
L’idée de cet article n’est pas de vous rappeler l’importance de bien monitorer ses systèmes et applications IT, il y a pléthores d’articles en ligne qui le font mieux que nous. Nous préférerons ici évoquer les spécificités des projets strictement orientés autour de la donnée (analytics, machine learning, streaming) et vous donner des exemples concrets que vous pourrez mettre en place sur votre prochain projet afin d’améliorer votre visibilité sur vos pipelines, voire vous alerter en cas de soucis, instabilités, dérives…
Nous parlerons tout au long de cet article de monitoring dans le sens de métrologie, à savoir la collecte de différentes métriques pour les évaluer sous forme de graphiques, courbes, et tableaux.
Que mesure t-on dans les projets data ?
Les projets Data n’échappent en effet pas à la règle en ce qui concerne le monitoring, bien au contraire. En plus des composants IT (hardware, software) à surveiller, les données en tant que telles devront également faire l’objet d’une surveillance rapprochée. Sur un projet d’analytics complet, qui mêle ingestion de données, jobs longs en mode batch sur des gros volumes, potentiellement du streaming de données, de la dataviz… on souhaitera également mesurer :
La consommation CPU / mémoire / réseau
Cette composante n’est pas spécifique à un projet data, ce qui l’est c’est la granularité de l’information que l’on veut récupérer. Dans le cas de traitements distribués (un job Spark par exemple), on va vouloir tracer de manière précise la consommation au niveau exécuteur, voire au niveau d’une tâche, pour s’assurer que nos configurations de ressources sont correctes, que l’on ne surutilise pas les ressources du cluster au détriment d’autres applications qui tourneraient en parallèle par exemple.
La performance des traitements
Dans notre contexte, on peut rapidement se retrouver avec des traitements batch qui durent plusieurs heures. Une dérive du temps de traitement de quelques % peut donc se traduire en heures de retard pour la fin de notre job, retardant d’autant plus la mise à disposition aux utilisateurs. D’où l’importance de pouvoir détecter de manière précise de potentielles dérives afin de pouvoir réagir rapidement.
La qualité, complétude, conformité, tests d'intégrité sur la donnée
On va s’intéresser ici de manière plus détaillée aux données qui transitent dans nos pipelines afin de mettre en place des contrôles comme :
- le contrôle de l’encodage des données en entrée
- le nombre de valeurs incorrectes dans un dataset (mal typées par exemple)
- le comptage du nombre de lignes en entrée/en sortie de chaque étape d’un pipeline
- le taux de complétude d’une colonne
- …
qui pourront servir à la fois :
- de suivi de qualité des données. Lors de mise en place d’actions d’amélioration de cette qualité en entrée du système, on pourrait ainsi mesurer de manière tangible ces résultats : moins de contrôles en échec ? de la donnée plus cohérente ?
- de garde fou : en fonction du nombre d’erreurs dans les contrôles, on peut décider d’un seuil à partir duquel le pipeline sera bloqué afin d’éviter de polluer les briques en aval avec de la donnée de mauvaise qualité. Les métriques issues de ces contrôles seront donc directement utilisées dans du code de production pour décider du sort d’un traitement.
Les métriques de data science
Il nous semble indispensable de pouvoir tracer les performances des modèles de data science utilisés dans vos projets dès lors que vous commencez à en utiliser/entraîner plusieurs. On cherchera donc à logger, que ce soit lors des phases d’entraînement ou dans les phases de run, des statistiques descriptives, de corrélation, de précision, de rappel…
Les logs d'accès
Une fois nos données ingérées et valorisées, on voudra comprendre leur utilisation. Mettre en place des logs d’accès à la donnée, en plus d’être utilisable à des fins d’audit, vous permettra de bien comprendre comment sont utilisés vos datasets, par qui, pour quel usage ou à quelle fréquence. Il serait dommage d’investir beaucoup de temps à nettoyer/valoriser de la donnée brute pour vous apercevoir que le dataset final n’est en réalité jamais accédé par aucun des data scientists de votre organisation.
Le monitoring dans la pratique
Dans les faits, nous vous conseillons d’essayer de mettre en place ces briques de monitoring dès le départ du projet. Cela vous permettra de bénéficier de ces différentes métriques dès les premières itérations. Il nous est même arrivé d’implémenter toute cette mécanique avant même l’écriture de la moindre ligne de code et l’intégration des premiers datasets. Ainsi, une fois les données prêtes à être ingérées, tous nos jobs de collecte, processing, exposition de la donnée étaient déjà connectés à notre stack de monitoring pour y logger, notamment, les temps de traitement de chaque étape.
C’est sur ce projet de détection de fraude que nous allons vous faire un retour d’expérience et vous proposer une stratégie de mise en place de votre monitoring via des exemples concrets.
Dans notre cas (projet réalisé sur une plateforme Saagie), nous disposions déjà d’un monitoring général de nos plateformes mis à disposition par nos équipe SRE (métriques système comme consommation CPU/MEM, l’état du réseau, l’espace disque, etc), nous nous sommes donc concentrés sur le spécifique à notre projet.
La mise en place de la stack de monitoring
La première étape va être de décider des outils pour le stockage et la visualisation des métriques, en fonction de notre besoin et des contraintes de notre projet. Nous avons en général l’habitude de pousser nos métriques métiers et nos logs techniques dans Elastic Search pour les visualiser ensuite dans Kibana, mais notre projet impliquait d’utiliser uniquement Postgresql comme base de données. Nous sommes donc partis sur un duo Postgresql – Grafana.
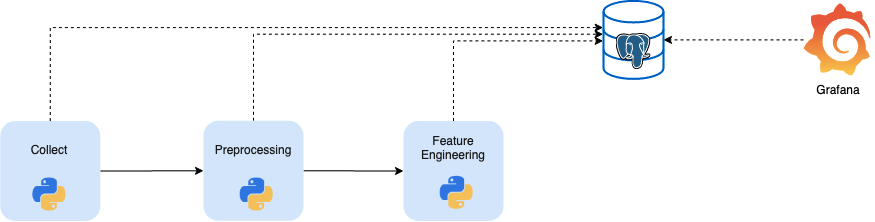
Côté PostgreSQL la première étape est de créer une table générique pour y stocker nos différentes métriques selon un modèle simple dans un premier temps, que l’on pourra faire évoluer par la suite (pas la peine de monter une usine à gaz dès le départ, rappelez-vous de l’idée initiale qui est d’itérer sur cette brique logicielle).
Modèle de données :
metric_timestamp : timestamp de collecte de la métrique, ex : 2020-11-05 12:34:56
metric_name : nom de la métrique, ex : elasped_time
metric_namespace : namespace de la métrique pour avoir différents niveaux de logging (nom d’un job/plateforme/pipeline) exemple : processing-job
metric_value : valeur, ex : 1200
metric_unit : unité, ex : sec
Nous avons créé une fonction de logging toute simple, dans un module utils qui sera accessible depuis tous nos autres modules Python. Nous avons choisi de rendre cette fonction la moins bloquante possible, car le monitoring ne doit en aucun cas bloquer un pipeline de production et il était donc impensable pour nous de stopper du code métier en cas d’échec de connexion à la base PostgreSQL. La moindre exception se contentera donc d’afficher un message d’avertissement sans stopper l’exécution du code appelant.
def log_to_pg(metric_namespace, metric_name, metric_value, metric_unit):
"""
Log applicative monitoring to PostgresSQL. This function is not blocking and exceptions
in PG connections should not interrupt the function
:param metric_namespace: Namepsace to differentiate metrics for jobs, pipelines, business lines...
:param metric_name: Name of the metric (e.g job_duration)
:param metric_value: Value of the metric (e.g. 23.2)
:param metric_unit: Unit for the value (e.g. seconds)
:return:
"""
postgresql_table = "monitoring"
now = datetime.now()
connection, cursor = None
try:
connection = connect_to_pg()
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(
'INSERT INTO %s (metric_timestamp, metric_namespace, metric_name, metric_value, metric_unit) VALUES (%s, %s, %s,%s,%s)',
(AsIs(postgresql_table), now, metric_namespace, metric_name, metric_value, metric_unit)
)
except:
logging.error("Unable to connect to Postgres")
finally:
if connection:
cursor.close()
connection.close()
Rien d’extraordinaire en tant que tel comme vous le voyez, c’est surtout l’usage que l’on va faire de cette fonction qui va être important.
Les premières métriques
Une fois la stack prête à l’emploi, vous allez pouvoir commencer à l’utiliser dans vos jobs. On pourra par exemple suivre l’évolution de la durée de nos traitements au fil du temps.
Pour cela 2 étapes :
1 – On rajoute l’appel à la fonction de logging dans la fonction main du pipeline :
def main(argv):
task = ''
usage = '__main__.py -j '
...
start_time = time.time()
if task == "collect":
collect.run()
elif task == "preprocessing":
preprocessing.run()
...
utils.log_to_pg(metric_namespace=task, metric_name="elapsed_time", metric_unit="seconds",
metric_value=time.time() - start_time)
2 – On crée la dataviz correspondante dans Grafana :
Pour cela, une fois la connexion avec PostgreSQL préalablement configurée, configurez votre panel dans Grafana en lui spécifiant :
- le champ à utiliser pour le filtre temporel (ici
metric_timestamp) - le champ à utiliser en tant qu’ordonnnée (ici
metric_valuequi correspondra à la durée des jobs) - l’unité de la métrique (ici des
seconds)
Ensuite libre à vous de customiser ce graphe comme bon vous semble.
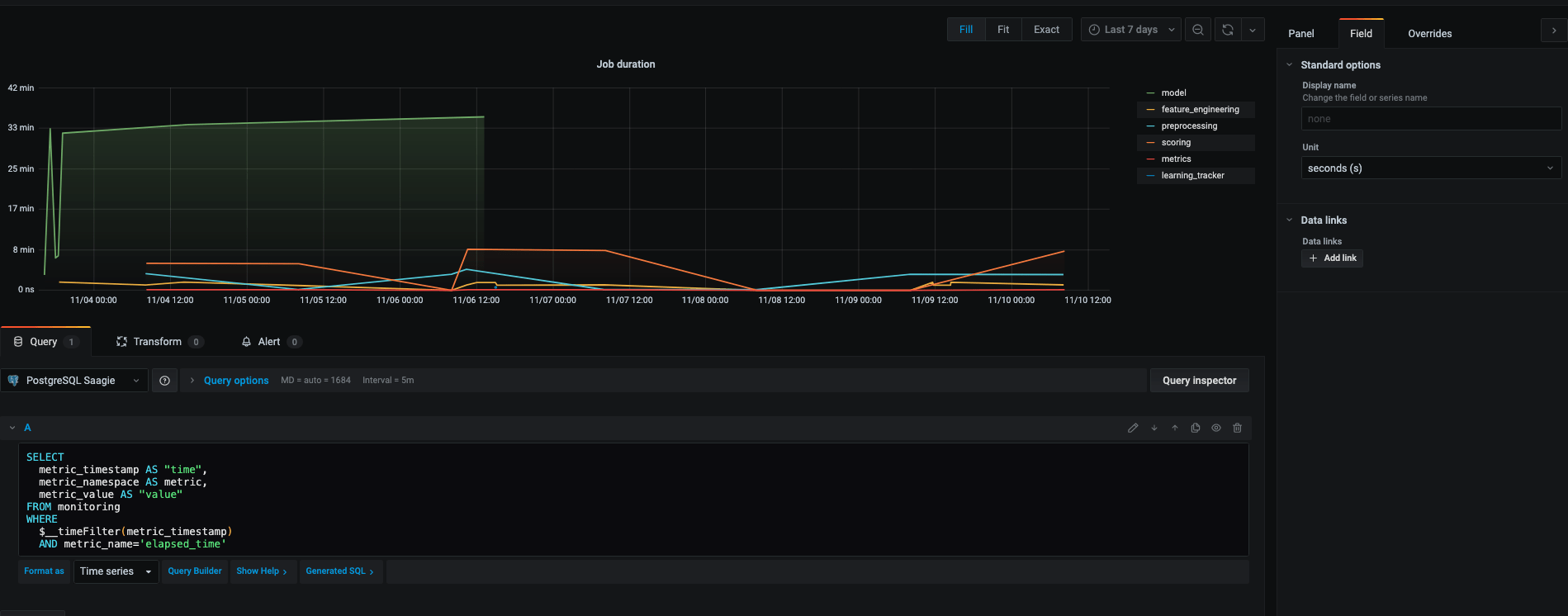
Il nous a été facile ensuite d’itérer pour y intégrer des métriques de plus en plus fines (nombre de lignes traitées / taille des fichiers en entrée…à mettre en regard des performances de chaque étape). Il suffisait pour cela d’utiliser notre fonction de logging en changeant la métrique, le namespace et la valeur préalablement calculée.
Pour ce qui est de Grafana, on voit bien ici qu’il sera très facile de répliquer ce graphe et la requête associée pour l’adapter à une autre métrique.
Attention de bien choisir la métrique que vous voulez utiliser. Nous avons insisté sur le fait qu'il fallait qu'elle soit simple à implémenter pour commencer mais il faut aussi, et surtout, qu'elle soit pertinente, qu'elle vous soit utile au quotidien. Nous avons vu trop de situations où les premières visualisations mises en place, une fois "l'effet wahou" passé, n'étaient rapidement plus utilisées, ce qui peut arriver lorsque l'accent est mis surtout sur l'esthétique et non pas sur la valeur ajoutée de chaque tableau de bord. A vous donc d'être pragmatique.
Des métriques de plus en plus poussées
Une fois les premières métriques en place, on va envisager de rentrer un peu plus dans le cœur de nos données, les briques mises en place jusqu’alors se concentrant surtout sur la surface (nombre de lignes, taille de nos datasets par exemple).
Nous avons choisi pour notre part de rajouter des traitements en entrée de notre pipeline pour y contrôler la qualité de nos données. Nous nous sommes pour cela concentrés sur les attributs clés de certains datasets pour les analyser et en faire ressortir :
- le taux moyen de complétude, qui s’obtient en calculant le nombre de valeurs vides ou nulles par rapport au nombre total de lignes
- les moyennes / médianes de certains champs qui servent de features dans notre modèle et qui y ont un poids important
- la répartition des variables catégorielles…
A posteriori, il est également pertinent de s’intéresser aux résultats en sortie du modèle. Cela nous permet de suivre, en plus des indicateurs métiers, des indicateurs sur la stabilité du modèle tels que :
- La précision (nombre de bonnes prédictions / total de prédictions)
- La matrice de confusion plus globalement (faux positifs, vrais négatifs…)
- Le score f1 qui est la moyenne harmonique de la précision et du rappel
- La courbe ROC
- Le drift (changement dans les prédictions dû aux changements dans les données)
C’est le suivi de tels indicateurs dans le temps qui permet d’évaluer la performance d’un modèle. On pourra également déclencher un réapprentissage automatique en cas de dépassement de valeurs seuils sur une ou plusieurs de ces métriques.
L'alerting
Une fois toutes ces métriques collectées et vos graphiques mis en place dans Grafana, vous aurez sûrement constaté que vous ne pouvez pas passer 24h/24 sur ces écrans de monitoring. Ce n’est pas forcément gênant pour votre projet mais dans certains cas il sera indispensable d’être le plus réactif possible et pour cela, le meilleur moyen est d’être alerté par notre stack de monitoring.
A l’heure où nous écrivons notre article, nous n’avons pas encore implémenté cette fonctionnalité sur notre projet mais nous voyons d’ores et déjà 2 solutions possibles pour la mise en œuvre.
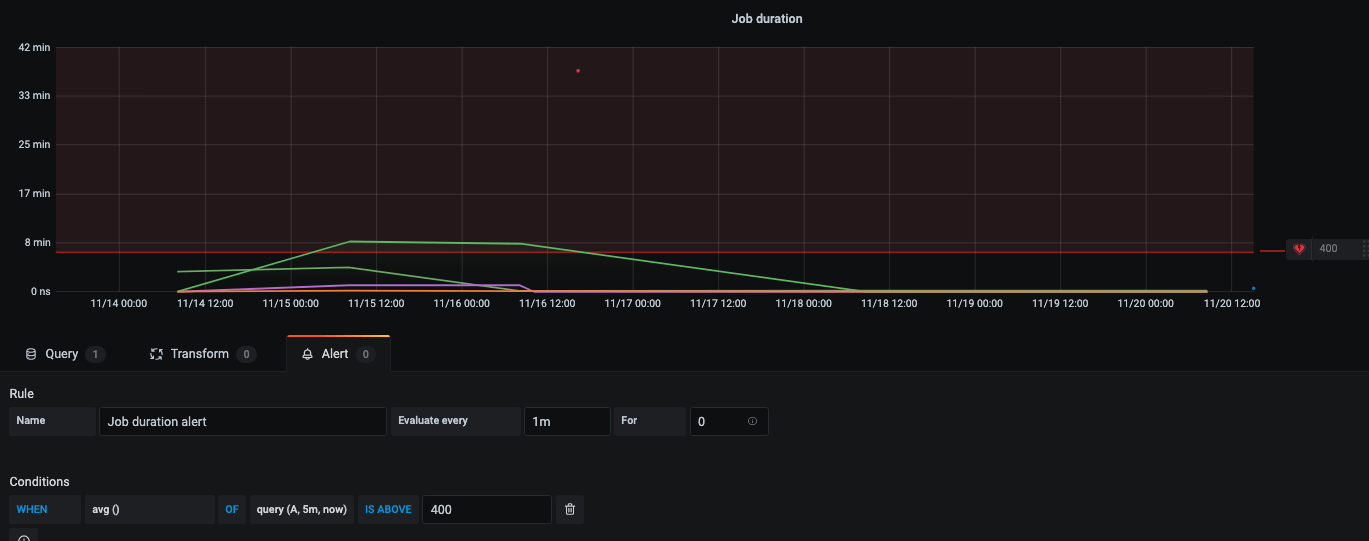
1 – S’appuyer sur les fonctionnalités d’alerting de l’outil de visualisation, en l’occurence Grafana.
Si vous disposez déjà d’un graphique qui trace votre métrique à surveiller de près et que vous souhaitez juste être alerté à partir d’un certain seuil (temps de traitement d’un batch, nombre d’erreurs 500 ou temps de réponse d’une API…), il est possible de positionner une alerte directement dans Grafana en lui indiquant :
- Le seuil : ici la durée de job maximale acceptable pour vous
- La fréquence d’évaluation : plus elle sera élevée, plus vous gagnerez en réactivité. Vous pouvez aussi indiquer à Grafana la durée pendant laquelle la valeur doit être dépassée avant d’alerter, afin d’éviter de potentiels faux positifs.
- L’action à effectuer en cas d’alerte : dans notre cas un message dans Slack mais cela aurait pu être un email, un hangout, un message transmis dans un Kafka…
2 – Le faire manuellement, en scannant périodiquement nos tables de monitoring.
En effet il se peut que l’on ait besoin de faire des calculs complexes, impossible à réaliser dans Grafana, pour décider par exemple si un modèle de ML est en train de dériver ou non (cf. paragraphe précédent). Dans ce cas, une solution peut être d’implémenter un job qui ira faire ses calculs à la fréquence désirée avant d’envoyer une alerte sur le canal de votre choix (mail, Slack…). C’est donc une solution plus fastidieuse, à garder pour les cas qui ne rentreraient pas dans le scope de votre outil de visualisation.
Encore une fois, outre l'aspect de l'implémentation technique, il sera nécessaire de bien se poser la question des alertes pertinentes à mettre en place et du seuil à partir duquel elles devront être déclenchées. Un mécanisme d'alerte qui enverrait trop de notifications aurait pour unique résultat de noyer les données utiles dans un bruit d'informations et, à l'inverse, une alerte pas assez sensible risquerait de ne jamais se déclencher, rendant tout votre travail inutile (compromis des faux positifs/faux négatifs à trouver).
Ce qu'il faut retenir
Au travers de ces différents exemples nous avons souhaité vous montrer les bonnes pratiques en terme de monitoring, que nous nous efforçons de suivre sur les différents projets data sur lesquels nous intervenons. Rappelez-vous :
Itérez
N’essayez pas de tout monitorer du jour au lendemain, laissez apparaitre les besoins au fur et à mesure. Il est tentant de vouloir collecter un peu tout et n’importe quoi en démarrant mais gardez en tête que la collecte, le stockage, l’indexation de toutes ces métriques a un coût, alors commencez par ce qui sera le plus pertinent et prioritaire pour vous.
Pensez à l'utilisateur de votre dashboard final
Un data engineer, un data scientist ou un ops n’auront pas besoin des mêmes informations. A vous de les orienter en fonction et de vous assurer que vos tableaux de bord seront effectivement utilisés (en vérifiant leurs access logs) pour éviter d’investir trop de temps sur des fonctionnalités inutiles.
Ne réinventez pas la roue
On parlait du monitoring d’un traitement Spark en introduction. La Spark UI, bien que perfectible, devrait déjà couvrir la majorité de vos besoins dans un premier temps. De la même manière, des outils de MLOps (MLFlow par exemple) fleurissent sur le marché et vous permettront sûrement de gérer plus facilement vos métriques de data science, si vous êtes prêt à intégrer ce genre d’outil dans votre stack.

Thomas Quiviger est Data Architect chez Saagie et manager de l’équipe de Data Engineers et Data Scientists. Il a travaillé pour du Big Data ou de la BI en banque d’investissement, en retail et dans l’industrie, y compris à l’international.
*Article écrit en collaboration avec Julien Fricou, Data Engineer / Data Scientist chez Saagie.





