
Big Data, Data Science, Machine Learning, Deep Learning, algorithmes prédictifs… Cela fait maintenant plusieurs années que ces termes sont entrés dans le monde de l’entreprise. Pour pouvoir exploiter ces nouvelles technologies, de nombreuses entreprises ont mis en place un Data Lab (vous pouvez vous référer à notre article sur le sujet pour plus d’informations).
Néanmoins, 80% des projets Big data ou IA n’atteignent pas la mise en production. Si nous avons abordé les principales raisons de ces échecs et comment y remédier, le Machine Learning Engineering, nouveau métier apparu avec la montée de la data, lui, devrait plutôt figurer parmi les solutions potentielles. Pour comprendre de quoi il s’agit il faut d’abord s’intéresser à l’article d’O’Reilly qui décrit les rôles des Data Scientists et Data Engineers et en quoi le Machine Learning Engineer pourrait être le lien qui manquait à la réussite des projets.
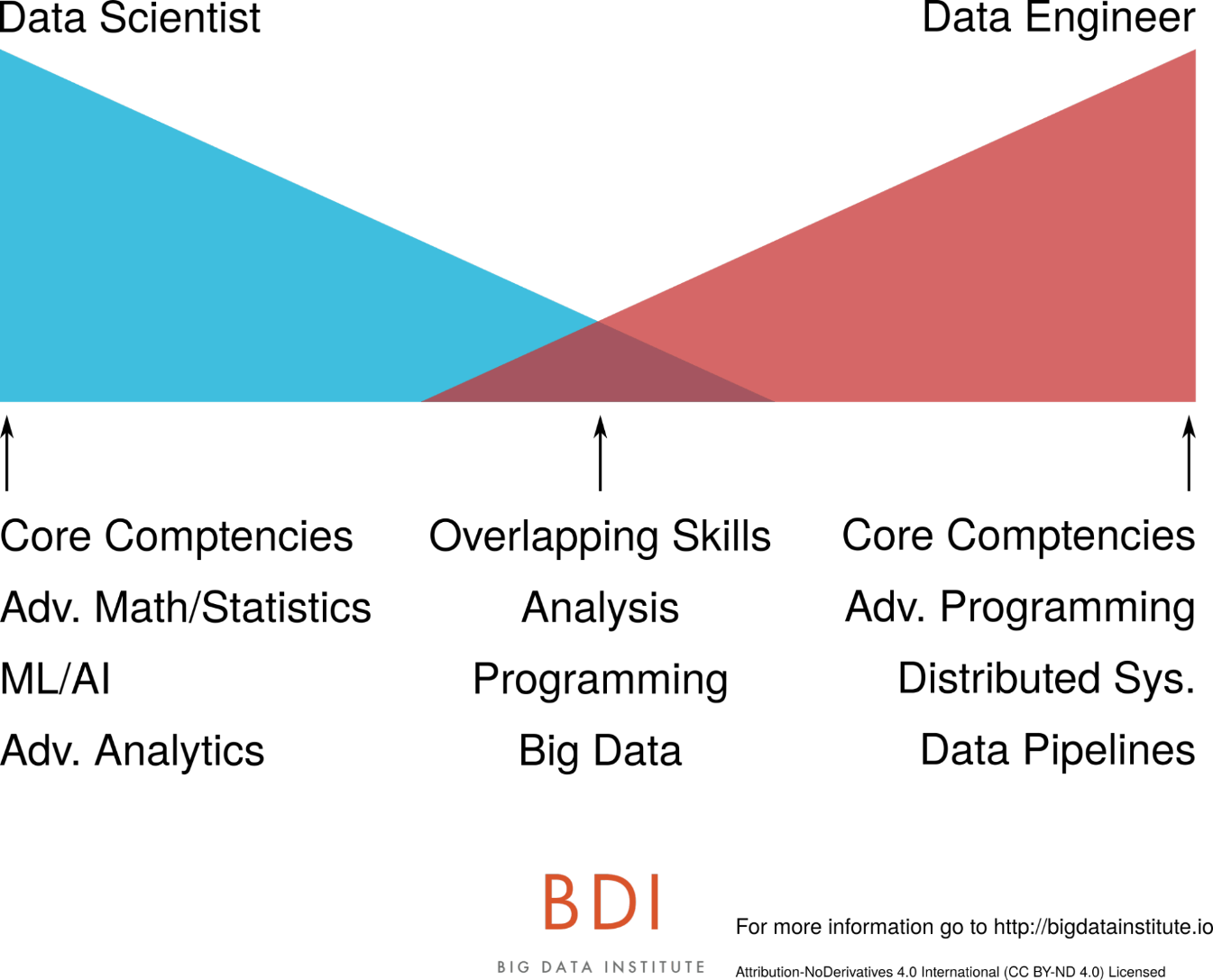
Ce qui différencie le Data Scientist et le Data Engineer
Pourquoi les différencier ? Car de nombreuses entreprises demandent à des Data Engineers de faire de la Data Science et à des Data Scientists de gérer des infrastructures, et que cela peut conduire à l’échec d’un projet, en plus de créer des tensions et frustrations au sein des équipes. Il est donc primordial d’identifier les rôles de chacun, leurs capacités et ainsi adapter leurs missions.
Le Data Scientist : Il a généralement une formation en mathématiques et statistiques (parfois même en physique). Au-delà de cela, il fait de l’Analytics et pour aller encore plus loin, il crée des algorithmes d’intelligence artificielle, le plus souvent de Machine Learning.
Il fait parler les données. Il se charge de les recouper, puis d’en fournir une interprétation claire. En cela, le Data Scientist porte bien son nom : c’est un métier proche de celui du chercheur, mais pourtant bien ancré dans l’entreprise.
Tout comme son homologue ingénieur, il doit être en contact avec les métiers, côté business. Dans le cadre de son travail il doit leur apporter des analyses et doit donc être familier avec l’entreprise, ce qu’elle fait et les enjeux économiques des résultats qu’il délivre. Ces résultats doivent d’ailleurs être compréhensibles et adaptés aux métiers pour les aider dans leur prise de décision.
Une particularité que l’on retrouve chez bon nombre de Data Scientists est qu’ils ont appris à programmer par nécessité, afin de faire des analyses poussées ou pour surmonter un problème. Leur niveau n’est pas celui d’un programmeur ou d’un Data Engineer, ce qui est finalement logique puisqu’ils n’ont pas le même besoin.
Le Data Engineer : Il a une formation en programmation, le plus souvent en Java, Scala ou Python. Il est généralement spécialisé en systèmes distribués et Big Data.
Il est responsable de la création et de la maintenance de l’infrastructure analytique qui permet presque à toutes les autres fonctions de tourner dans le monde des données. Il s’occupe du développement, de la construction, de la maintenance et du test des architectures, telles que les bases de données et les systèmes de traitement Big Data mais donc aussi de la création de processus de modélisation des jeux de données sur l’exploration, l’acquisition et la vérification de ces derniers.
Plus concrètement, grâce à sa formation, il crée ce qu’on appelle des data pipelines. Et si cela peut sembler simple en le disant, il s’agit en fait, à l’échelle du Big Data, de faire fonctionner des dizaines de technologies ensemble. C’est d’ailleurs le Data Engineer qui choisit les technologies les plus adaptées, il se doit donc d’en avoir une connaissance accrue.
Qu'est-ce qui les rapproche ?
L’analyse. Les deux profils peuvent faire de l’analyse de données, même si le niveau de compétences du Data Scientist n’est pas le même que celui du Data Engineer. Le premier pourra réaliser des analyses très poussées quand le second maîtrise les analyses basiques jusqu’à intermédiaires.
Les deux se rejoignent aussi sur la programmation. Mais ici encore, à deux niveaux bien différents, et c’est le Data Engineer qui prend l’avantage sur ce terrain. Quand construire un data pipeline est la base du travail du Data Engineer, c’est en revanche bien au-dessus des compétences du Data Scientist. C’est aussi en cela que les deux profils se complètent, le travail de l’un supportant celui de l’autre.
Pour finir, le point commun à côté duquel on ne peut passer est le Big Data bien sûr. Les Data Engineers mettent à profit leur compétences de programmation pour créer des pipelines Big Data. Ces pipelines servent ensuite à supporter le travail du Data Scientist qui utilise, quant à lui, ses compétences mathématiques et statistiques pour créer des produits data, concevoir des modèles et dégager des tendances. Il est donc indispensable de connaître les points forts et les limites des deux profils afin de répondre aux attentes de tous.
Pourquoi a t-on besoin du Machine Learning Engineer ?
Comme le rappelle l’article d’O’Reilly, les Data Scientists ont, pour la majorité d’entre eux, suivi un cursus universitaire. Ce qui n’est évidemment pas un problème en soi peut finalement en devenir car ces profils sont souvent très attirés par la recherche et le théorique. Or, les entreprises, elles, cherchent du concret, du déploiement et de la création de la valeur. Et malgré leurs efforts, 80% d’entre elles n’y parviennent pas.
Du côté des Data Engineers, la difficulté se trouve dans le fait que cette tâche, la mise en production d’algorithmes, n’est pas tout à fait dans le descriptif de leur job. Leur rôle est davantage de gérer les pipelines qui supportent les algorithmes de Machine Learning mais pas directement d’optimiser ces algorithmes pour leur déploiement.
La mise en production d’algorithmes de Machine Learning nécessite quelque chose en plus qu’un raisonnement purement académique. C’est pourquoi un nouveau type d’ingénieur est en train de voir le jour, le Machine Learning Engineer. Surtout présent aux Etats-Unis, ce profil tend désormais à se répandre, et constitue un enjeu qui n’est pas seulement américain.
Quel est le rôle du Machine Learning Engineer ?
Dans la majorité des cas, ces ingénieurs d’un nouveau genre ont une formation similaire à celle des Data Engineers. Cependant, poussés par une appétence pour les mathématiques et le Machine Learning, ils ont généralement eu un cursus croisé ou suivi des formations supplémentaires afin de pouvoir gérer aussi bien l’infrastructure que la Data Science.
Le Machine Learning Engineer apparaît donc comme le lien entre le Data Scientist et le Data Engineer. Il maîtrise les algorithmes de Data Science, mais possède aussi des compétences similaires à celle du Data Engineer pour gérer l’infrastructure qui permettra leur optimisation, puis leur mise en production.
Son profil se rapproche donc davantage d’un ingénieur que celui du Data Scientist par ses compétences logicielles. Il comprend et met en pratique les méthodes de développement ainsi que l’approche agile. Puisqu’il assure la gestion de la mise en production, ils se doit aussi de maîtriser les outils permettant de maintenir un certain niveau de sécurité à l’ensemble de l’environnement.
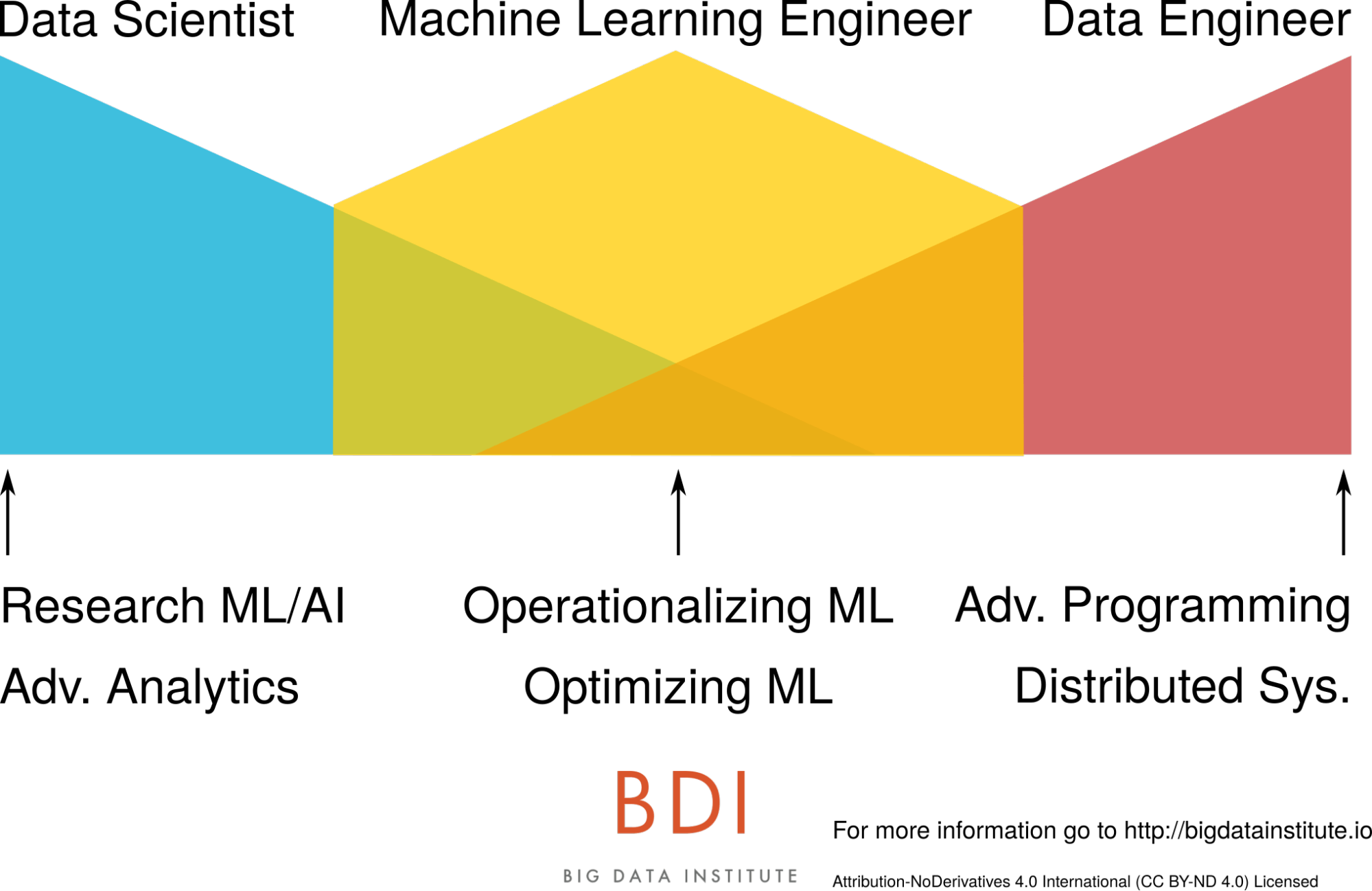
Il n’existe pas encore de définition du Machine Learning Engineering puisqu’il s’agit d’une discipline à la croisée de l’ingénierie et de la Data Science encore récente et peu présente. Pour faire simple, cela comprend l’ensemble des processus qui permettent la mise en production de Machine Learning grâce à l’optimisation d’algorithmes.
Cette mission concerne donc ce qu’on pourrait appeler le dernier kilomètre de la donnée. Il pourra s’agir de réécrire en Java ou Scala le code d’un Data Scientist qui était à l’origine en R ou Python, de le mettre à l’échelle (Python vers PySpark, ou Python vers Scala Spark), ou encore d’optimiser un algorithme d’intelligence artificielle pour assurer son fonctionnement. Elle recouvre donc toute la phase d’industrialisation qui implique, en plus de tout le reste, des tests et du déploiement continu.
Un modèle de Machine Learning nécessite plus d’attention qu’un programme informatique classique. Il peut tout à fait fonctionner et, d’un jour à l’autre, donner des résultats incohérents. Cela peut venir d’un changement dans les données, d’ajout de nouvelles données ou encore d’une attaque. Dans tous les cas, la tâche du Machine Learning Engineer sera de gérer toutes ces failles éventuelles grâce à ses connaissances des deux milieux (infrastructure et Data Science).
La Plateforme DataOps pour faire du Machine Learning Engineering
L’Orchestrateur de Saagie permet de mettre facilement en production les algorithmes de Machine Learning. Elle offre les outils pour faire du Machine Learning Engineering sans avoir besoin d’un Machine Learning Engineer.
Tout d’abord, il s’agit un environnement collaboratif qui va faciliter les échanges et le partage entre les Data Scientists et les Data Engineers en les faisant travailler sur des projets communs.
D’un côté, les Data Scientists vont pouvoir accéder à une plus grande quantité de données (permettant de tester la robustesse de leurs algorithmes) et intégrer les différents algorithmes qu’ils auront créés sur leurs notebooks (Jupyter, R Sutdio) grâce aux connecteurs de la Data Fabric.
De l’autre, les Data Engineers, eux, vont pouvoir créer de multiples data pipelines et y intégrer simplement les algorithmes des Data Scientists. Pour cela, ils les dockerisent tout en orchestrant les multiples technologies open-source (talend, scala, spark, Python, R, etc) nécessaires à la création des data pipelines. L’optimisation d’algorithmes ou la réécriture de code en raison de soucis de compatibilité de technologies n’est ici plus nécessaire.
Enfin, comme l’Orchestrateur DataOps a été conçue de manière à amener les pratiques DevOps dans le monde du Big Data, toutes les fonctionnalités permettant de versionner, déployer, opérer, monitorer, “rollbacker” et itérer sur les différents travaux réalisés par les Data Engineers et Data Scientists y sont présentes.
L’Orchestrateur se positionne ainsi comme une solution idéale pour industrialiser le Machine Learning, et orchestrer de bout en bout les projets Big Data/IA.





