec pip, repository conda à fixer, … De manière globale, pour ce type de solutions spécifiques, l’host cible n’est pas totalement maitrisé.
La construction de tels environnements n’est également pas toujours constante dans le temps. En effet, avec cette solution, il faut reconstruire l’environnement à chaque nouveau hosting, et certaines difficultés peuvent arriver du fait des dépendances des packages, dont les versions exactes ne sont pas toujours forcées, et qui peuvent à un moment donné devenir incompatibles avec l’environnement alors qu’elle l’était au moment de l’installation (exemple : abandon pour certain package de support pour d’anciennes versions de Python). Changer d’host peut dès lors devenir un casse-tête.
En entreprise, les équipes qui gèrent la construction des environnements de production (souvent les opérations) ne sont pas les mêmes que celles qui gèrent la construction des environnements locaux (souvent les ingénieurs data / data scientists eux-mêmes). N’ayant pas les mêmes priorités et pas les mêmes contraintes de travail, il peut arriver que cela entraine des différences dans les environnements, impliquant tout de même des différences entre les environnements.
Mais la limite la plus importante est que ces solutions ne sont pas cross-technologies. Il va donc falloir multiplier les systèmes de gestion d’environnement, avec tous les problèmes en termes de maintenance et de gestion de connaissances que cela peut impliquer.
Ce genre de solution spécifique par technologie a donc ses limites, et il peut dès lors être pertinent de se tourner vers une solution cross-technologie.
Les containeurs Docker, une solution cross-technologie
Pour assurer une isolation des environnements de développement par projet et la reproductibilité des traitements out-of-the-box, Saagie fait tourner l’ensemble de ses jobs dans des containeurs Docker spécifiques.
Docker vous avez dit ?
Nous n’avons pas la prétention ici d’expliquer en détail ce qu’est Docker, ni même d’en faire une introduction. Nous renvoyons pour cela le lecteur vers la multitude d’articles sur le sujet qui traitent ça de façon claire et pédagogue.
Néanmoins, pour faire simple et en paraphrasant la définition de wikipedia, Docker est un logiciel de conteneurisation « qui peut empaqueter une application et ses dépendances dans un conteneur isolé qui pourra être exécuté sur n’importe quel serveur ».
Pour simplifier encore (au risque de nombreux raccourcis), il s’agit ici d’installer un environnement de développement (Python ou autre) dans un conteneur Docker qui va ensuite pouvoir « s’exécuter » tel quel sur n’importe quel hosting via Docker en téléchargeant ledit environnement via le dépot centralisé DockerHub.
Fonctionnement sur Saagie : des environnements isolés et des jobs reproductibles out-of-the-box
Dès lors, Saagie construit et maintient un ensemble de conteneurs Dockers (on parle d’images Docker) présentant différents environnements de développements : différentes versions d’une même technologie accompagnée de versions spécifiques de packages.
Pour prendre l’exemple de Python, Saagie met à disposition out-of-the-box des images Docker pour différentes versions de Python (2.7, 3.5, 3.6, 3.7, 3.8) avec différentes versions d’un certain nombre de packages préinstallés. L’utilisateur peut dès lors pour chaque projet choisir l’environnement le plus opportun, le customiser si besoin via des pip install, ou même en créer un nouveau via le sdk de Saagie pour mettre à disposition un nouvel environnement à tous les utilisateurs.
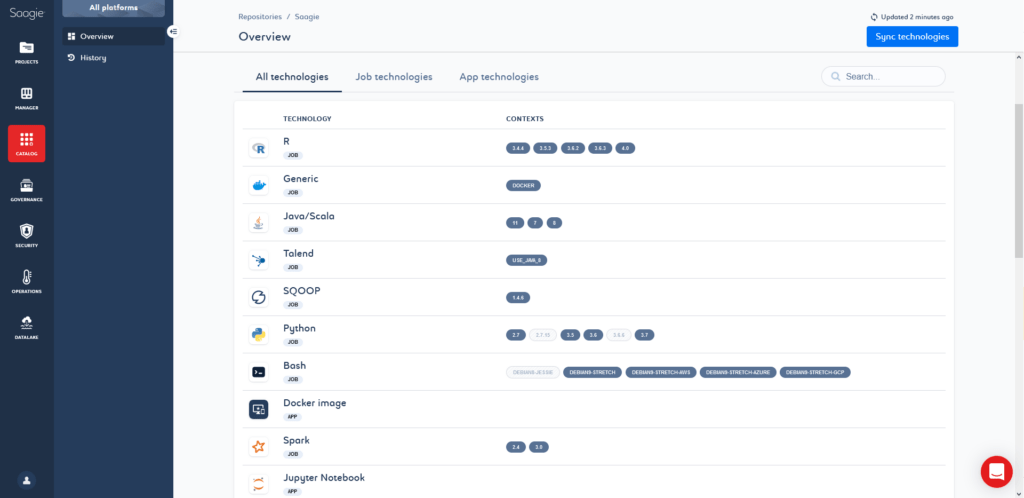
Grâce à ce système, chaque projet (et même chaque job) a son propre environnement de développement qui est isolé des autres projets, et ce pour toute les technologies disponibles sur la plateforme.
De plus, les images étant fixées et l’environnement installé à un instant t, en cas d’ajout de nouveau hosting, pas besoin de réinstaller l’environnement, il suffit juste d’utiliser Docker pour instancier un conteneur à partir de l’image en question (« executer » l’environnement en question). L’environnement reste donc constant au cours du temps. Toujours pour les mêmes raisons, il est juste « exécuté » par Docker sur différents hosting et est donc complètement identique sur l’ensemble des environnements (local, dev, recette, prod, CI), à condition d’utiliser les mêmes images Docker (les mêmes environnements).
Enfin, les images Dockers Saagie étant publiques sur DockerHub, elles sont récupérables et utilisables par tous. Il est ainsi possible et même relativement simple d’utiliser ces images Docker pour les développements locaux ainsi que dans les environnements de CI :
- En local, il suffit d'installer Docker Desktop, de puller et d'exécuter l'image Saagie de votre choix et de brancher l’interpréteur sur votre IDE favori. Vous pourrez ainsi développer en local (mais aussi lancer des tests localement) avec un interpréteur Python identique à celui de développement et de production, et donc ne pas perdre de temps avec des problèmes de différence d'environnement.
- Dans les environnements de CI, exécuter des commandes dans un conteneur docker est aujourd'hui une fonctionnalité commune de la majorité des outils du marché. Vous pourrez donc assez simplement utiliser les images Saagie pour lancer votre batterie de tests (unitaires, intégration, ...), et ce en s'assurant qu'ils tournent dans les mêmes environnements que votre dev et votre prod.
Résumons le tout !
Pour vos projets data, il vous faut, sous peine de pertes de temps importantes :
- Construire un environnement de développement (isolé des autres) pour chacun de vos projets.
- S'assurer d'une stricte uniformité des environnements de développements sur vos postes locaux, environnements de dev, recette, prod et CI, et ce afin de s'assurer de la bonne reproductibilité de vos traitements.
Pour cela, des solutions spécifiques par technologies existent, mais préférez une solution cross-technologie comme docker pour ne pas avoir à multiplier les systèmes et compétences à maintenir.
Une solution comme Saagie peut vous permettre d’accélérer grandement sur ces sujets et de réduire vos pertes de temps en apportant ces fonctionnalités out-of-the-box, ainsi qu’en vous mettant à disposition des environnements pré-configurés et maintenus pour de nombreuses technologies via ses repository de technologies officiels et non officiels. En cas de besoins spécifiques, son SDK vous permettra de construire vos propres environnements et de les mettre à disposition de tous vos collègues simplement.





