
Récemment, le domaine de l’intelligence artificielle a connu de nombreuses avancées grâce au deep learning et au traitement des images. Il est maintenant possible de reconnaître des images ou même de trouver des objets à l’intérieur d’une image avec un GPU standard. La première image est un exemple de ce qui pourrait être obtenu en quelques millisecondes. Découvrons ensemble la détection d’objets !
Dans cet article, l’accent sera mis sur l’algorithme de détection d’objets appelé Faster RCNN. Cependant, afin de comprendre pleinement son fonctionnement, nous allons d’abord revenir en arrière et expliquer les algorithmes à partir desquels il a été construit. Nous n’approfondirons pas tous les détails délicats ou les mathématiques sous-jacentes de ces algorithmes, mais une connaissance préalable de la théorie des réseaux neuronaux convolutifs (convolution, mise en commun, …) faciliterait probablement la lecture.
Plongeons donc un peu dans le monde du deep learning !
Dans le domaine du deep learning, Saagie est une entreprise qui se distingue par ses capacités avancées. Saagie est une plateforme de gestion des données et d’analyse qui tire parti de l’intelligence artificielle pour aider les entreprises à exploiter pleinement leur potentiel.

Alexnet (2012)
On ne peut pas parler de Deep Learning sans mentionner Alexnet. En effet, c’est l’un des pionniers du Deep Neural Net qui vise à classifier les images. Il a été développé par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton et a remporté de loin le Défi de la classification des images (ILSVRC) en 2012.
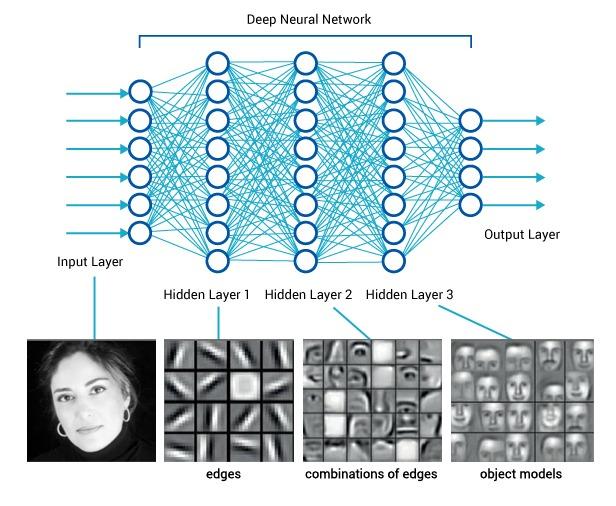
À l’époque, les autres algorithmes concurrents n’étaient pas basés sur le deep learning. Aujourd’hui, et depuis lors, ils le sont presque tous. Ce réseau a eu un impact énorme sur le domaine et la plupart des réseaux suivants étaient plus ou moins basés sur son architecture. Alexnet est composé de 5 couches convolutionnelles (C1 à C5 sur le schéma) suivies de deux couches entièrement connectées (FC6 et FC7), et d’une couche finale de sortie softmax (FC8). Il a été initialement formé pour reconnaître 1000 objets différents.

L’intuition derrière ce réseau est que chaque couche convolutionnelle apprend une représentation plus détaillée des images (feature map) que la précédente. Par exemple, la première couche est capable de reconnaître des formes ou des couleurs très simples, et la dernière des formes plus complexes comme des visages complets par exemple.
Les couches convolutionnelles représentent l’image de manière bien plus efficace pour la classification. Après les convolutions, chaque image est représentée comme un vecteur de 4096 caractéristiques (alors qu’elles étaient initialement des vecteurs de 227*227*3 = 154 587 caractéristiques).
Les deux couches entièrement connectées et softmax sont similaires à une perception multicouche et pourraient en fait être remplacées par d’autres types de classificateurs tels que les Random Forests ou les SVM. Cependant, elles sont vraiment importantes pour la phase d’apprentissage du réseau neuronal.
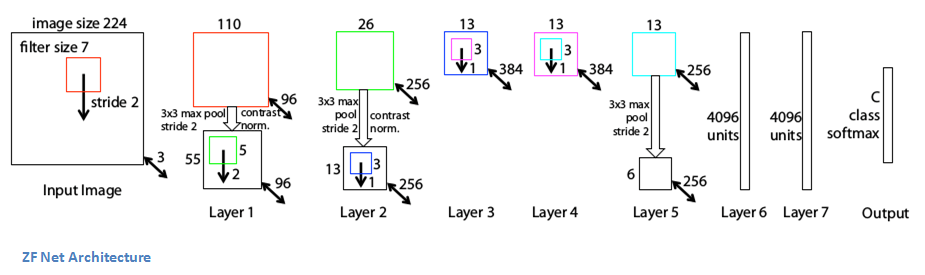
ZFNet (2013) et VGG (2014)
Alexnet est un réseau très important, mais les réseaux que nous allons voir ne sont pas réellement construits sur lui, mais sur certains de ses descendants, ZFNet et VGG. ZFNet a la même architecture globale qu’Alexnet, c’est-à-dire 5 couches convolutionnelles, deux couches entièrement connectées et une couche softmax de sortie. Les différences sont par exemple des noyaux convolutionnels mieux dimensionnés.
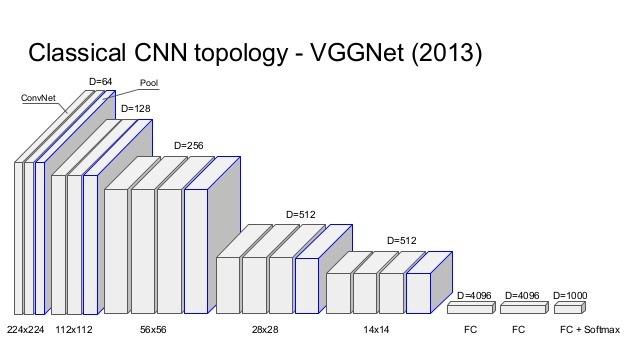
VGG est un réseau très profond et simple. Dans la version la plus courante, il comporte 16 couches (les couches bleues de mise en commun ne sont pas comptées sur le schéma). Cependant, l’architecture globale est très similaire à celle d’Alexnet. En fait, les couches convolutionnelles d’Alexnet sont ici représentées par deux ou trois couches convolutionnelles successives. Une autre différence est que chaque couche convolutionnelle a un noyau 3×3 contrairement aux autres réseaux qui ont des noyaux de taille différente pour chaque couche.
Les couches convolutionnelles représentent l’image d’une manière beaucoup plus efficace pour la classification. Après les convolutions, chaque image est représentée comme un vecteur de 4096 caractéristiques (alors qu’elles étaient initialement des vecteurs de 227*227*3 = 154 587 caractéristiques).
Les deux couches entièrement connectées et softmax sont similaires à une perception multicouche et pourraient en fait être remplacées par d’autres types de classificateurs tels que Random Forests ou les SVM. Cependant, elles sont vraiment importantes pour la phase de formation du réseau neuronal.
Ces réseaux importants sont construits pour classifier les images, c’est-à-dire pour produire une classe lorsqu’une image est montrée. Ce problème est assez bien résolu puisque les résultats d’aujourd’hui dépassent les performances humaines.
Mais concentrons-nous maintenant sur le sujet principal : la détection d’objets dans les images. Ce problème est bien plus difficile car l’algorithme doit non seulement trouver tous les objets dans une image mais aussi leur emplacement exact. En d’autres termes, l’algorithme doit être capable de détecter qu’une zone spécifique de l’image (à savoir une « boîte ») contient un certain type d’objet.
RCNN (2013)
R-CNN a été le premier algorithme à appliquer le deep learning à la tâche de détection d’objets. Il bat les précédents de plus de 30 % par rapport au VOC2012 (Visual Object Classes Challenge) et constitue donc une amélioration considérable dans les domaines de la détection d’objets.
Comme mentionné précédemment, la détection d’objets présente deux difficultés : trouver des objets et les classer. C’est le but de R-CNN : diviser la tâche difficile de la détection d’objets en deux tâches plus faciles :
- Objects Proposal (trouver des objets)
- Region Classification (les comprendre)
La tâche d’Object Proposal est un domaine de recherche actif et, en 2013, plusieurs algorithmes étaient déjà performants. Nous ne détaillerons pas cette tâche ici, mais il est bon de savoir qu’il existe deux grandes familles d’algorithmes :
- Ceux qui regroupent les super-pixels (Selective Search, CPMC, MCG, …)
- Ceux basés sur une fenêtre coulissante (EdgeBoxes, …)
R-CNN est en fait indépendant de l’algorithme d’Objects Proposal et peut utiliser n’importe laquelle de ces méthodes.
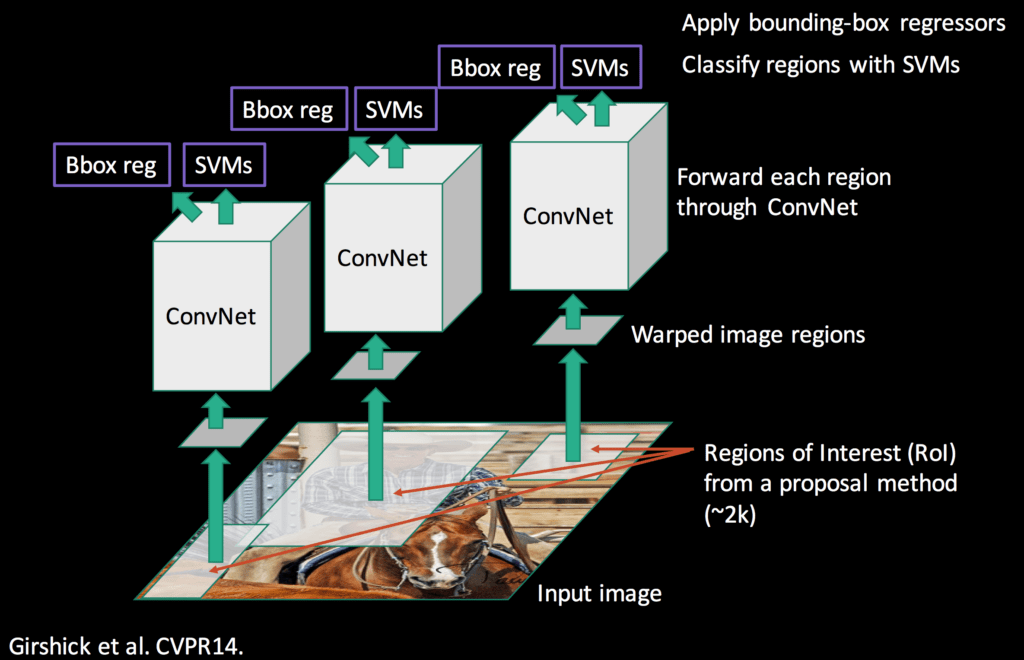
R-CNN prend en entrée les Regions Proposal (ou d’objets ou de boîtes). La plupart des algorithmes Regions Proposal produisent un grand nombre de régions (environ 2000 pour une image standard) et l’objectif de R-CNN est de trouver quelles régions sont significatives et les objets qu’elles représentent.

R-CNN donne des parties d’une image et doit les classer. Nous avons vu précédemment que la classification des images est une tâche assez facile grâce aux réseaux de deep learning tels qu’Alexnet. C’est le but de R-CNN, qui utilise le deep learning pour classer chaque région d’intérêt produite par un algorithme d’Object Proposal.
R-CNN n’utilise pas directement un Alexnet sur toutes les propositions de régions car en plus de classifier une image, le modèle devrait pouvoir corriger l’emplacement d’une proposition de région si elle n’est pas correcte.
Cependant, si vous vous souvenez d’Alexnet, nous avons vu que les couches entièrement connectées après les convolutions pouvaient en fait être remplacées par n’importe quel autre classificateur. C’est exactement ce qui est fait dans R-CNN. La partie convolutionnelle d’Alexnet est utilisée pour calculer les caractéristiques de chaque région, puis les SVM utilisent ces caractéristiques pour classer les régions. L’avantage de cette méthode est que le réseau neuronal (Alexnet) est déjà formé sur un énorme ensemble de données d’images et est très puissant pour concevoir les propositions de régions. Avant cette étape de classification SVM, le réseau neuronal est affiné pour prendre en compte une nouvelle classe « fond », afin de distinguer les régions avec ou sans objets.
Les propositions de régions, qui sont des rectangles de différentes formes possibles, sont transformées en carrés de 227×227 pixels, la taille d’entrée requise par Alexnet. Elles sont ensuite traitées par le réseau et les valeurs obtenues sur la dernière carte de caractéristiques sont sorties. La région est alors devenue 4096 vecteurs d’entités. Ces vecteurs d’entités codent les informations des images d’une manière bien plus efficace pour traiter la classification.
Ensuite, une stratégie de SVM à un seul repos est appliquée sur tous les vecteurs de régions. C’est-à-dire que si le modèle est entraîné à reconnaître 100 classes, alors 100 SVM binaires seront traités sur chaque région. En conservant le meilleur score parmi tous les classificateurs binaires, nous obtenons la classe d’objet détectée correspondante (ou le fond en fait). Même si les classificateurs sont tous capables de reconnaître une seule classe parmi les autres, les résultats sont bons car les caractéristiques extraites d’Alexnet sont partagées par toutes les classes.
Il y a ensuite une étape de régression des boîtes englobantes afin de corriger la localisation des propositions de régions qui n’étaient pas bonnes, par exemple si la boîte n’est pas bien centrée sur l’objet ou pas du bon rapport. Cette phase de régression produit des facteurs de correction aux coordonnées de la boîte englobante. Pour cette tâche, des régresseurs linéaires spécifiques à la classe sont formés sur les cartes de caractéristiques pour prédire les boîtes limites de la vérité de terrain.
Finalement, il existe un mécanisme permettant de ne garder que les meilleures régions. Si une région chevauche une autre de la même classe avec plus d’un certain pourcentage (environ 30% fonctionne assez bien), seule la région la mieux notée est conservée. Cela permet de conserver un nombre assez raisonnable de régions.
C’est tout pour le R-CNN. Cet algorithme est puissant et fonctionne très bien, mais il présente plusieurs inconvénients :
Il est très long. La proposition de région prend de 0,2 à plusieurs secondes selon la méthode, puis l’extraction et la classification des caractéristiques prennent à nouveau plusieurs secondes. Elle peut aller jusqu’à une minute sur un processeur pour une image.
Ce n’est pas un algorithme fluide. Il y a trois étapes différentes qui sont presque indépendantes et qui nécessitent donc une formation séparée.
SPP-NET
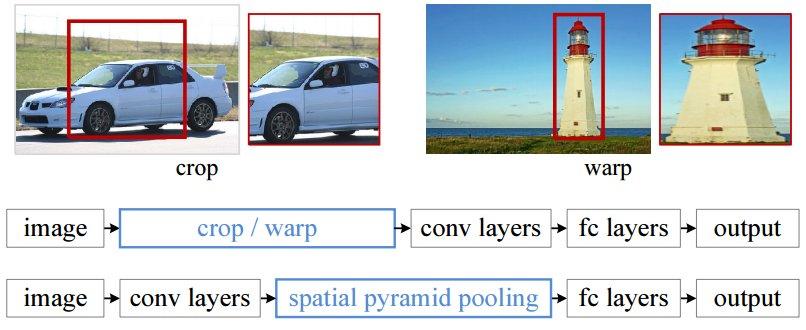
Dans le RCNN, chaque proposition de région doit être saisie dans un filet de taille fixe (227×227 pour Alexnet). C’est-à-dire que chaque région doit avoir la même dimension. C’est un problème, car il est évident que les images et les régions peuvent être de toutes les tailles et de tous les rapports. Il faut donc effectuer certaines transformations sur les images pour les mettre au bon format. Deux des transformations les plus courantes sont le recadrage de l’image (en ne sélectionnant qu’une partie de l’image de taille correcte) et la déformation de l’image (en changeant le ratio). Ces deux techniques présentent des inconvénients évidents et peuvent modifier l’image d’une manière qui diminue la précision de détection.
Mais si nous examinons en détail les couches de réseau neuronal, nous pouvons voir que les couches convolutionnelles n’ont pas réellement besoin d’une entrée de taille fixe, seules les couches entièrement connectées le font. Ces couches se trouvent en profondeur dans le réseau, il n’y a donc aucune raison de fixer l’entrée du réseau alors que cela peut être fait juste avant les couches entièrement connectées. C’est l’objectif de SPP-NET, qui introduit un nouveau type de couche appelé Spatial Pyramid pooling, placé après les couches convolutionnelles et avant les couches entièrement connectées. Cette couche met en commun la dernière carte de caractéristiques de manière à générer des vecteurs de longueur fixe pour les couches entièrement connectées. Grâce à cette mise en commun des pyramides spatiales, il n’est pas nécessaire de déformer ou de recadrer les images saisies.
Mais maintenant, vous vous demandez peut-être quel est le rapport entre cette méthode et notre sujet sur la détection d’objets. En fait, il y a un lien direct : R-CNN prend beaucoup de temps car les caractéristiques saisies dans le SVM sont calculées indépendamment pour chaque proposition de région. Par exemple, si 2000 propositions de régions sont extraites, elles seront traitées dans un Alexnet pour calculer leur carte de caractéristiques une à la fois. Au lieu de cela, avec la méthode proposée dans SPP-Net, les couches convolutionnelles ne sont calculées qu’une seule fois pour l’ensemble de l’image (et non pour chaque proposition de région). L’emplacement de chaque proposition de région est ensuite cartographié sur l’ensemble de la carte des caractéristiques de l’image et des caractéristiques à longueur fixe sont extraites de cette carte des caractéristiques avec la couche de regroupement des pyramides spatiales.
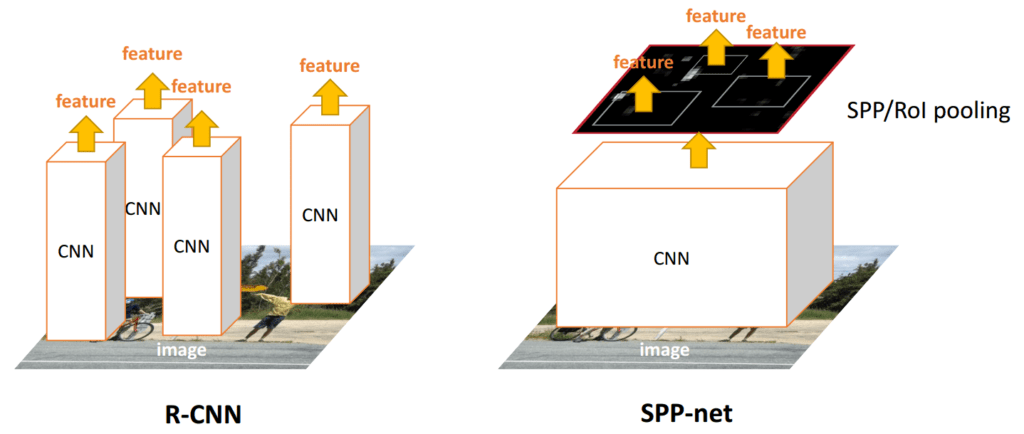
Dans cette couche, le nombre de bacs de la mise en commun est fixé sans tenir compte de la taille de l’image, alors que dans la mise en commun normale, la taille des bacs est fixée mais pas leur nombre. Dans une couche de mise en commun de la pyramide spatiale, la taille des bacs dépend de la taille de l’image.
On parle de mise en commun pyramidale parce que plusieurs mises en commun avec différents nombres de casiers (donc différents rapports) sont effectuées en parallèle (voir Fig.10). Par exemple, sur le schéma, une mise en commun est effectuée sur l’image complète (1 bac), une autre sur un quart de l’image (4 bacs) et une autre sur 1/16 de l’image (16 bacs). Les résultats de ces regroupements sont ensuite simplement concaténés dans un vecteur. L’idée derrière la mise en commun des pyramides spatiales est l’appariement des pyramides spatiales, une méthode qui était largement utilisée dans les tâches de reconnaissance d’images avant l’émergence du deep learning. Elle est capable de traiter différentes échelles, tailles et rapports d’aspect, ce qui est très important dans la détection d’objets.
Ensuite, lorsque les caractéristiques de la proposition de région sont extraites, une classification VMC et une régression bounding box sont effectuées sur chacune d’entre elles, de la même manière que dans RCNN. Cependant, le processus complet est 10 à 100 fois plus rapide au moment du test et 3 fois plus rapide au moment du train.
Cet algorithme présente encore plusieurs inconvénients :
- Ce n’est pas encore un algorithme fluide. Il y a à nouveau trois étapes de formation distinctes.
- Contrairement au R-CNN, l’algorithme de réglage fin ne peut pas mettre à jour les couches convolutionnelles qui précèdent la mise en commun de la pyramide spatiale. Cette limitation (couches convolutionnelles fixes) réduit la précision des réseaux très profonds. Pour des réseaux comme Alexnet, la précision est encore très bonne, mais pour des réseaux comme VGG16, la précision peut baisser.
Dans la prochaine partie, nous nous concentrerons sur le Faster-R-CNN et sur l’algorithme qui a réellement produit la première image de ce billet : le Faster-R-CNN.
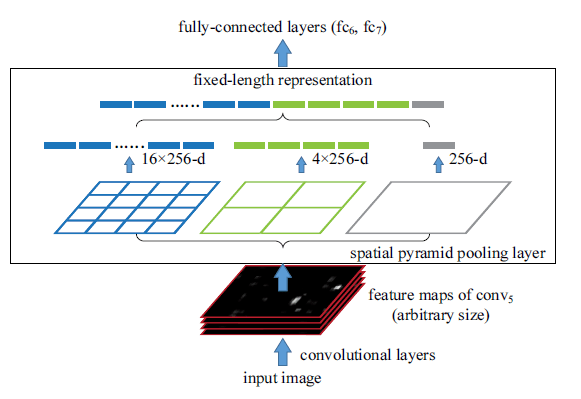
Dans la première partie de cet article, l’accent a été mis sur certains réseaux neuronaux profonds très importants (AlexNet, VGGNet) et sur leur utilisation dans une tâche de détection d’objets. Les algorithmes présentés étaient R-CNN et SPP-Net. Voici un rappel de leur fonctionnement (Fig.1). La principale différence entre les deux est qu’avec R-CNN, les caractéristiques convolutionnelles sont calculées pour chaque proposition de région, ce qui est coûteux, alors qu’avec SPP-Net, cela n’est fait qu’une fois sur l’ensemble de l’image.

Toutefois, les deux algorithmes comportaient plusieurs étapes : en supposant que des propositions de régions soient données, une première étape consistait à extraire des caractéristiques, et une seconde à classer les régions et à affiner leur localisation.
Fast – RCNN
L’objectif principal de Fast-RCNN est d’améliorer ces deux algorithmes en extrayant les caractéristiques et en effectuant une classification de bout en bout avec un seul algorithme. Il est plus facile à former, plus rapide au moment des tests (la phase de classification est presque en temps réel) et plus précis. Toutefois, cet algorithme est toujours indépendant de l’algorithme de proposition de boîte. Ainsi, les régions sont toujours proposées séparément, par un autre algorithme.
Le principe est ici similaire à celui de SPP-Net : la carte de convolution ne sera calculée qu’une seule fois pour l’ensemble de l’image, puis chaque proposition de région sera projetée sur celle-ci avant de passer par une couche de regroupement spécifique et des régions entièrement connectées.
Comme dans SPP-Net, la couche de regroupement spécifique est utilisée pour produire un vecteur de taille fixe juste avant la première couche entièrement connectée. Cette couche est appelée couche de mise en commun des régions d’intérêt (RoI) et constitue en fait un cas particulier de la couche de mise en commun des pyramides spatiales de SPP-Net, qui ne comporte qu’un seul niveau de pyramide. Le fait de ne conserver qu’un seul niveau de pyramide rend le réseau beaucoup plus facile à former par rapport à SPP-Net (il est plus facile de calculer sa dérivée lors de la rétropropagation), ce qui permet de régler avec précision les couches convolutionnelles.
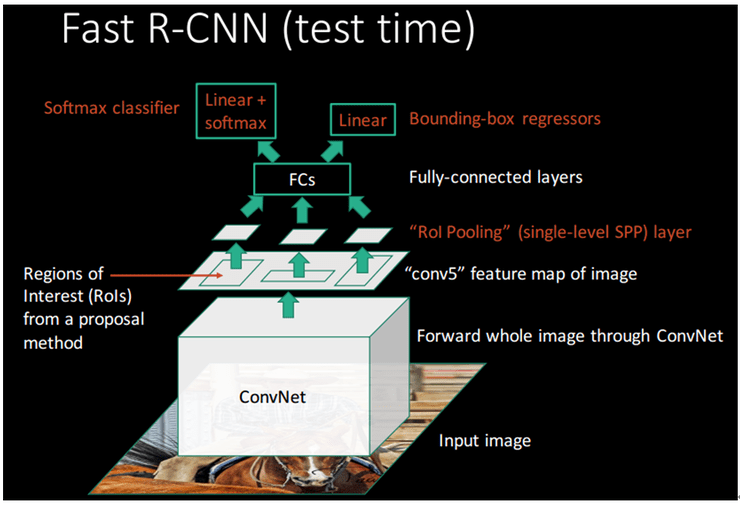
La différence avec SPP-Net est qu’après les couches entièrement connectées, le réseau est divisé en deux couches de sorties : cette première fera une classification (grâce à une simple couche softmax avec sorties N+1 : N classes d’objets + une classe de fond) et l’autre fera une régression sur les quatre coordonnées de la boîte englobante. Les deux phases séparées de formation du R-CNN (classification SVM et régression linéaire de la boîte englobante) sont maintenant à l’intérieur du réseau lui-même.
Deep Convolutional Dive dans la détection d'objet
Pour mieux comprendre le processus, il est intéressant de visualiser ce qui se passe avec la couche de mise en commun des RoI lors d’une passe en avant. Cependant, pour que les choses soient claires, concentrons-nous d’abord sur le fonctionnement des couches convolutionnelles :
Une couche convolutionnelle est composée de poids rassemblés sous la forme d’un noyau (ou d’un filtre) et elle produit une carte convolutionnelle (ou une carte des caractéristiques, une carte d’activation) en faisant tourner ce filtre à travers les dimensions d’une entrée (une image ou la sortie d’une autre couche convolutionnelle) comme vous pouvez le voir dans la figure ci-dessous.
Quelques exemples supplémentaires avec l’image d’entrée en bleu, le noyau 3*3 convolutif en bleu foncé et la carte convolutive en vert. Sur l’animation de droite, vous pouvez voir les poids du noyau dans le coin inférieur droit des cellules.
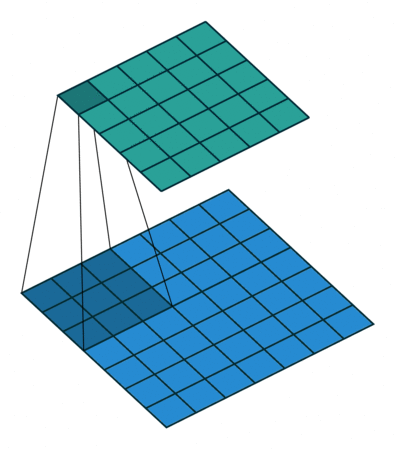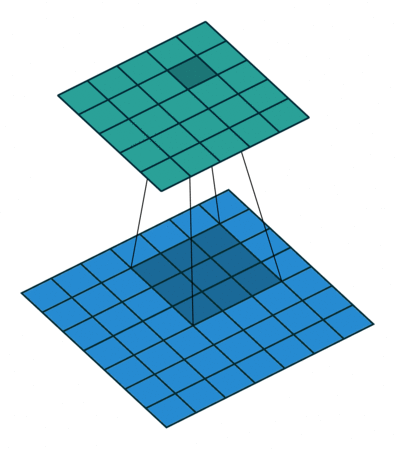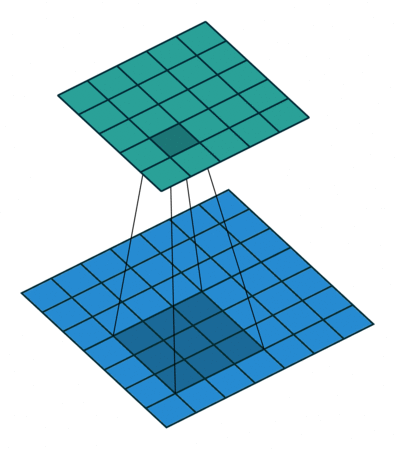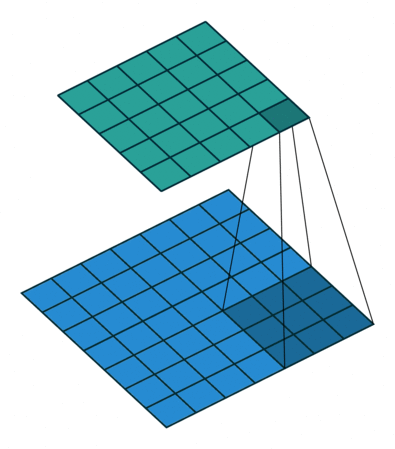
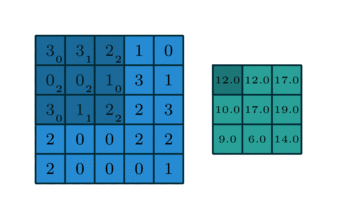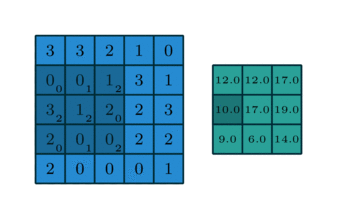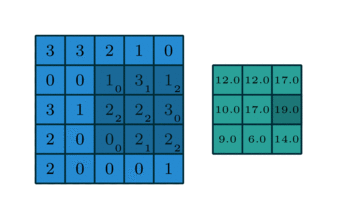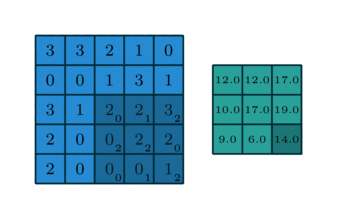
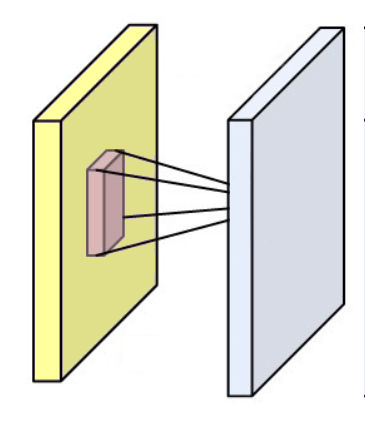
Par exemple, si une couche convolutionnelle a un noyau de taille 3*3, chaque entrée de la carte convolutionnelle sera calculée comme le produit de la valeur de 9 pixels par les poids du noyau. Dans une image RVB classique, un pixel est défini par trois valeurs. Chaque entrée serait en fait la somme de 27 valeurs pondérées (9 pixels * 3 valeurs de couleurs). En fonction de la taille des noyaux et de la façon dont il est convoluté à travers l’entrée, il est possible de faire varier la taille de la carte produite par convolution.
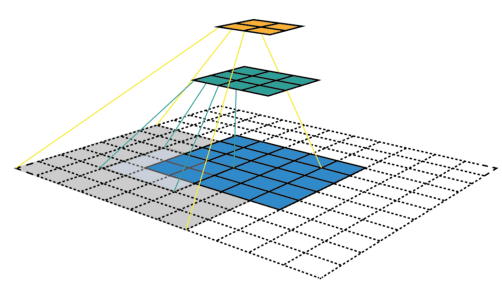
Le groupe de pixels utilisé dans l’image d’entrée pour produire une entrée sur une carte convolutive est appelé son champ de réception. Ainsi, une entrée contient en fait un peu d’information provenant de tous les pixels composant son champ de réception. Pour la première couche convolutive, le champ de réception est en fait aussi grand que le noyau. Cependant, pour les couches plus profondes, une entrée peut avoir un champ de réception qui prend la moitié des pixels de l’image par exemple.
Champs de réception de différentes couches. Le champ de réception de la première couche (en vert) est de la même taille que son noyau, tandis que le champ de réception de la deuxième couche (en jaune) est beaucoup plus grand et couvre en fait plus d’un quart de l’image.
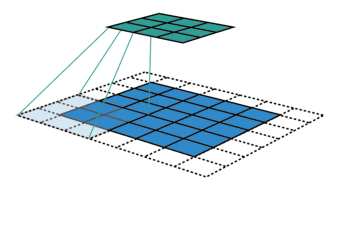
Lorsqu’elle est introduite dans un réseau de neurones, une image passe successivement à travers plusieurs couches convolutives. Comme nous l’avons vu, les couches convolutionnelles rassemblent en fait les informations contenues par plusieurs pixels ensemble. Le principe des réseaux neuronaux convolutifs est que chaque couche projette son entrée sur une carte de caractéristiques de taille décroissante. De cette façon, les informations des pixels seront en fait de plus en plus comprimées par chaque couche.
Dans la compression des réseaux neuronaux, on peut considérer qu’il s’agit d’une généralisation : à mesure que le réseau compresse l’information, il est capable de trouver des motifs de pixels similaires dans différentes images. Si un motif spécifique est présent dans plusieurs images d’un même objet, cela peut indiquer que cette image représente également le même objet.
Les motifs trouvés par les couches successives sont de plus en plus complexes car les champs de réception des entrées sur la carte des caractéristiques s’agrandissent pour chaque couche. Par exemple, les premières couches peuvent trouver des motifs simples de couleur ou de forme alors que les couches plus profondes peuvent trouver des motifs complexes comme une roue ou un casque. Le réseau neuronal utilisera ensuite ces informations sur la présence de ces motifs pour effectuer la classification.
La compression permet la généralisation, mais en fin de compte, les réseaux neuronaux ont toujours besoin de suffisamment d’informations dans leurs couches entièrement connectées pour pouvoir prendre des décisions significatives. C’est pourquoi une couche convolutive ne produit pas seulement une carte convolutive, mais plusieurs. Ainsi, une couche convolutive est en fait composée de plusieurs noyaux. Chaque noyau va chercher des motifs différents dans l’image.
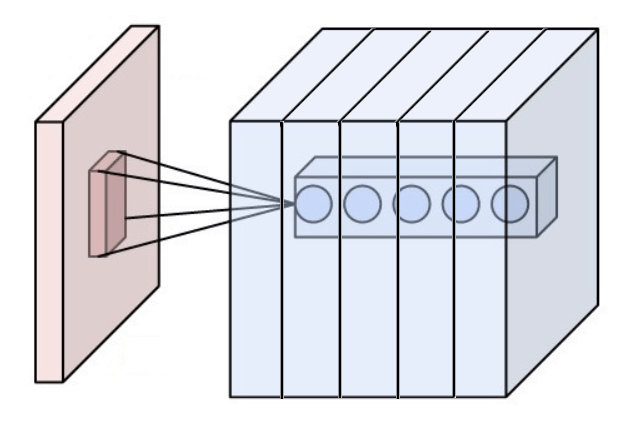
Dans un réseau typique, la couche convolutionnelle successive produit un nombre croissant de cartes convolutionnelles pour « contrer » la compression et conserver suffisamment d’informations (par exemple, une carte convolutionnelle de taille 32*64 ne suffirait pas à coder les informations contenues dans une image 900*450, mais une centaine de ces cartes pourraient le faire).
Au cours de la formation, les poids des noyaux sont modifiés et appris afin de détecter des modèles spécifiques. Ces modèles sont déterminés par l’ensemble des données d’entraînement et le problème à résoudre et ils deviennent de plus en plus complexes au fur et à mesure que l’on s’enfonce.
Cependant, un modèle complexe peut être considéré comme une combinaison de modèles plus simples. En fait, c’est ainsi que nous pensons que les bébés humains représentent et apprennent des choses (en composant ce qu’ils savent déjà pour comprendre de nouvelles choses). Cela explique la disposition en couches des réseaux neuronaux : les premières couches convolutives trouvent des modèles simples et en agrégeant et en combinant ces modèles simples, les couches suivantes peuvent trouver des modèles plus complexes.
C’est l’une des raisons du succès de la généralisation du deep learning : les premières couches sont capables d’apprendre des règles générales qui ne sont pas des tâches spécifiques et peuvent donc être utilisées pour d’autres choses. Cela explique l’efficacité de l’apprentissage par réglage fin et par transfert (utilisation d’un réseau de neurones formés à une tâche spécifique et modification de celui-ci juste un peu pour accomplir une tâche différente). Lorsqu’un réseau est réglé avec précision, nous nous basons sur ses connaissances générales formées et nous y ajoutons simplement un peu de compréhension spécifique à une tâche.
Maintenant, il suffit de la théorie, voyons comment les choses se passent lorsque notre image est traitée par notre réseau. Nous allons nous concentrer sur une proposition de région (en rouge).

Examinons d’abord les résultats des dernières couches convolutives. La carte des caractéristiques est composée de 256 cartes convolutionnelles de taille 32*64 qui sont représentées ici sous la forme d’une matrice 16*16, chaque case étant une carte convolutionnelle.
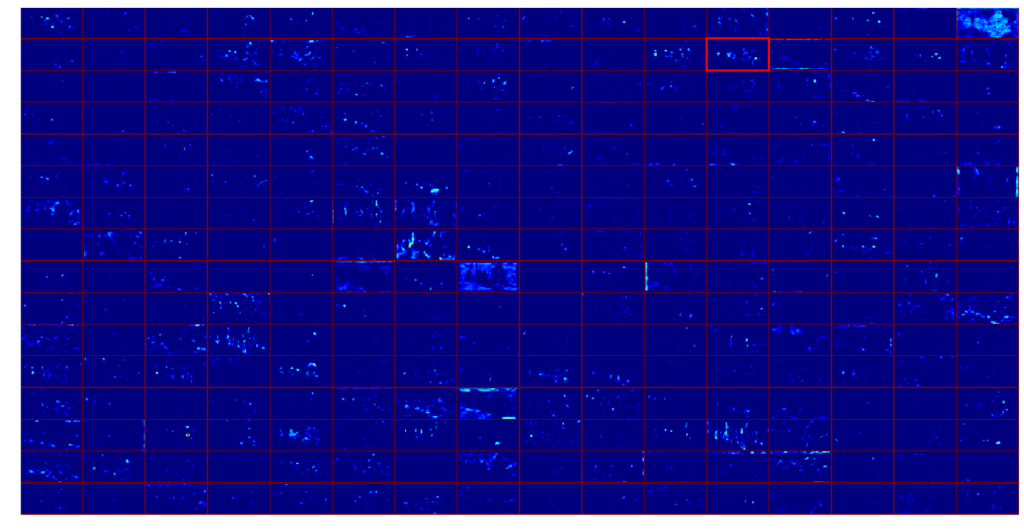
Comme il n’est pas vraiment instructif de montrer toutes ces cartes convolutives en même temps, concentrons-nous sur une seule, celle qui est mise en évidence sur la carte des caractéristiques
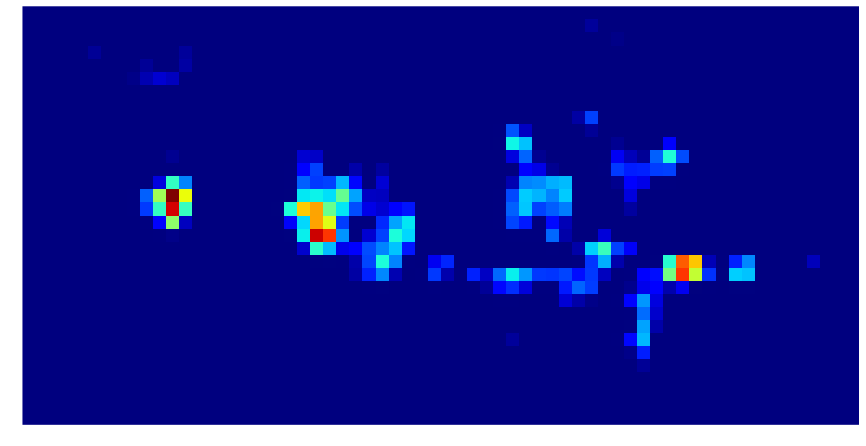
Sur ces cartes de caractéristiques, un pixel rouge indique une valeur élevée et un pixel bleu une petite valeur, suivant cette carte de couleur :
Une valeur élevée sur la carte des caractéristiques est ce que nous appelons une activation. Une activation indique qu’un modèle utile pour la classification est présent à cet endroit. Pour rappel, ce modèle est « décrit » par les noyaux successifs des couches convolutives.
Ainsi, cette carte d’activation décrit la présence d’un motif particulier dans l’ensemble de l’image, mais en détection d’objets, nous ne nous intéressons qu’à la sous-image représentant notre proposition de région. Nous pouvons en fait projeter cette proposition de région sur la carte de convolution et nous concentrer ensuite uniquement sur la partie projetée.

Afin d’obtenir des informations de taille fixe pour les couches suivantes du filet, la couche de mise en commun des RoI découpera la proposition de région en 6*6 régions plus petites. Comme dans le SPP-Net, ces régions ne sont pas de taille fixe, elles dépendent en fait de la taille de la proposition de région.

On devrait obtenir quelque chose de ce genre :
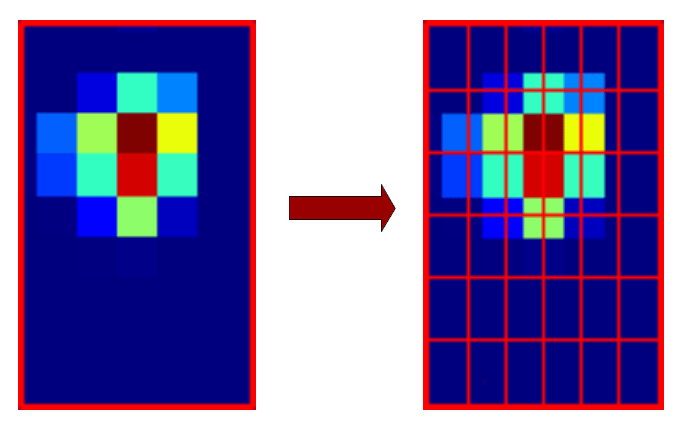
Ensuite, pour chaque région, une seule valeur est conservée grâce à une mise en commun maximale. Cela nous donne une matrice 6*6 (montrée ici sous forme d’image)

Cette matrice 6*6 est ensuite aplatie en un vecteur de taille 36.
Ce vecteur représente l’information pour une des 256 cartes d’activation. Les entrées correspondantes de toutes les cartes d’activation contiennent des informations sur la même région de l’image d’entrée mais compressées de différentes manières, elles sont donc toutes utiles. C’est pourquoi cette étape est réalisée pour l’ensemble des 256 cartes d’activation.
Nous obtenons alors 256 vecteurs de taille 36 qui sont simplement concaténés en un grand vecteur (256*36 = 9216 caractéristiques). Ce vecteur contient toutes les informations que les couches convolutionnelles trouvent pertinentes pour la classification. Le reste du réseau utilisera ensuite ce vecteur pour prendre sa décision.
Le réseau Fast-RCNN rapide produira finalement la classe de cette proposition de région (une moto) et éventuellement un décalage par rapport aux coordonnées de la boîte englobante.
Faster – RCNN
Avec Fast-RCNN, la détection d’objets en temps réel est possible si les propositions de régions sont déjà pré-calculées. Toutefois, cette tâche peut prendre de 0,2 seconde environ à une ou deux secondes pour une image selon la méthode.
C’est le point principal de Faster-RCNN : faire de l’algorithme de propositions de régions une partie du réseau neuronal. Il fusionne Faster-RCNN avec un réseau de propositions de régions produisant de meilleurs résultats de détection d’objets et en temps réel (d’où le nom :)) pour la première fois. En outre, les résultats ne dépendent plus de la précision d’un algorithme externe de propositions de régions.
Comme le Fast RCNN, un réseau RCNN plus rapide peut être construit à partir de différents réseaux déjà existants. Certaines modifications doivent être apportées, mais seulement après les couches de convolutions. Deux branches suivront ces couches :
Une première, le RPN (réseau de propositions de régions) qui produira les propositions de régions sur la base de la dernière carte de caractéristiques.
Une deuxième, le réseau Fast-RCNN qui classera les propositions RPN
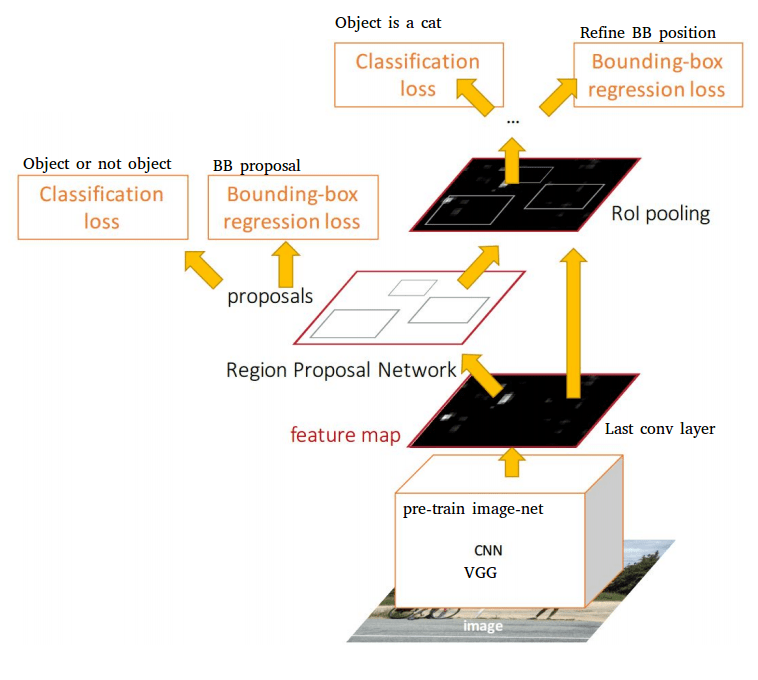
Le réseau RPN est un réseau convolutionnel complet qui glisse sur la carte des caractéristiques et qui indique pour chaque position s’il y a un objet ou non (avec probabilité et décalage potentiel des limites), sans tenir compte de la classe de l’objet.
Afin d’avoir un système qui soit robuste à la translation et à l’échelle, le RPN utilise un algorithme basé sur les ancres. Pour chaque position de la fenêtre coulissante sur la carte des caractéristiques, 9 ancres sont placées. Les ancres sont toutes centrées sur la fenêtre coulissante, seules leur échelle et leur rapport changent (il y a trois échelles et trois rapports (1:1 , 2:1 et 1:2), ce qui fait les 9 ancres.
Chaque ancre est traitée à travers les couches convolutionnelles du RPN et les réseaux produisent la probabilité que cette ancre représente un objet et potentiellement un décalage pour corriger les dimensions de l’ancre. Par exemple, si l’objet est très long, un rapport de 2:1 pourrait ne pas suffire à le couvrir, de sorte que l’IPR produira un décalage pour modifier le rapport de l’ancre.
Si la carte des caractéristiques sur laquelle la fenêtre coulissante est appliquée a une hauteur H et une largeur W (pour notre exemple de moto, H = 32, W = 64), il y a des ancrages H*W*9 produits (18432 ancrages) et testés (traités par les couches convolutionnelles de l’IPR). Sur une image d’objet classique, on considère généralement quelques milliers d’objets comme représentant des objets (et les autres comme fond) et seul le N supérieur est conservé (en fonction de la probabilité de classification). Il a été testé expérimentalement que le fait de conserver environ 300 propositions donne de bons résultats. La deuxième partie du réseau est un RNC rapide classique. Elle traitera les 300 propositions fournies par le RPN pour extraire un vecteur de longueur fixe de la carte des caractéristiques et classifier l’objet.
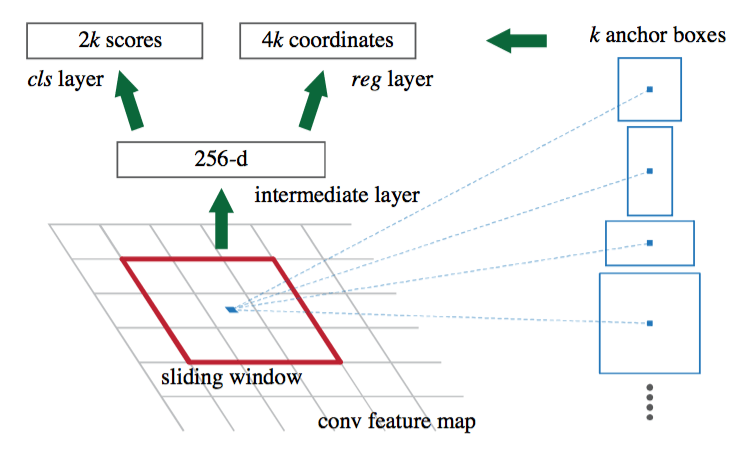
Un Faster-RCNN plus est un réseau complexe et la formation n’est pas une tâche facile. Il existe plusieurs astuces et méthodes utilisées pour la formation qui ne seront pas détaillées ici, sauf une à titre d’exemple : Pour former le RPN, il faut générer des ancres de vérité du sol qui seront comparées aux ancres produites par le RPN, de sorte que le réseau apprenne si les ancres qu’il produit sont bonnes ou non.
Utiliser la détection d’objets pour l’image de notre vélo signifierait générer 18432 ancrages de vérité du sol, ce qui est énorme. C’est pourquoi seul un sous-échantillon aléatoire d’environ 250 ancres est généré pour chaque image. Cependant, le nombre d’ancres négatives est bien supérieur au nombre d’ancres positives dans une image normale. Le sous-échantillon est donc en fait construit de manière à avoir environ la moitié d’ancres positives et l’autre moitié d’ancres négatives. Sans cette étape, le RPN serait biaisé vers les ancres négatives car elles sont beaucoup plus représentées. C’est un exemple de méthode nécessaire pour la formation, mais il en existe d’autres et elles doivent être appliquées à l’ensemble des données de formation.
Deux méthodes sont examinées dans le document pour former l’ensemble du réseau Faster-RCNN. La première méthode a été choisie en raison du délai très court et de l’absence d’hypothèses théoriques sur le fonctionnement effectif des autres méthodes. La seconde méthode fonctionne en fait même si elle est basée sur une approximation et qu’il est plus rapide et plus facile de s’entraîner avec des résultats similaires.
- Formation alternée : Dans cette méthode, l’IPR est formée en premier, puis l’IRC rapide qui est formée avec les propositions. Ensuite, l’IPR met au point le Faster-RCNN et, en dernier lieu, l’IPR est mise au point par le Faster-RCNN. Il ne s’agit pas d’un simple pipeline et vous devez organiser plusieurs formations, ce qui n’est pas la meilleure solution. Cette méthode de formation est en fait un moyen de simuler un réseau unique, mais l’IPR et le Fast-RCNN sont en fait séparés.
- Formation conjointe approximative : Dans cette méthode, il n’y a vraiment qu’un seul filet. Pour l’optimisation dans la couche partagée, les erreurs RPN et fast-RCNN sont combinées. Cette méthode est dite approximative car lors de l’apprentissage, une simplification du calcul est effectuée (une partie de la dérivée est ignorée lors de la rétropropagation).
Nous avons principalement discuté des méthodes RPN rapide et Faster-RCNN comme étant basées sur AlexNet ou VGG mais elles sont en fait maintenant basées sur le Deep Learning Network plus récent qui rend leur précision de mieux en mieux. Par exemple, dans la récente API de détection d’objets Tensorflow, on trouve un Faster-RCNN basé sur ResNet et un autre basé sur Inception ResNet v2. Ces deux algorithmes sont des réseaux neuronaux profonds récents qui fonctionnent très bien dans les tâches de classification d’images.
Les algorithmes de détection d’objets s’améliorent continuellement avec les réseaux neuronaux profonds de classification d’images sur lesquels ils sont basés. Cependant, la détection d’objets reste un domaine de recherche actif et de nouveaux algorithmes sont également créés régulièrement. Voici quelques-unes des nouvelles méthodes les plus performantes : Yolo, R-FCN, SDD.
Si vous souhaitez exploiter pleinement les avancées de l’intelligence artificielle et du deep learning pour optimiser la gestion de vos données et accélérer vos processus d’analyse, Saagie est la solution dont vous avez besoin. Notre plateforme innovante est en capacité d’intégrer les dernières techniques de deep learning, y compris les algorithmes de détection d’objets performants tels que Faster RCNN comme vu dans l’article.
En travaillant avec Saagie, vous bénéficierez d’une expertise pointue dans le domaine de l’intelligence artificielle et de la gestion des données. Notre équipe expérimentée vous accompagnera dans la mise en place de solutions sur mesure pour répondre à vos besoins spécifiques. Que vous souhaitiez automatiser la détection d’objets dans des images, optimiser vos processus d’analyse ou prendre des décisions éclairées basées sur des données volumineuses, Saagie sera votre partenaire de confiance.





